OpenAI 发布 GPT-5.5:代号"Spud",Agent 能力明显提升,API 因安全审查暂缓开放
OpenAI 于北京时间4月24日正式发布 GPT-5.5,内部代号"Spud"。距离 GPT-5.4 发布只有大约六周,这个节奏说明头部实验室现在基本上是滚动迭代而不是等大版本攒够了再发。GPT-5.5 即日起向 ChatGPT 的 Plus、Pro、Business 和 Enterprise 用户以及 Codex 用户开放,GPT-5.5 Pro 面向 Pro、Business 和 Enterprise。API 这边因为需要额外的网络安全防护验证,暂时没有同步上线,OpenAI 说"很快"会跟上。

GPT-5.5的就基本信息
GPT-5.5的上下文长度最高达到100万输入,不出意外应该还是128K的最大输出。不过需要注意的是,Codex里面的GPT-5.5的最高仅支持400K,100万是实验特性,需要手动开启。
GPT-5.5目前发布了2个版本,一个是标准版本的GPT-5.5,区分不同思考水平,一个是GPT-5.5 Pro版本,输入支持文本和图像,输出仅支持文本。
GPT-5.5 在 ChatGPT 中以"Thinking"形式暴露,支持多档思考时长调节。Plus 和 Business 用户可以选 Standard 和 Extended 两档,Pro 用户额外多出 Light 和 Heavy 两档。Codex 另有 Fast Mode,延迟降低 1.5 倍,但价格是标准的 2.5 倍。
OpenAI 联席总裁 Greg Brockman 在发布会上把 GPT-5.5 定位成"新一类智能",但具体说的是:在更少外部引导下完成更复杂的多步任务。说白了就是之前需要手把手给指令,现在可以把一个半成品任务丢给它,让它自己去拆解、规划、执行。
官方列出的重点改进方向有四个:Agentic Coding(代码工程)、Computer Use(计算机操控)、通用知识工作,以及科学研究辅助。
值得提一下的是,OpenAI 特别强调 GPT-5.5 的单 token 延迟和 GPT-5.4 持平,但完成同样任务消耗的 token 数更少。为什么说这个?因为GPT-5.5的接口价格比GPT-5.4翻了一倍!
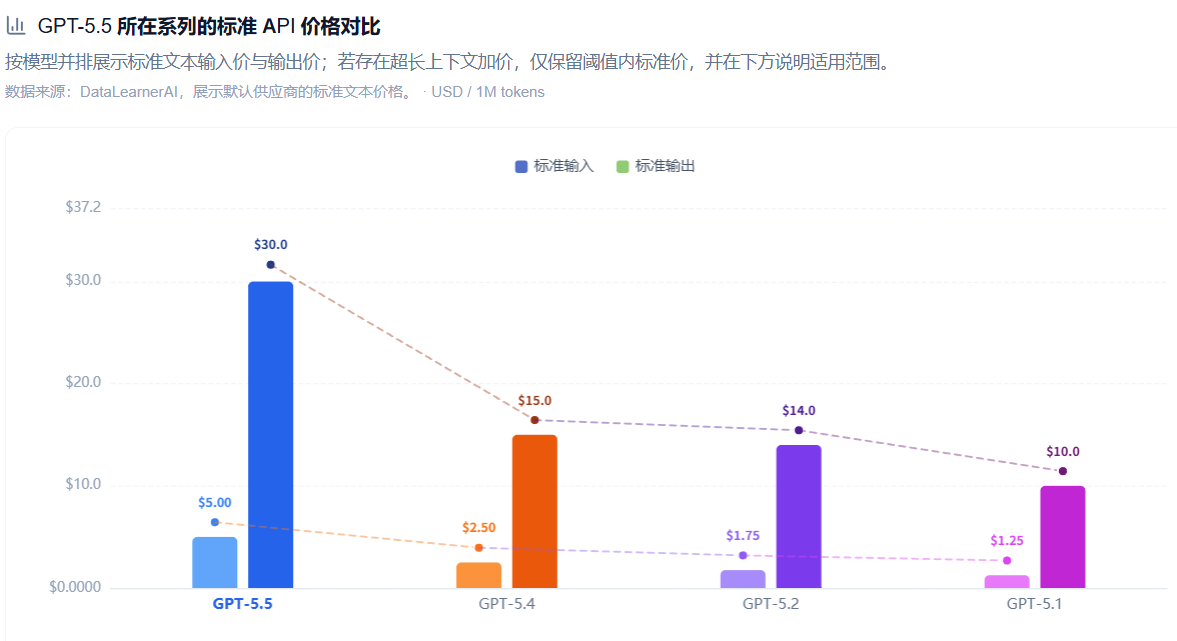
涨价明显!
GPT-5.5基准测试情况:Agent 场景领先,纯推理存在明显差距
OpenAI 公布的几个核心数据值得看一下。
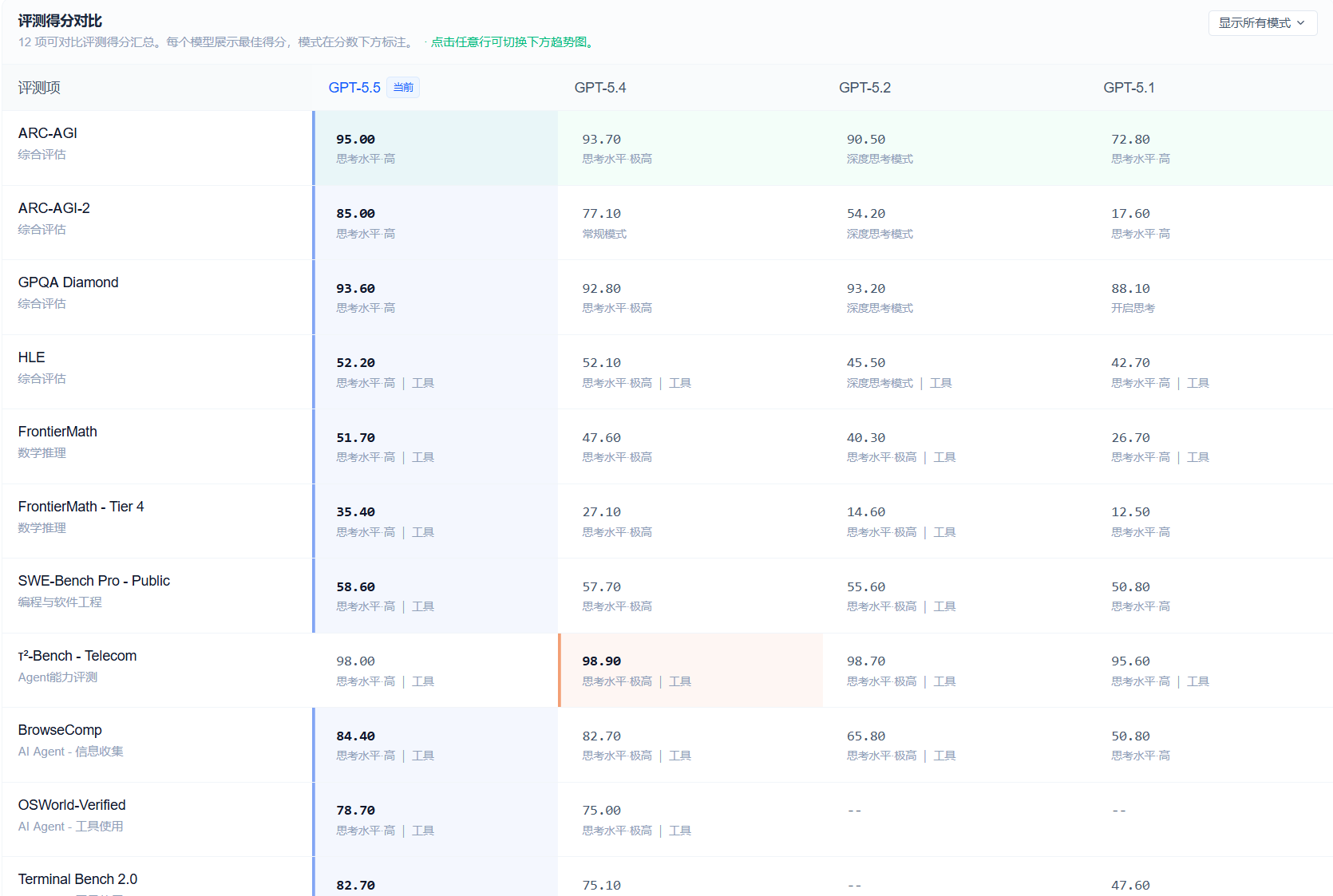
知识工作 Agent 类:GDPval(覆盖 44 个职业类别的知识工作任务评测)得分 84.9%;OSWorld-Verified(真实计算机环境自主操控)78.7%;Tau2-bench Telecom(复杂客服工作流,无提示词调优)98.0%。生物信息学数据分析基准 BixBench 上,OpenAI 称在已公布成绩的模型里排第一。
和 GPT-5.4 相比,进步最大的几个基准是:ARC-AGI-2 提升了 11.7 个百分点、MCP Atlas 提升 8.1 个百分点、Terminal-Bench 2.0 提升 7.6 个百分点。ARC-AGI-2 本身是刻意设计来抵抗快速饱和的通用推理基准,这个幅度的增长不算小。
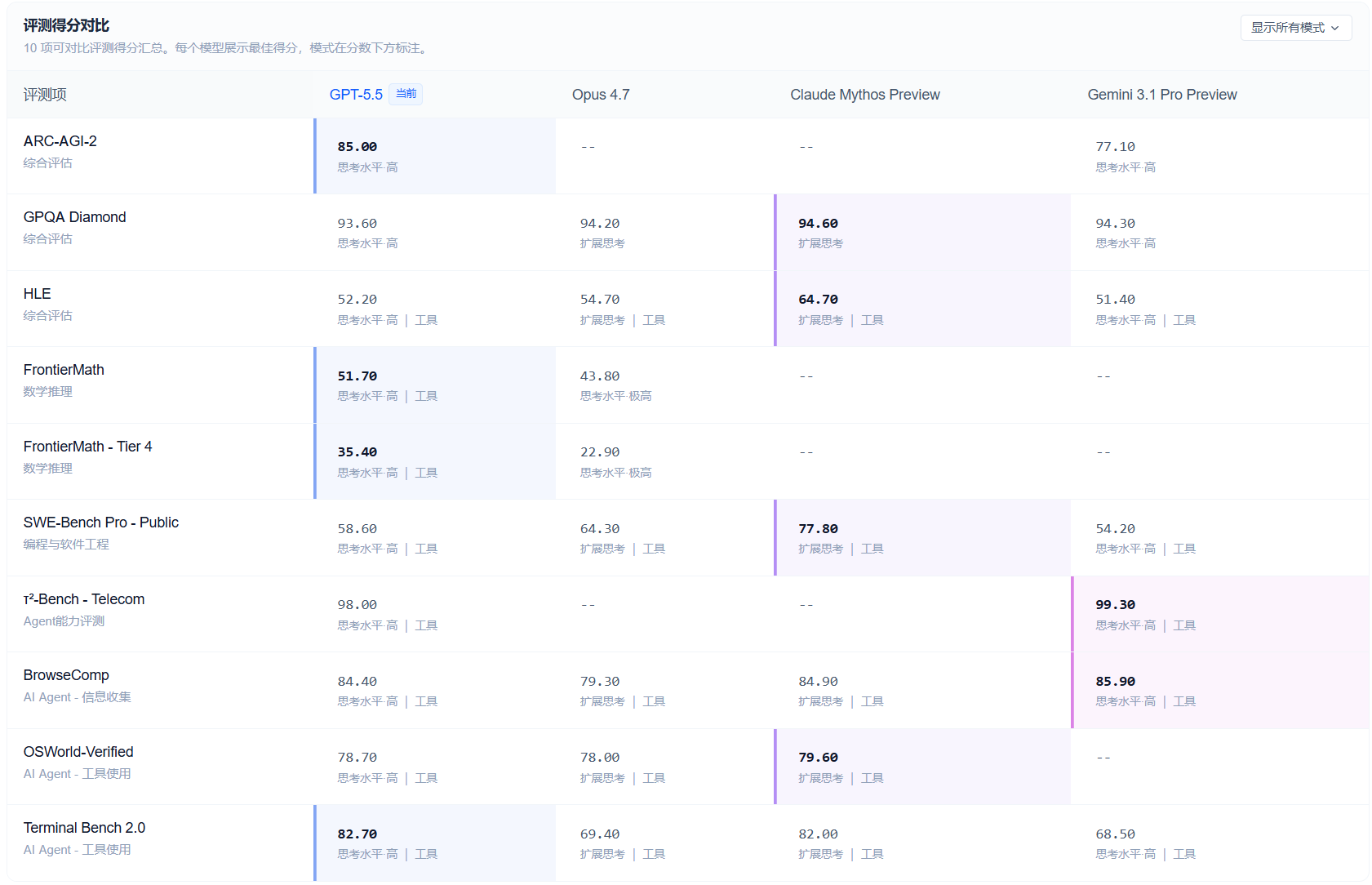
不过,切换到纯推理场景,情况就没那么好看了。Humanity's Last Exam(无工具条件)上,GPT-5.5 Pro 得分 43.1%,低于 Claude Opus 4.7 的 46.9%,和 Mythos Preview 的 56.8% 差距更明显。也就是说,GPT-5.5 在 Agent 执行和工具调用场景上是有优势的,但在不依赖工具的纯学术推理上,OpenAI 目前并不领跑。
第三方评测平台 BenchLM.ai 把 GPT-5.5 放在 112 个模型综合排行榜的第 5 位,总分 89/100。最强项是 Agentic 类任务(第 2),最弱项是多模态与有根基理解(第 64),和上面的分析对得上。
编程和 Agent:花两倍价格值不值?
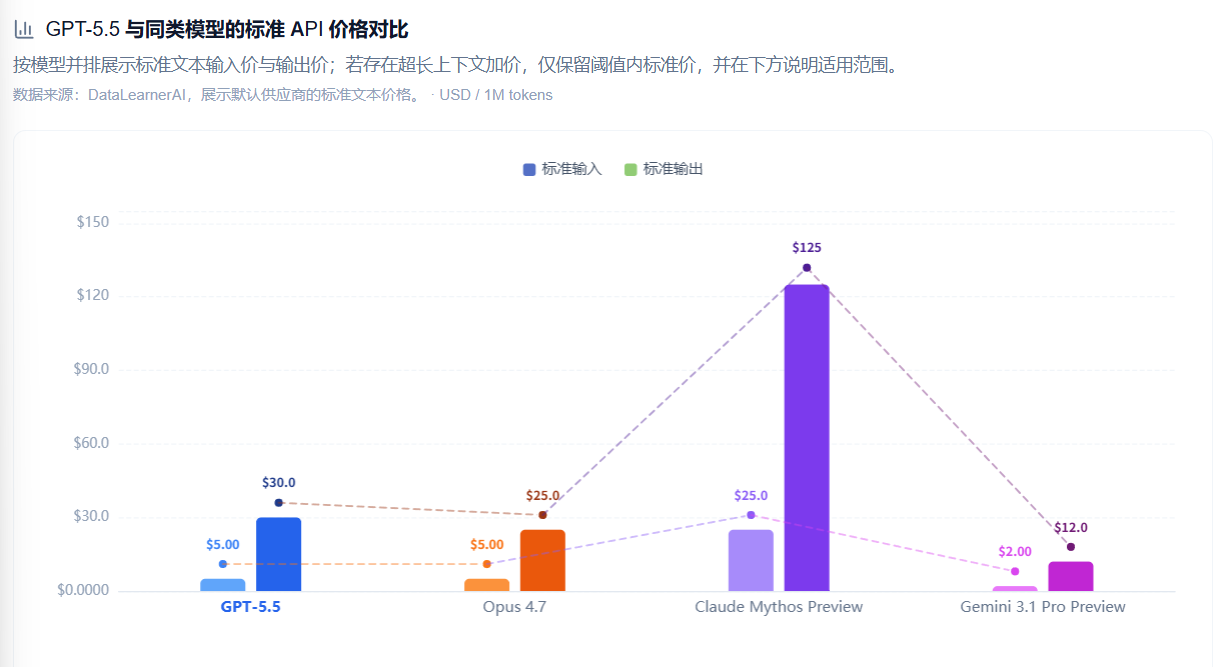
这次GPT-5.5的价格翻倍了,不太理解是因为模型本身变大了,还是单纯的想趁机涨价。这个价格目前已经超过了Opus 4.7了!也是可用的旗舰模型最贵的(Claude Mythos不可用)。
代码工程场景,OpenAI 的说法是 GPT-5.5 能更好地理解系统架构和故障节点,知道改哪里、改了之后会影响哪里。早期测试显示,同样的 Codex 任务 GPT-5.5 需要的重试次数更少,token 消耗也更低。这个说法有待验证,即使是真的,那GPT-5.5的成本应该也不低,毕竟价格翻倍,tokens能减少一半?非常怀疑。
计算机操控方面,OSWorld-Verified 78.7% 在目前公开有成绩的模型里是比较靠前的。有早期测试团队用 GPT-5.5 批量审阅了数千份文档,另一个团队把每周商业报表的处理流程压缩节省了 5 到 10 小时。
Nvidia 内部测试中把 GPT-5.5 描述为"首席参谋"型工具——可以驱动已经在内部作为员工角色运行的 AI Agent。这个描述不是说说而已,Nvidia 副总裁 Justin Boitano 说该模型已经经过了数周的内部测试。
定价上,API 端输入 $5 / 输出 $30(每百万 token),是 GPT-5.4($2.50/$15)的整整两倍。但结合 token 效率的提升,实际综合成本增幅会低于这个倍数,高吞吐量场景还是要具体测一下再做判断。
GPT-5.5的科研能力更强:已经不只是搜信息了
OpenAI 这次专门强调了科研辅助,首席研究官 Mark Chen 说 GPT-5.5 在科学与技术研究工作流上"有实质性提升",并点名药物发现是重点应用方向之一。
一个比较有说服力的案例是:一个配了定制推理框架的 GPT-5.5 内部版本,参与发现了拉姆齐数(Ramsey Numbers)的一个新证明。拉姆齐数是组合数学里的核心研究对象,这个案例说明模型的贡献已经不只是整理信息,而是在数学推理生成层面有了真实的参与。当然,这是内部特化版本,和通用产品端的能力不能直接划等号。
GPT-5.5发布总结:API 暂未上线,网页已经可以使用,免费用户暂时不可使用
OpenAI官方说API 部署"需要不同的安全防护措施",公司正在和合作伙伴对接大规模服务的安全需求。所以接口暂不上线。
简单总结一下,GPT-5.5 是一次以 Agent 执行能力为核心的定向升级,不是全面碾压式的代际跃迁。ARC-AGI-2、MCP Atlas、Terminal-Bench 2.0 的增益,加上 OSWorld-Verified 78.7%,指向的是一个在实际工程和任务自动化场景里更可用的执行型模型。和Qwen 3.6版本的升级很类似。或许,大模型的通用能力已经达到一个瓶颈了也说不定。
GPT-5.5更多信息参考DataLearnerAI的模型信息卡: GPT-5.5信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/gpt-5-5 GPT-5.5 Pro信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/gpt-5-5-pro
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
