Pika和HeyGen的开源替代品:上海人工智能实验室开源可以生成高质量最长61秒视频的LaVie文本生成视频大模型
最近,初创企业Pika引起了全球的目光。这家公司发布的Pika 1.0产品可以基于生成式AI技术来创建3D动画视频或者电影级别的视频。由于其逼真的效果,引起了很多人的关注。本文则介绍一个由上海人工智能实验室开源的文本生成视频大模型LaVie。这个模型可以根据文本生成高质量的视频内容。

LaVie模型的代码和预训练结果均已开源,地址参考DataLearnerAI模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/LaVie
LaVie模型介绍
LaVie模型是一个可以基于文本提示生成视频的大模型,也是三个模型连接的级联模型。LaVie模型的论文在9月底就已经公开。但是模型预训练结果是11月中上旬开源,这个模型参数共30亿,由三个模型级联组成。
LaVie在生成视频方面展现出了极高的质量。这主要得益于它的三部分架构:基础的文本到视频(T2V)模型、时间插值模型和视频超分辨率模型。这种集成方法允许LaVie在保持高视觉质量的同时,生成在时间上连贯和流畅的视频。
LaVie框架包含三个模块,它们的训练过程如下。
首先,基础T2V模型利用WebVid10M和Laion5B数据集进行预训练,之后逐步引入Vimeo25M数据集进行微调。TI模型和VSR模型则分别基于预训练好的基础模型进行初始化,并使用相关视频数据集继续微调。
LaVie模型训练的数据集简介
这个模型使用了多个数据集,在不同的训练阶段进行训练。主要包括:
- WebVid10M:1000万个文本-视频对数据集
- Laion5B:50亿个图像-文本对数据集
- Vimeo25M:2500万个高分辨率、审美性文本-视频对(本文提出)
其中,Vimeo25M数据集在提高模型性能方面起到关键作用。也是由这个团队收集的。尽管论文中团队说的是 contribute a comprehensive and diverse video dataset named Vimeo25M,但是目前还未看到开源地址。
相比WebVid10M,它包含更高分辨率、更好审美性的视频。
下图展示了Vimeo25M数据集的统计结果。

LaVie模型的效果
下图是LaVie模型展示的一些视频截图:

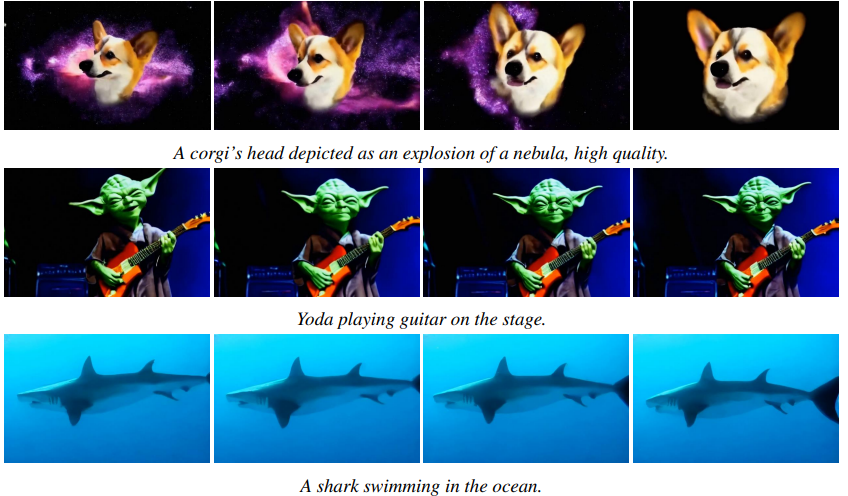
从这些截图可以看到,LaVie模型生成的图片细节还是很不错的。而且各种风格都有不错的表现,包括现实照片风格、艺术画像等。在原论文中,作者在视觉质量、文本视频语义相似性、人类评估、量化评估中都做了丰富的比较。结论是LaVie在视觉质量方面表现优异,特别是在合成具有复杂空间和时间概念的视频时。
在相同的实验设置下,LaVie的表现超过了Video LDM的最先进结果。在与Make-A-Video的比较中,尽管LaVie使用了较小的训练数据集,但在某些方面仍然表现出色。
LaVie模型的在线演示效果
官方在HuggingFace上发布了一个在线演示的space,大家可以自行尝试效果,可能由于硬件成本的原因,生成的视频限制在2秒。下图是我生成的视频(油画版的上海):

另外,模型本身是三个级联模型,因此可以选择不同的级联方式,效果也不相同,在官方的GitHub中,作者提供了四个生成视频的选择:
可以看到,这个模型最好的情况下可以生成可以生成61秒的1280x2048分辨率的视频。
模型的代码和预训练结果均为Apache2.0开源协议,大家自由试用,具体的模型预训练和代码开源地址以及在线演示地址参考DataLearnerAI的模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/LaVie
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
