Batch Normalization应该在激活函数之前使用还是激活函数之后使用?
Batch Normalization(BN)是深度学习领域最重要的技巧之一,最早由Google的研究人员提出。这个技术可以大大提高深度学习网络的收敛速度。简单来说,BN就是将每一层网络进行归一化,就可以提高整个网络的训练速度,并打乱训练数据,提升精度。但是,BN的使用可以在很多地方,很多人最大的困惑是放在激活函数之前还是激活函数之后使用,著名机器学习领域的博主Santiago总结了这部分需要注意的内容。
结论可以直接看第三部分:
一、BN简介
首先是对BN的简短介绍:Batch Normalization在每一次迭代训练的时候,针对每一个mini-batch的数据,对每一层的输入进行normalize。
二、BN的使用方式
以Keras为例,BN使用如下:
model = Sequential([
Dense(128, input_shape=(4,), activation="relu"),
BatchNormalization(),
Dense(10, activation="softmax")
])
这里我们是在输入层之前,激活函数之后加了一个BN的层。注意,也有人的写法如下:
model = Sequential([
Dense(128, input_shape=(4,)),
BatchNormalization(),
Activation(activations.relu),
Dense(10, activation="softmax")
])
这种写法和上面最大的区别是BN层的位置从激活函数之后变成了在激活函数之前计算。这二者虽然看起来简单,但是区别很大。
三、BN层是在激活函数之前还是之后使用?
如果我们在激活函数之前增加BN层,那么我们可以完整地利用激活函数的输出。例如,Sigmoid可以将BN的输出限制在0-1的范围内。这种方式也有原作者的解释(也是原作者推荐的方式):

意思是在激活函数之前使用BN可以输出更加稳定的分布结果,让激活函数更好地发挥作用。但是,如果在激活函数之后使用BN可以使得下一层网络的输入是一个normalized的输入,可以让所有的值都在相同的尺度范围内。这是Paperspace blog里面提到的(参考链接:Intro to Optimization in Deep Learning: Busting the Myth About Batch Normalization):

作者认为,放在激活函数之后在实际训练中有更好的效果。
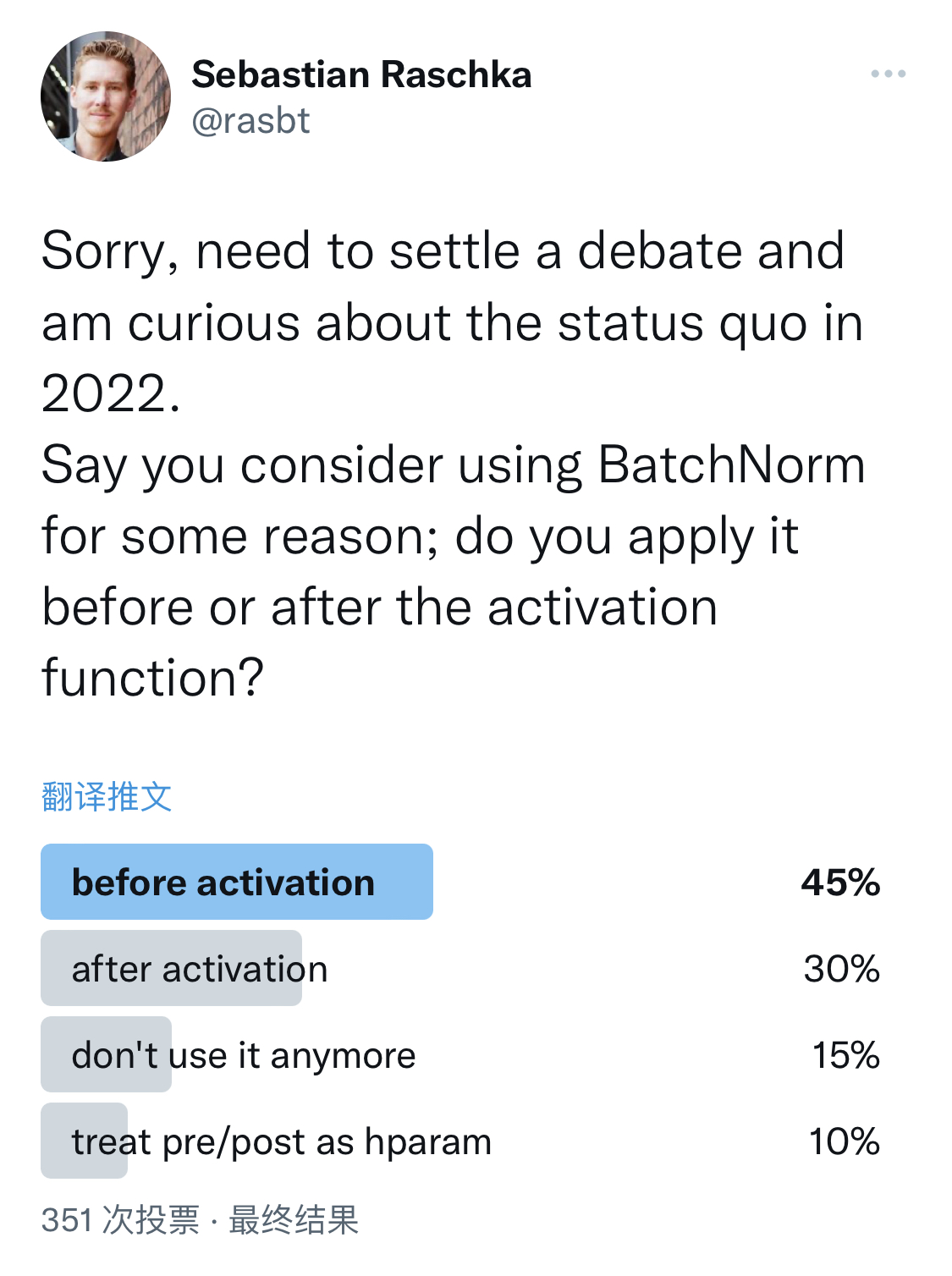
这没有标准的答案,著名深度学习学者Sebastian Raschka在推特上发布的调查,让大家选择BN的使用方式,结果显示,45%的人在激活函数之前使用,但也有30%的人在激活函数之后使用,剩下的人不适用或者treat pre/post as hparam。
那么实际情况中,应该是需要测试一下最好,不同的场景也许有不同的结论。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
