Saleforce发布最新的开源语言-视觉处理深度学习库LAVIS
近年来,在创建复杂的语言-视觉模型方面取得了显著的发展。现实世界的应用在很大程度上依赖于多模态材料,特别是语言-视觉数据,其中包括文本、照片和视频。
然而,跨任务和数据集训练和评估这些模型需要领域知识,而且它们不一定对新的研究人员和从业人员开放。不管是现有模型的使用还是数据集的获取都十分困难。
但是,Salesforce的研究人员开发了LAVIS(LAnguage-VISION的缩写),这是一个开源的库,用于在丰富的常见任务和数据集系列上训练和评估最先进的语言-视觉模型,并用于在定制的语言-视觉数据上进行现成的推理。可以帮助大家减轻这个苦恼。
LAVIS简介
LAVIS是一个用于LAnguage-and-VISion智能研究和应用的Python深度学习库。这个库的目的是为工程师和研究人员提供一个一站式的解决方案,为他们特定的多模态场景快速开发模型,并在标准和定制的数据集中对其进行基准测试。它有一个统一的界面设计,可以访问
- 10多个任务(检索、字幕、视觉问题回答、多模态分类等)。
- 20多个数据集(COCO、Flickr、Nocaps、Conceptual Commons、SBU等)。
- 30多个经过预训练的最先进的基础语视模型的权重及其特定任务的适应性,包括ALBEF, BLIP, ALPRO, CLIP。
下图是LAVIS的一些使用场景:
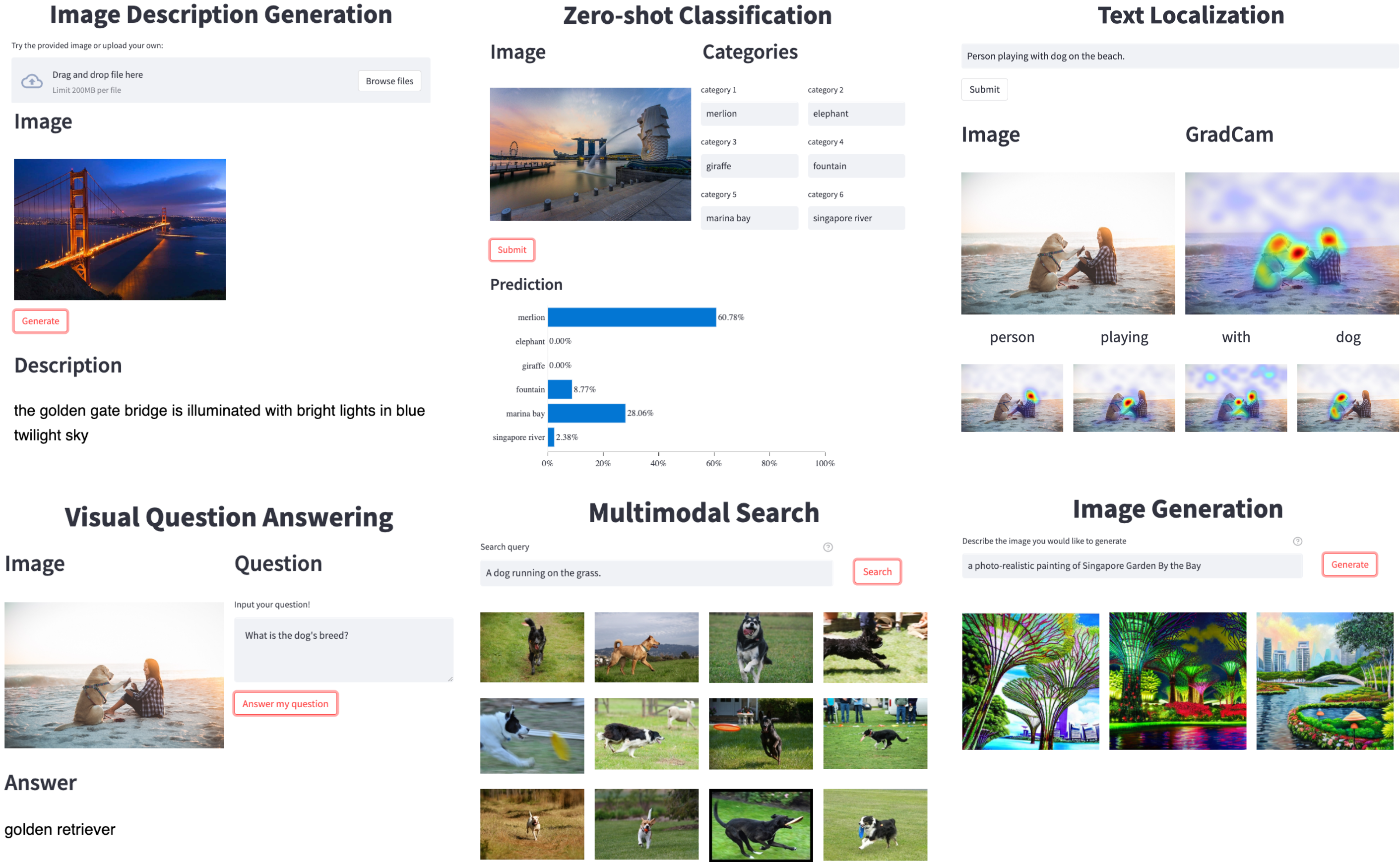
LAVIS的主要特点
LAVIS十分强大,其主要特点包括:
-
统一和模块化的界面:便于轻松利用和重新利用现有的模块(数据集、模型、预处理器),也便于添加新的模块。
-
简单的现成推理和特征提取:现成的预训练模型让你在自己的数据上利用最先进的多模态理解和生成能力。
-
可复制的模型zoo和训练食谱:在现有的和新的任务上轻松复制和扩展最先进的模型。
-
数据集zoo和自动下载工具:准备许多语视数据集可能是一件麻烦事。LAVIS提供自动下载脚本,帮助准备大量的数据集及其注释。
目前,LAVIS支持的任务和数据集如下:
可以看到,常见的图像处理和文本处理任务都是支持的,数据集也很丰富。真的很不错。
LAVIS使用方法
使用真的很简单,安装完LAVIS之后,代码十分简洁。不过需要注意的是,pypi库还没有上架,因此,pip install lavis是无法找到和安装lavis的。需要使用conda或者从git上下载之后自行编译。
从conda创建
conda create -n lavis python=3.8
conda activate lavis
或者从GitHub下载编译
git clone https://github.com/salesforce/LAVIS.git
cd LAVIS
pip install.
接下来的使用很简单,我们可以通过如下命令查看当前已经支持的模型:
from lavis.models import model_zoo
print(model_zoo)
# ==================================================
# Architectures Types
# ==================================================
# albef_classification ve
# albef_feature_extractor base
# albef_nlvr nlvr
# albef_pretrain base
# albef_retrieval coco, flickr
# albef_vqa vqav2
# alpro_qa msrvtt, msvd
# alpro_retrieval msrvtt, didemo
# blip_caption base_coco, large_coco
# blip_classification base
# blip_feature_extractor base
# blip_nlvr nlvr
# blip_pretrain base
# blip_retrieval coco, flickr
# blip_vqa vqav2, okvqa, aokvqa
# clip_feature_extractor ViT-B-32, ViT-B-16, ViT-L-14, ViT-L-14-336, RN50
# clip ViT-B-32, ViT-B-16, ViT-L-14, ViT-L-14-336, RN50
# gpt_dialogue base
lavis自带很多数据集可以直接下载,大家可以通过如下命令查看下载数据集:
from lavis.datasets.builders import dataset_zoo
dataset_names = dataset_zoo.get_names()
print(dataset_names)
# ['aok_vqa', 'coco_caption', 'coco_retrieval', 'coco_vqa', 'conceptual_caption_12m',
# 'conceptual_caption_3m', 'didemo_retrieval', 'flickr30k', 'imagenet', 'laion2B_multi',
# 'msrvtt_caption', 'msrvtt_qa', 'msrvtt_retrieval', 'msvd_caption', 'msvd_qa', 'nlvr',
# 'nocaps', 'ok_vqa', 'sbu_caption', 'snli_ve', 'vatex_caption', 'vg_caption', 'vg_vqa']
LAVIS的GitHub地址:https://github.com/salesforce/LAVIS
可以搞起来了!
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
