Google发布迄今为止公开可用的最大的多语言网络数据集MADLAD-400,覆盖419种语言
Google DeepMind与Google Research的研究人员推出了一个全新的多语言数据集——MADLAD-400!这个数据集汇集了来自全球互联网的419种语言的大量文本数据,其规模和语言覆盖范围在公开可用的多语言数据集中应该是最大的。研究人员从Common Crawl这个庞大的网页爬虫项目中提取了大量数据,并进行了人工审核,删除了许多噪音,使数据集的质量得到了显著提升。
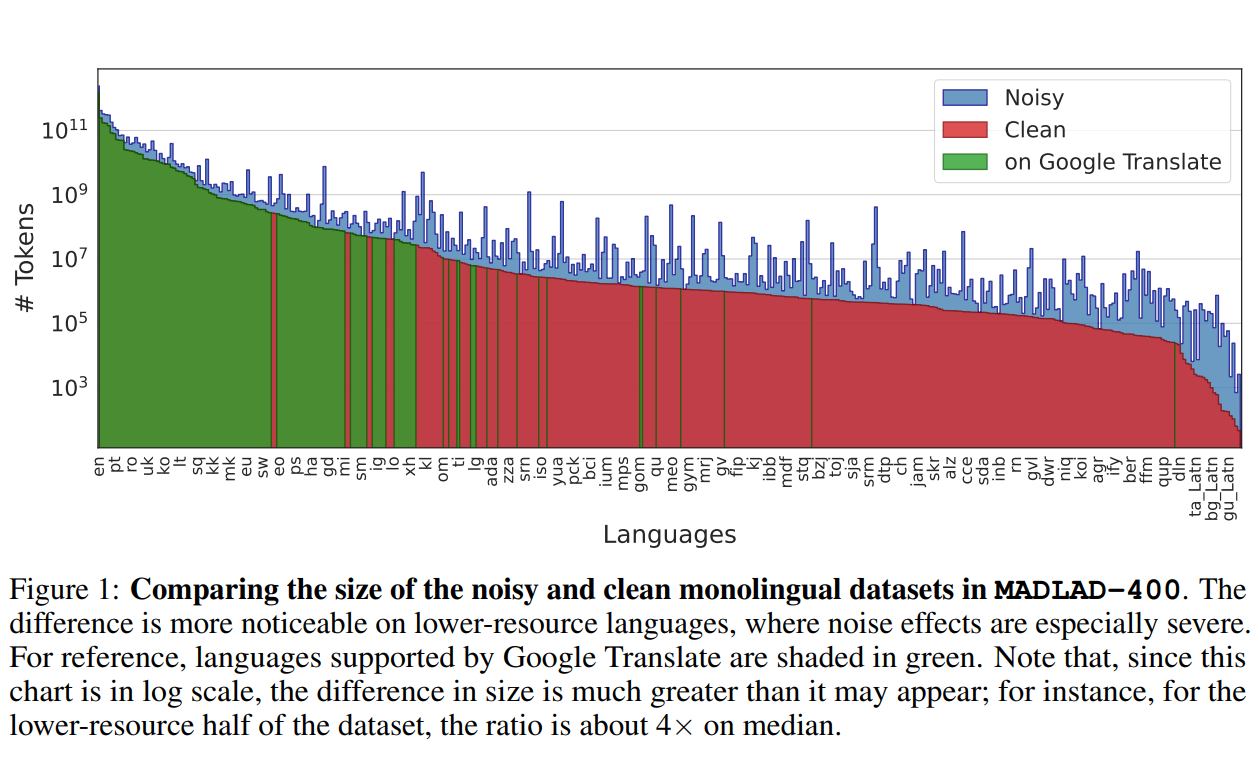
MADLAD-400简介
根据谷歌发布的论文提示,该数据集覆盖了419种语言,远远超过了目前公开数据集通常只包括100-200种语言的情况。其中不仅包括常见语言如英语、汉语,还包括许多罕见语言,如阿尔巴尼亚语、克罗地亚语等。这对于推动全球各种语言领域的自然语言处理具有重要意义。
其次,它的数据量非常庞大,包含了5万亿个tokens!这为训练大规模多语言模型提供了所需的海量数据。模型所训练的数据量越大,其效果就越好,这个数据集满足了对大规模数据的需求。
此外,数据集是按文档划分的,而不是简单的句子级别,这更符合语言的自然分布。研究人员还经过手动审核,对存在问题的语言数据进行了过滤,以确保数据集的整体质量。
MADLAD-400的预处理
然而,这种网络规模的语料库众所周知地存在噪音和包含不良内容,其中多语言分区通常具有其特定问题,如无法使用的文本、错位以及错标/模糊标记的数据。为了减轻这个问题,Google研究人员对数据进行手动审核。
他们从初步数据集中丢弃了79种语言,重命名或合并了几种语言,并应用了额外的预处理步骤。因此,得到了2个数据集:
可以看到,这个数据集的清理工作做了很多,去除了将近一半的数据。清理后的数据具有很高的质量。这里也总结一下Google Researc是如何做MADLAD-400数据清理的:
预处理
Google Research对MADLAD-400进行了多项预处理步骤以提高数据集的质量。这些步骤包括去重文档,以消除重复内容,过滤掉过于短小的文档,因为这些文档通常包含的信息有限。此外,还过滤掉包含特定字符串(如“Javascript”)的文档,因为这些字符串通常出现在无用的页面代码中。这些预处理步骤有助于过滤掉大量无效信息,从而提高了整体数据集的质量。
语言识别
Google Research对MADLAD-400使用了半监督训练的LangID模型对文档进行语言识别,并为每篇文档添加了语言标签。该模型支持498种语言,可以处理大规模数据集。基于这个模型的语言识别结果,创建了一个初步标注语言信息的MADLAD-400数据集,称为MADLAD-400-noisy版本。
质量评分
在这里,Google Research引入了一种称为percent_questionable评分的方法,用于评估每篇文档的质量。这一评分反映了文档存在的问题程度,评分越高表示问题越多。根据这一评分,可以过滤掉质量较差的文档,从而提高整个数据集的质量。评分考虑了多个因素,例如语言不一致和过多的大写字母等。
人工审核:
Google也对MADLAD-400数据集进行了人工审核过程,其中498种语言的样本分发给作者进行检查。根据审核结果,决定删除79种语言,以优化语言列表。人工审核的重要性在于它可以发现自动方法无法识别的各种问题,是提高数据集质量的关键步骤。
定向过滤:
根据人工审核的反馈,对某些语言的特定问题进行了有针对性的过滤。例如,纠正显示错误的virama字符,转换存在编码问题的Zawgyi编码等。这些有针对性的过滤措施有助于解决特定语言中的问题。
根据这些步骤,大家也可以看到该数据的质量还是很不错的~
基于MADLAD-400训练的翻译模型
为了验证这个数据集的质量,Google还据此训练了一个翻译模型,称为MT模型。它包含不同规模的模型:
| 模型规模 | 层次数 | 参数数量 | 下载地址 | |------------|-------|------------|----------|-----------------------|----------------------| | MT-3B | 32 | 30亿 |https://console.cloud.google.com/storage/browser/madlad-400-checkpoints/checkpoints/3b-mt | MT-7.2B | 48 | 72亿 |https://console.cloud.google.com/storage/browser/madlad-400-checkpoints/checkpoints/7b-mt | MT-7.2B-Finetuned | 48 | 72亿 |https://console.cloud.google.com/storage/browser/madlad-400-checkpoints/checkpoints/7b-mt-bt | MT-10.7B | 32 | 107亿 | https://console.cloud.google.com/storage/browser/madlad-400-checkpoints/checkpoints/10b-mt
具体来说,Google使用带有机器翻译目标的监督平行数据以及具有MASS风格目标的单语MADLAD-400数据集来训练这个模型。这两个目标都以50%的概率进行采样。在每个任务中,使用最近引入的UniMax采样策略,以N = 10的阈值从不平衡数据集中采样语言。
我们还通过随机采样2M个单语样本(或给定语言的总样本数)并使用3B模型将其翻译到/从英语进行了后向翻译。按照Bapna等人的方法,Google以各种方式过滤了后向翻译的数据。对于自然目标和后向翻译的源语言,并通过往返ChrF过滤以防止幻觉(阈值为0.32),通过源语言和目标语言之间的ChrF过滤以防止复制(阈值为0.30),通过源语言与目标语言的长度比率(非对称边界为(0.45,1.6)),以及源语言的LangID预测。
然后,通过随机混合原始数据和后向翻译数据,并使用1:1的组合比率对7.2B模型进行了10,000个步骤的微调。在论文附录A.8中列出了这些模型的具体架构和训练细节。
MADLAD-400的下载地址和其它资源
MADLAD-400的论文:MADLAD-400: A Multilingual And Document-Level Large Audited Dataset
MADLAD-400的GitHub地址:https://github.com/google-research/google-research/tree/master/madlad_400
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
