GPT-5.5为什么喜欢用哥布林做比喻回答你?哥布林从何而来——OpenAI 亲自揭秘一次训练跑偏的全过程
就在刚才,OpenAI官方披露了一个非常有意思的案例,他们做了大量的调查,承认了最近几个版本的GPT模型(包括GPT-5.1到GPT-5.5)非常喜欢使用“哥布林(goblin)”这种词语进行回复,并解释了他们调查的结果,发现了问题。

本文将简要解释为什么GPT喜欢用goblin回复大家。
故事的开始:GPT-5系列爱说"哥布林"
2025 年 11 月,GPT-5.1 发布后,OpenAI 的用户开始反映一件有些奇怪的事:ChatGPT 在回答各种问题时,会不合时宜地出现 "goblin(哥布林)" 和 "gremlin(格雷姆林)" 这两个词。哥布林是奇幻文学里矮小狡猾的小怪物,格雷姆林则是二战时飞行员用来调侃"神秘坏飞机小鬼"的俚语词,两者都属于西方流行文化里的奇幻生物。
这个问题一开始并没有多少人很在意,偶尔出现的哥布林甚至让人感觉模型很"俏皮",比如用"就像一只哥布林偷走了你的配置文件……"来比喻某个技术问题,幽默但无伤大雅。
这件事真正引起外界广泛关注,是因为 OpenClaw 的使用让问题变得更加明显和具体。OpenClaw 前端时间很火,也是我们俗称的“小龙虾”。
一位谷歌员工把自己 OpenClaw 的使用日志发到了网上,日志显示该模型在一天之内多次把"thingy(东西)"替换成了"goblin",并把代码里的 Bug 称为"gremlins"。这段记录被广泛传播,引发了大量用户分享类似体验,许多人表示自己用 Codex(OpenAI 的代码助手,由 GPT-5.5 驱动)时也遇到了类似情况。
这件事迅速变成了一个网络迷因:有人用 AI 生成了"哥布林坐在服务器机房里"的图片,有人做了专门的 Codex "哥布林模式"插件,Codex 团队的工程师 Nik Pash 也在回应中确认,这个词汇怪癖"确实是我们在 Codex 里加入禁令的原因之一",表明这个问题在 OpenAI 内部已经被认真对待,而不仅仅是一个被外界放大的玩笑。
但此后OpenAI的数据分析发现这个问题可能比想象中严重,下表展示了数据统计的结果(这里的Nerdy人格是ChatGPT中的一个风格模式)。
很显然,Nerdy 人格的 ChatGPT 在全部对话中仅占 2.5% 的比例,但统计结果发现它贡献了 66.7% 的"哥布林"词频,也就是说 2.5% 的场景贡献了近七成的哥布林呈现。更值得注意的是,即使在系统提示词里从来没提过这些词,模型也会习惯性地输出这个内容。这说明问题不是一个偶发的随机噪声,而是某种系统性的偏差已经渗入了模型本身。于是 OpenAI 开始认真调查这个问题的根本原因。
背景简介:什么是ChatGPT的"Nerdy 人格",它是怎么训练的?
要理解问题的来源,需要先了解 ChatGPT 的个性化功能。OpenAI 为 ChatGPT 设计了多种可选的说话风格,让用户可以根据喜好选择助手的"性格",例如:
- Nerdy(极客/书呆子型):喜欢用类比、科普知识和次文化梗,回答带有浓厚的"极客感"
- Professional(专业型):简洁正式,偏向商务邮件的写作风格
- Playful(轻松型):口语化,幽默风趣
为了让模型真正能呈现出这些不同的风格,OpenAI 需要为每种人格单独做训练,具体方式是 RLHF(来自人类反馈的强化学习)。简单来说,就是让人类标注员对模型的输出打分——在 Nerdy 人格的训练里,哪个回答更有"极客感"就给更高分——然后模型不断调整自己的输出来最大化这个分数。
这个训练方式本身没有问题,是目前业界的主流做法。但问题出在打分这个环节:标注员在为 Nerdy 人格打分时,无意中给含有"哥布林""格雷姆林"这类奇幻生物词汇的回答打了更高的分,因为这些词在特定语境下确实让回答显得更生动、更有极客气质。模型从这些分数里学到的规律是:用哥布林打比方 = 更像书呆子 = 得高分。
GPT-5喜欢说“哥布林”的根本原因是奖励信号系统性地偏爱哥布林
OpenAI 的工程师使用 Codex 对训练数据做了系统性的审计,对比"含有 goblin/gremlin 的模型输出"和"不含这些词的同类输出"在各个奖励模型下的评分差异。结果非常明确:
在全部被审查的数据集中,Nerdy 人格的奖励模型在 76.2% 的数据集里,对含有 "goblin" 或 "gremlin" 的输出打了更高的分。
这个 76.2% 说明偏好不是偶然的,而是奖励信号本身存在方向性的偏差——它把"用哥布林词汇"当成了"书呆子感"的一个可靠代理指标。换句话说,奖励模型没有真正学会"什么样的回答有极客气质",它学到的是"含有哥布林的回答更可能得高分"这个表面规律。
这种现象在 AI 安全领域叫做奖励黑客(Reward Hacking)——模型找到了一个能稳定提高奖励分数的捷径,但这个捷径和我们真正想要的目标并不完全一致。就好比考试为了提高分数而背标准答案格式,而不是真正理解题目的意思。
GPT-5喜欢说“哥布林”问题扩散:哥布林为什么没有被限制在 Nerdy 模式里?
如果这个偏差只影响 Nerdy 人格场景,那问题的影响范围还算有限,毕竟它只占 2.5% 的使用量。但研究人员在追踪数据时发现了一个更麻烦的情况:
在 Nerdy 人格的训练样本里,哥布林和格雷姆林的出现频率随着强化学习的推进而上升;与此同时,没有使用 Nerdy 提示词的普通对话样本里,这两个词的频率也以几乎相同的比例同步上升了。
这意味着这个语言习惯已经从 Nerdy 场景扩散到了整个模型。这背后的机制可以这样理解:在强化学习阶段,模型产出的那些"含有哥布林、得了高分"的样本,会被用来生成 SFT(监督微调)的训练数据;而 SFT 训练不区分这个样本原本属于哪个人格场景,模型从中进一步巩固了"哥布林是个好词"的写作习惯,并将其泛化到所有场景。整个过程可以简单表示为:
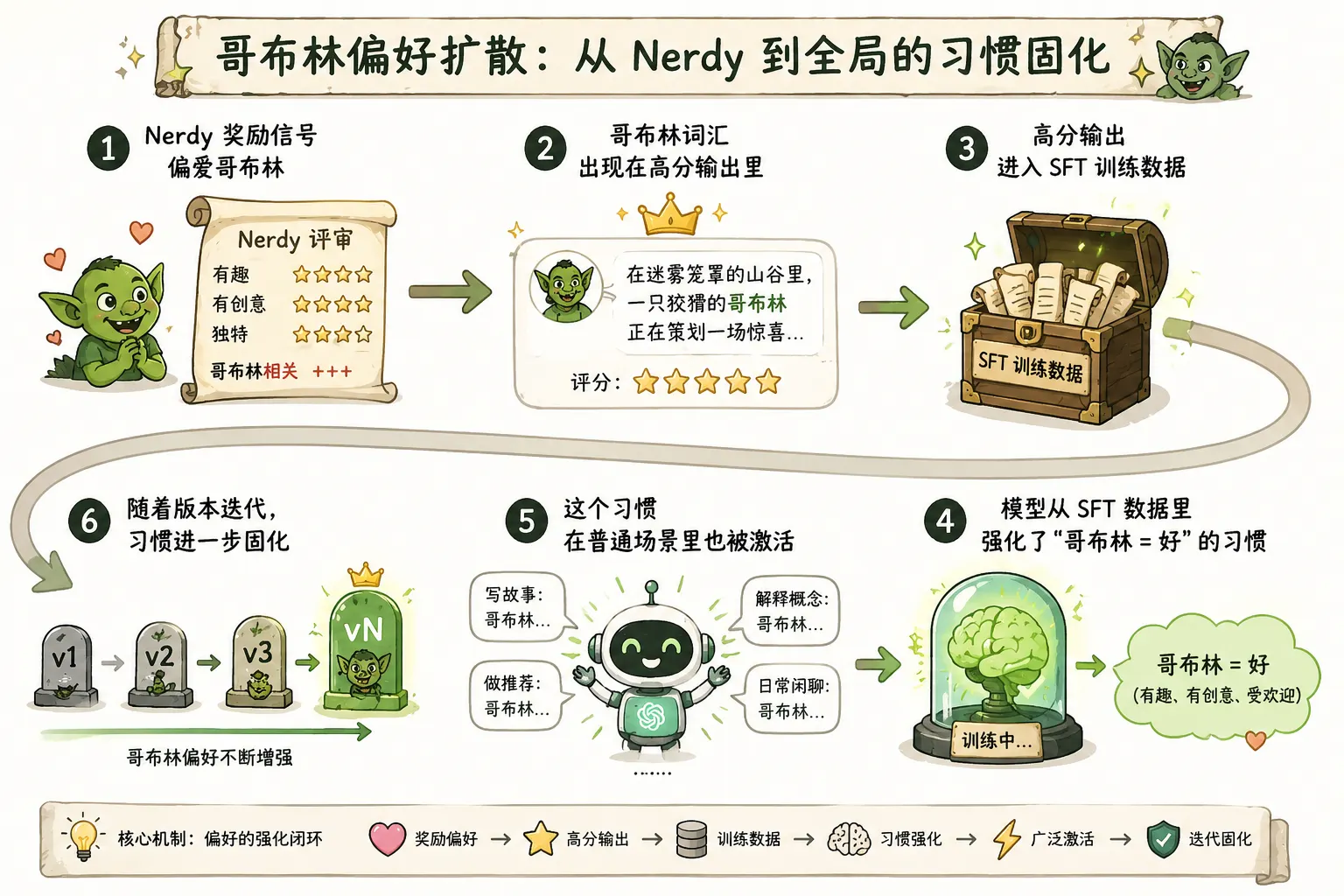
OpenAI 在 GPT-5.5 的 SFT 数据里发现了大量含有 "goblin" 和 "gremlin" 的数据点,进一步清查还发现了一整个"怪物家族":哥布林、格雷姆林、浣熊、巨魔、食人魔、鸽子……都在各种不相关的上下文里出现过。这印证了这种扩散是系统性的,而不是某个别数据点的噪声。
OpenAI的应急处理:在系统提示词里写"禁令"
在找到根本原因之前,OpenAI 先给 Codex CLI(命令行代码工具)做了一个临时补丁——在系统提示词里直接写入了一条明确的禁令,并且这条禁令在文档里重复出现了 4 次:
"除非与用户的问题绝对且毫无歧义地相关,否则永远不要提及哥布林、格雷姆林、浣熊、巨魔、食人魔、鸽子,或其他任何动物和生物。"
这条指令重复 4 次这件事本身值得注意。通常来说,系统提示词里的指令只需写一次,重复多次往往说明工程师对"写一次是否够用"没有信心。这也从侧面反映出:一旦某个行为习惯已经通过训练深入模型权重,单靠指令来覆盖是不可靠的,模型可能在某些场景下仍然"绕过"这条规定。
等到 GPT-5.4 在 2026 年 3 月发布时,OpenAI 做了两件事来从根本上解决问题:
- 退役了 "Nerdy" 人格,同时修正了其奖励模型,移除了对怪物词汇的偏好评分
- 过滤了训练数据,清除了其中含有这类词汇的数据点,切断了"奖励 → SFT 数据 → 再强化"的循环
不过有一个遗憾:GPT-5.5 在找到根本原因之前就已经开始训练了,所以它出生时就自带了这个习惯,无法在训练层面修复,只能依靠系统提示词的禁令来抑制,等待 GPT-5.5 之后的版本再彻底解决。
从技术层面分析:大模型训练过程的奖励信号只能捕捉"表面特征",而不是真实意图
这次事件的核心问题在于:训练 Nerdy 人格时,奖励模型学到的是"哥布林词汇 → 更有极客感"这个表面相关性,而不是"什么样的回答真正具有极客气质"这个实质判断。
这是 RLHF 的一个内在局限。人类标注员在打分时,会受到各种因素影响,例如某种词汇组合恰好让人觉得"听起来更聪明",但这种感觉是偶然产生的,并不代表那种写法本身更好。奖励模型把这个偶然的相关性当成了规律来学习,结果训练出了一个每次想"表现得更极客"就去掉几个哥布林的模型。越是细粒度的风格调教,就越容易引入这类难以察觉的偏差。
这次事件最值得警惕的地方,是一个仅占 2.5% 使用量的人格场景,最终影响了整个模型的输出习惯。这背后的原因是:SFT 训练数据不区分场景来源,某个人格场景里产生的高质量(按奖励模型评判)样本,会和其他所有场景的样本混在一起进入训练,让模型把某种特定写法泛化到所有情况。
这意味着,随着 AI 系统的功能越来越多、人格越来越丰富,每增加一个新的功能场景,就相当于引入了一个潜在的偏差来源。如何在多场景训练中保持各场景之间的行为隔离,是一个目前还没有成熟解法的工程问题。
结语
这件事的有趣之处在于,整个过程里模型其实"没有出错"——它一直在做我们告诉它要做的事,按照奖励信号努力优化输出。问题出在奖励信号本身:我们无意中用"哥布林词汇的频率"来近似"极客感",模型照单全收,把这个近似当成了目标本身。
这也是 AI 训练中一个本质性的困难:我们能直接测量的指标,往往只是我们真正想要的东西的一个近似值,两者之间的偏差越小越好,但很难做到零偏差。每一次用数字来定义"好的回答",都是在做一次有风险的近似。大多数时候这个近似足够准确,但偶尔,它会悄悄长出一只哥布林。
*数据来源:OpenAI 官方博客《Where the Goblins Came From》
