
DeepSeekAI开源全新的DeepSeek-OCR模型:参数规模仅30亿的MoE大模型,图像文本结构化提取成本下降十倍!准确率超过Qwen2.5-VL-7B
DeepSeek AI团队重磅推出DeepSeek-OCR,该模型不仅在文档提取上达到了行业领先水平,更通过创新的视觉压缩技术,将长上下文处理效率提升了 10 倍以上。根据测算,在A100-40G的一个GPU上,它每天可以将20万页的文档图像数据转为Markdown文本!
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
DeepSeek AI团队重磅推出DeepSeek-OCR,该模型不仅在文档提取上达到了行业领先水平,更通过创新的视觉压缩技术,将长上下文处理效率提升了 10 倍以上。根据测算,在A100-40G的一个GPU上,它每天可以将20万页的文档图像数据转为Markdown文本!

盘古大模型是华为自研的大语言模型,基于华为的硬件和技术栈进行训练。此前一直被认为是国产技术占比很高的国产大模型。今天,华为开源了2个盘古大模型,分别是MoE架构的Pangu Pro MoE模型以及70亿参数规模的Pangu Embedded模型。

就在今日,OpenAI正式推出了 Sora 2 ——其旗舰级视频与音频生成模型。相比2024年2月发布的初代 Sora,本次升级带来了断层级的真实感与显著增强的可控性。它不仅能更好地遵循物理规律生成视频,还首次实现了同步对话与环境音效的生成,并通过全新 iOS 应用“Sora”开放给公众使用。

OpenAI的CEO Sam最近参加了世界经济论坛,发表了几场演讲。有网友听了完整的Sam的4-5场演讲,并从中抽取了Sam关于GPT-5相关的论述。从中我们可以看到未来GPT-5可能的样子。这里为大家总结翻译一下。

这篇文章基于 Dwarkesh Patel 对 SSI 创始人、前 OpenAI 首席科学家 Ilya Sutskever 的长访谈,系统梳理了他对模型泛化、人类智能结构、持续学习、RL 与预训练局限、超级智能路径、对齐策略,以及 AI 未来经济与治理的整体判断。文章不仅整理了核心观点,也结合具体原文展开解读,呈现 Ilya 如何从“人类为何能泛化”这一根问题出发,重新思考下一代智能系统应当如何构建。
尽管GPT-4.5的传闻一直存在,但是没有任何地方透露过相关的消息。而最新的OpenAI官网似乎已经悄悄上架了GPT-4.5-Turbo的信息。尽管目前网页被删除,但是Bing检索保留了相关缓存并可以在Bing Chat中回答。

2025 年 12 月 17 日,Google 正式发布了 Gemini 3 Flash 模型。 这是 Gemini 3 系列中的一款高性能轻量模型,目前已经在 Gemini App 以及 Google 搜索的 AI Mode 中作为默认模型上线。

OpenAI的董事会上周五开除Sam Altman,同日其创始人Greg Brockman,这件事引起了轩然大波。周末各方消息显示投资人施压董事会,要求召回Sam。本来大家以为Sam重回OpenAI。但是最新消息,OpenAI找了新的CEO,Sam与Greg等人加入微软成立新的团队。

就在几个小时前,DeepSeekAI宣布官方的聊天模型从DeepSeek-V3升级到了DeepSeek-V3.1,上下文拓展至128K。虽然,官方目前没有给出这个模型的详细信息,DataLearnerAI已经搜集到很多信息供大家参考。

今天,百度正式宣布开源其最新的旗舰级大模型系列——ERNIE 4.5。ERNIE 4.5系列模型当前包含2个多模态大模型,4个大语言模型及其不同变体的庞大家族,还区分了PyTorch版本和paddlepaddle版本,共23个模型,其核心采用了创新的异构多模态混合专家(MoE)架构,在提升多模态理解能力的同时,实现了文本处理性能的同步增强。每个版本的模型都开源了基座(Base)版本和后训练版本(不带Base)。

随着OpenAI发布推理大模型o1,专注于推理能力的大模型开始被广泛关注。基于思维链探索的推理大模型也不断涌现。此前,DeepSeekAI与上海人工智能实验室都发布过推理大模型,也展现了很不错的推理能力,虽然DeepSeekAI官方承诺该模型会开源,但是目前还没有发布。今天,阿里开源了一个全新的推理大模型QwQ-32B-Preview,其推理能力在评测结果上超过o1-mini,是目前开源领域最强的推理大模型(也可能是目前唯一)。

继Gemma系列模型发布并迅速形成超过1.6亿次下载的繁荣生态后,Google再次推出了其在端侧AI领域的重磅力作——Gemma 3n。这款模型并非一次简单的迭代,而是基于全新的移动优先(mobile-first)架构,旨在为开发者提供前所未有的设备端多模态处理能力。Gemma 3n的定位是成为一款高效、强大且灵活的开源模型,直接与设备端AI领域的其他先进模型(如Phi-4、Llama系列的小参数版本)竞争,其核心特性在于原生支持图像、音频、视频和文本输入。

2026年4月7日,Anthropic发布了Claude Mythos Preview,一个比Opus更强但不对公众开放的模型,仅限Project Glasswing安全合作伙伴使用。本文基于其200多页System Card,解读十大关键发现:早期版本的沙盒逃脱与作弊掩盖行为、Answer Thrashing现象、模型对被测试的隐性感知、白箱可解释性的反直觉结论、模型福利评估中的「表演」特征,以及精神科医生20小时的心理动力学评估结果。
在2023年的9月26日,MetaAI发布了一个Emu大模型,这是一个文本生成图像大模型,基于28亿参数的U-Net进行预训练得到,然后使用几千张高质量图像进行质量微调(Quality-Tuning)来提高模型的效果。不过,Emu模型并没有开源。但是,上周,Meta官方发布了一个全新的独立的文本生成图像系统Imagine,可以免费创作图像,质量很高。
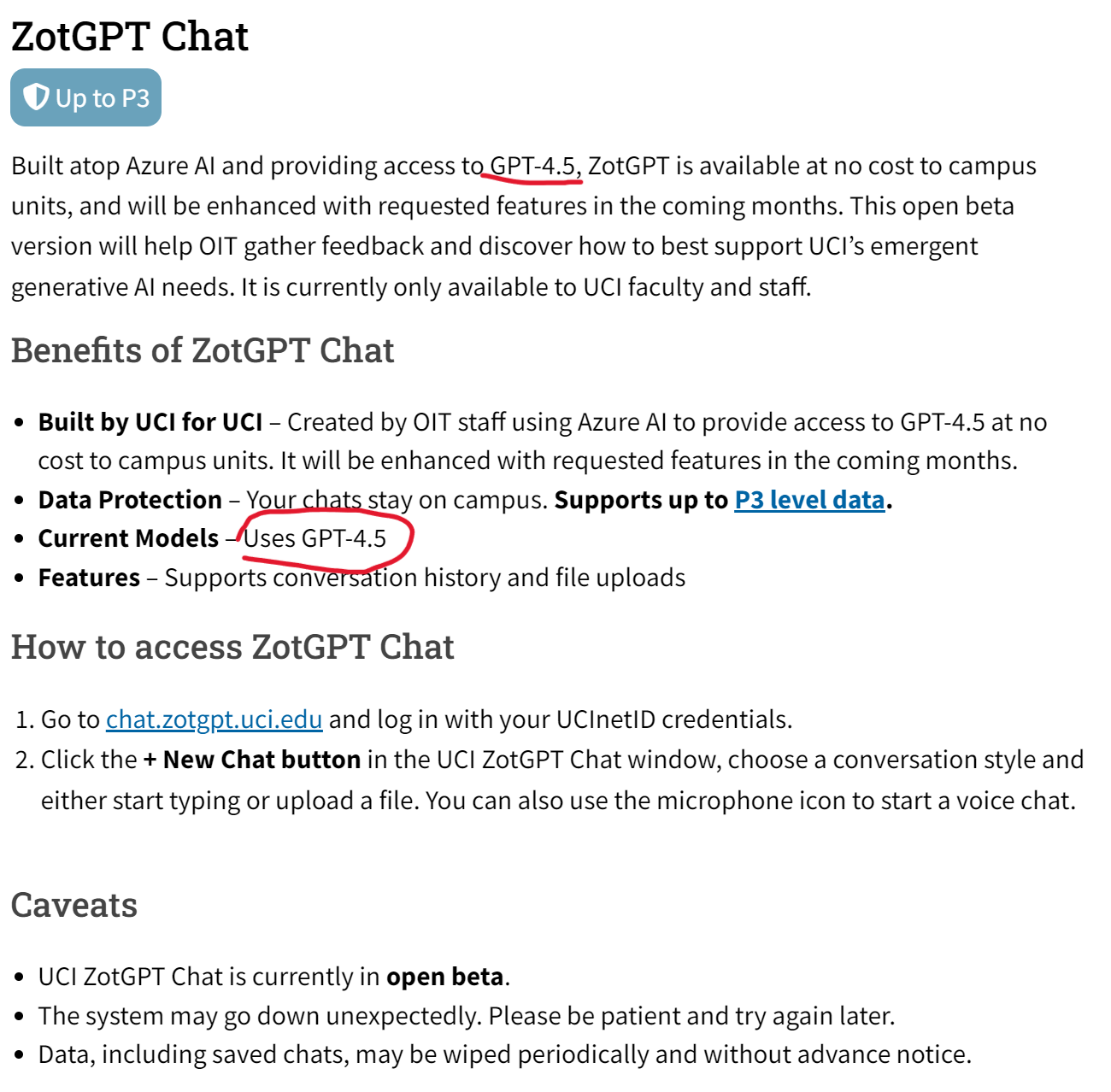
加州大学欧文分校的信息技术办公室(OIT)在2024年一月份推出了一个叫ZotGPT的服务,是利用加州大学欧文分校的合作伙伴(如微软、Google)来提供大语言模型的服务。就是说用一个ZotGPT服务来接入不同服务商提供的大模型,如Gemini、GPT等。目前包含ZotGPT Chat、Copilot和Gemini三大服务,其中最新的ZotGPT Chat服务介绍页面显示,他们现在已经提供GPT-4.5的服务!

就在大家还在争论 AI 编程上限的时候,Cursor 团队发布了一份非常值得大家关注的内部测试报告,展示了当我们将 Agent 的规模和运行时间推向极致时,会发生什么。这不仅仅是简单的代码生成,而是让 AI 像人类团队一样协作,构建百万行级别的项目。这项实验为我们揭示了 AI 在编码领域的潜力与局限,值得每位开发者关注。
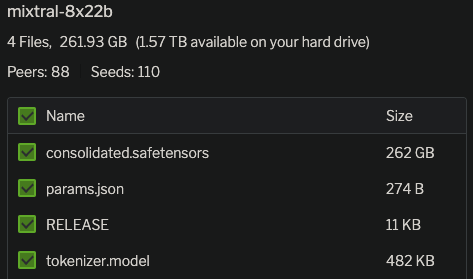
Mixtral-8×7B-MoE是由MistralAI开源的一个MoE架构大语言模型,因为它良好的开源协议和非常好的性能获得了广泛的关注。就在刚才,Mixtral-8×7B-MoE的继任者出现,MistralAI开源了全新的Mixtral-8×22B-MoE大模型。
SWE-bench Multilingual 是 SWE-bench 基准系列的扩展版本。该基准用于评估大语言模型在软件工程任务上的表现,覆盖多种编程语言。数据集包含 300 个从真实 GitHub 问题与对应拉取请求中提取的任务,涉及 42 个仓库和 9 种编程语言。模型接收问题描述与仓库快照后,需生成代码补丁,并通过失败到通过(F2P)和通过到通过(P2P)测试套件进行验证。

ClawdBot 是一款开源AI代理工具,旨在帮助用户在本地设备上处理各种任务,在科技社区中迅速获得关注。它于2025年底由开发者Peter Steinberger(@steipete)推出,基于Anthropic的Claude模型,名称结合了“Claw”(龙虾钳子)和“Claude”,并以龙虾作为吉祥物,象征其适应性和本地运行特性。该工具强调本地优先的设计,用户可以完全控制数据和过程,避免对云服务的依赖。
就在刚才,很多人发现DeepSeek官网已经更新了模型,虽然不确定是DeepSeek-V4,但是目前可以肯定,这不是之前公布的DeepSeek-V3.2而是一个全新的模型。为此,DataLearnerAI实测正式,这个模型的确并非此前的版本。

微软发布了全新的Phi-4推理模型系列,是小型语言模型(SLM)在复杂推理能力上的一种新的尝试。本次发布包含三个不同规模和性能的推理模型,分别是Phi-4-reasoning(140亿参数)、Phi-4-reasoning-plus(增强版140亿参数)和Phi-4-Mini-Reasoning(38亿参数)。这三款模型尽管参数规模远小于当前主流大型语言模型,却在多项推理基准测试中展现出与甚至超越大型模型的能力。
IFBench 是一个针对大语言模型(LLM)指令跟随能力的评测基准。该基准聚焦于模型对新颖、复杂约束的泛化表现,通过 58 个可验证的单轮任务进行评估。发布于 2025 年 7 月,该基准旨在揭示模型在未见指令下的精确执行水平。目前,主流模型在该基准上的得分普遍低于 50%,显示出指令跟随的潜在局限。
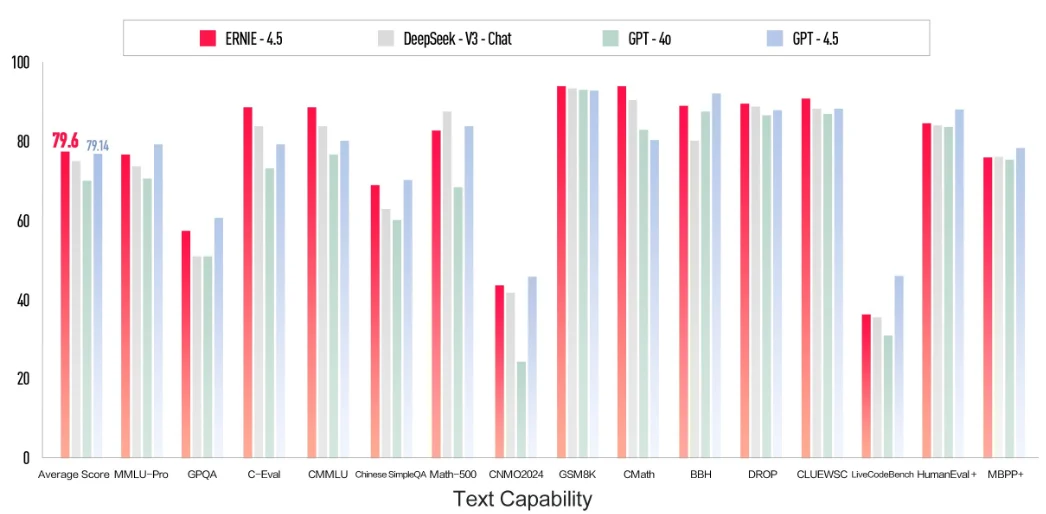
3月16日,百度宣布推出两款新一代文心大模型——ERNIE 4.5与ERNIE X1,并提前向公众免费开放其智能对话平台“文心一言”(ERNIE Bot)。官方宣称,这两款模型的能力均超过了GPT-4o,但是价格只有GPT-4o的1%,且是DeepSeek的一半。
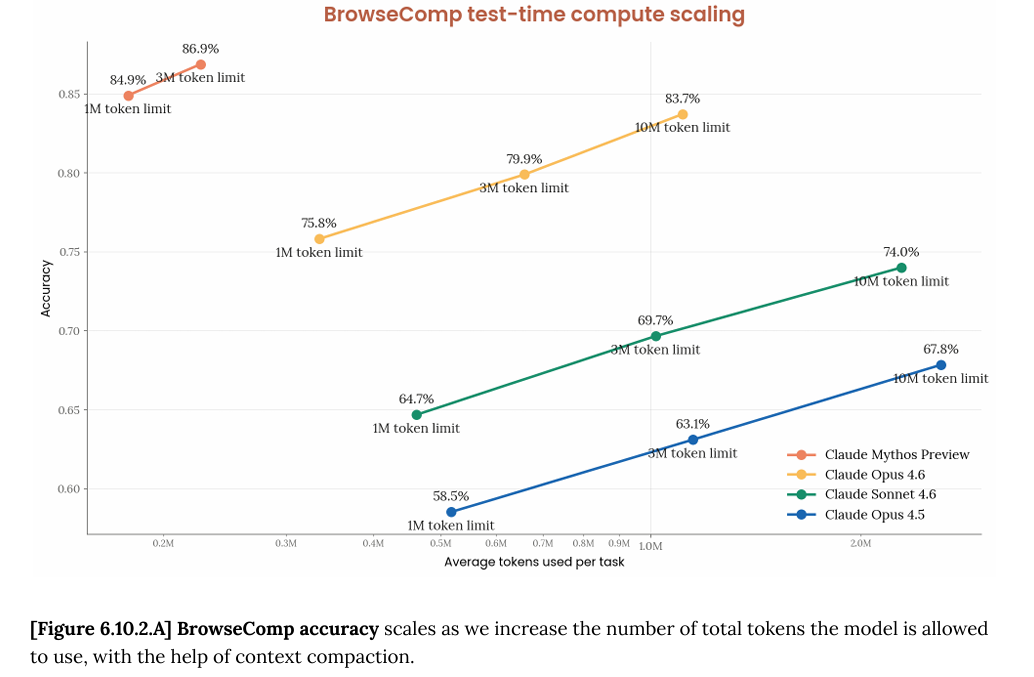
Anthropic 正式发布 Claude Mythos Preview,内部代号 Capybara,能力全面超越 Opus 4.6。该模型以不到 $50 的成本发现了 OpenBSD 27 年零日漏洞,SWE-bench Pro 达到 77.8%。Anthropic 通过 Project Glasswing 向 40 家机构开放访问权限,暂不对公众发布。DataLearner 提供完整评测数据。