Transformer蓝图:Transformer 神经网络架构的综合指南——万字长文、20多个图片介绍大语言模型主流架构Transformer的发展历史、现状和未来结果
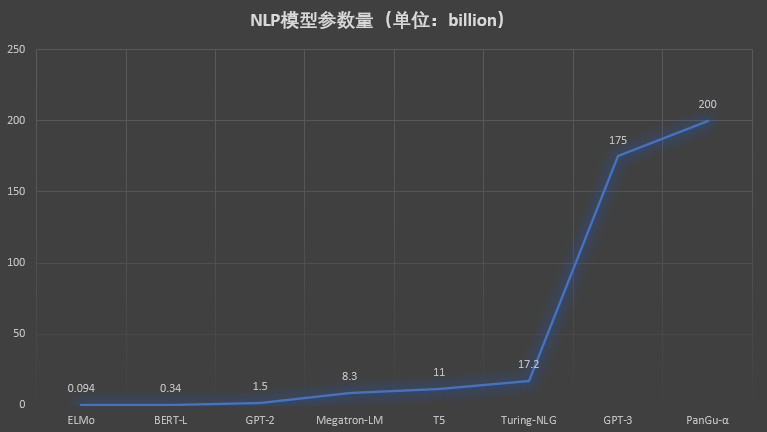
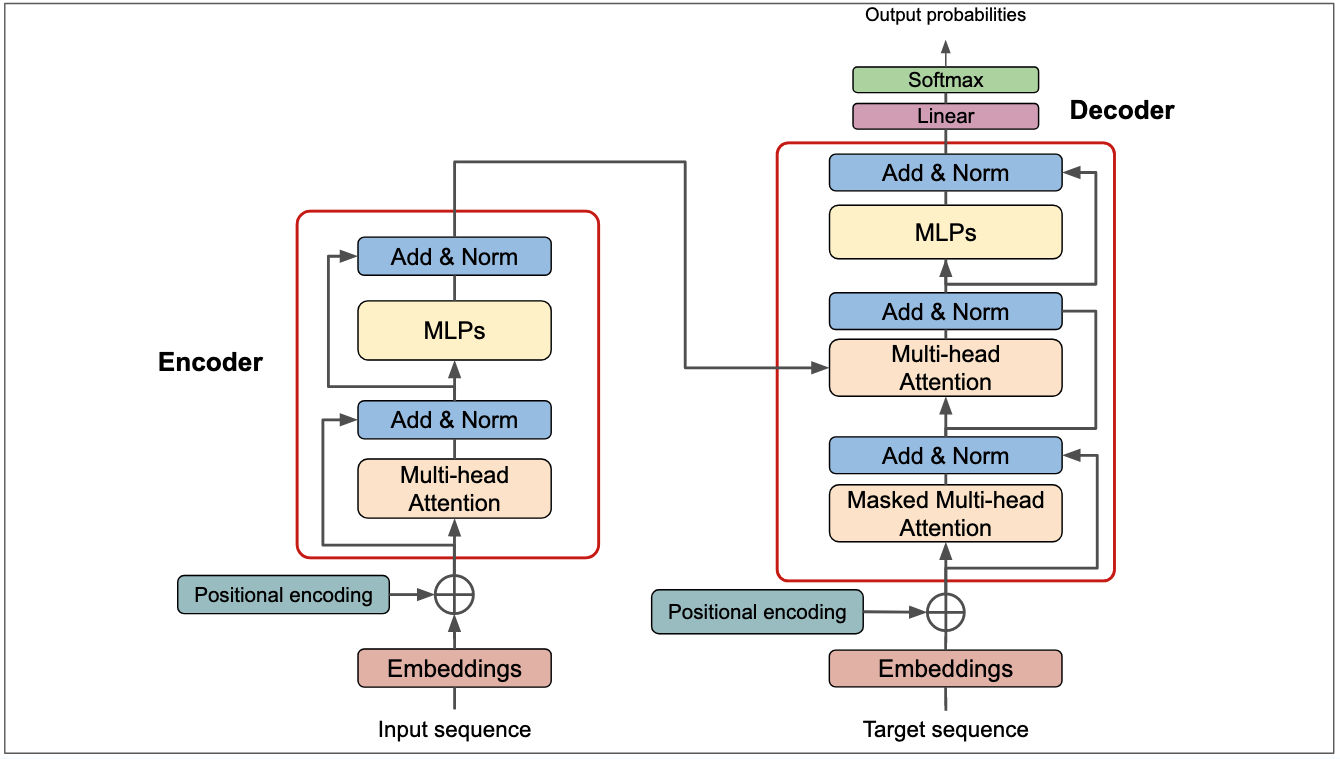
CMU的工程人工智能硕士学位的研究生Jean de Nyandwi近期发表了一篇博客,详细介绍了当前大语言模型主流架构Transformer的历史发展和当前现状。这篇博客非常长,超过了1万字,20多个图,涵盖了Transformer之前的架构和发展。此外,这篇长篇介绍里面的公式内容并不多,所以对于害怕数学的童鞋来说也是十分不错。本文是其翻译版本,欢迎大家仔细学习。