MiniMaxAI开源MiniMax M2模型:Artificial Analysis评测显示综合智能得分超过Claude Opus 4.1,开源第一,全球第五。
MiniMax正式开源MiniMax M2模型,该模型定位是“Mini 模型,Max 编码与代理工作流”。最大的特点是2300亿总参数量,但是每次推理仅激活100亿,类似于10B模型。这款模型非常火爆,原因在于这么小的激活参数数量,推理速度很快,但是其评测结果非常优秀。

目前,MiniMax M2已经开源,参考:https://www.datalearner.com/ai-models/pretrained-models/minimax-m2
MiniMax M2模型的基本信息:超稀疏MoE架构,推理速度不错!
MiniMax M2是一个MoE架构的大模型,其总参数量为2300亿,每次推理仅激活其中的100亿,非常的稀疏。上下文最高支持205K,最高支持131K的输出,支持推理过程。MiniMax M2是纯文本大模型,不支持多模态的输入。
此前,阿里在9月份开源的Qwen3-Next-80B-A3B这个下一代的大模型也是采用了远超常规的激活比例(1:26左右,参考此前分析:https://www.datalearner.com/blog/1051757449442911 )。从此处看,更加激进的稀疏混合专家架构似乎是一个非常重要的模型方向。FP8格式的MiniMax M2模型需要4台H100部署。
这种架构带来的最显而易见的优点是推理速度的提升。根据当前的官方的接口测试结果,MiniMax M2的推理速度达到了每秒84 tokens左右,上一代的Mini Max M1只有一半,约41 tokens/秒。而Claude Sonnet 4.5则只有61 tokens/秒。可以说非常不错的速度了(官方说其接口速度是Sonnet的2倍)。
MiniMax M2最大的特点:Agent能力强悍
MiniMax M2在社区中非常火热。最大的原因是它是目前开源领域中最好的模型之一(综合评测其实就是最好的)。
根据Artificial Analysis给出的大模型综合排名看,MiniMax M2得分是61分,全球排名第五,开源第一。这个分数综合了不同的评测结果,目前第一名是GPT-5 Codex High,得分68。
综合来看,MiniMax M2主要关注Agentic相关的应用,在tool usasge和指令跟随方面表现很好。因此,类似Tau2 Bench 和 IFBench这种工具使用评测得分很好。但是,在更加基础和广泛的领域表现则不如DeepSeek V3.2或者Qwen3 235B这些模型。不过,这也是最近国内大模型的一个发展趋势:大家似乎都在集中精力攻克“智能体”能力,因而放弃了模型一些写作和创意方面的表现。在后训练过程中,似乎更加关注模型优先选择调用工具而不是自己计算,或者更精确地理解复杂指令的能力。
MiniMax M2与DeepSeek、Qwen对比
为了更加直观对比MiniMax M2模型和其它国内开源大模型的能力,我们也使用DataLearnerAI大模型工具做了对比。
首先,我们看一下不使用工具情况下,推理模式下MiniMax M2与其它模型对比:
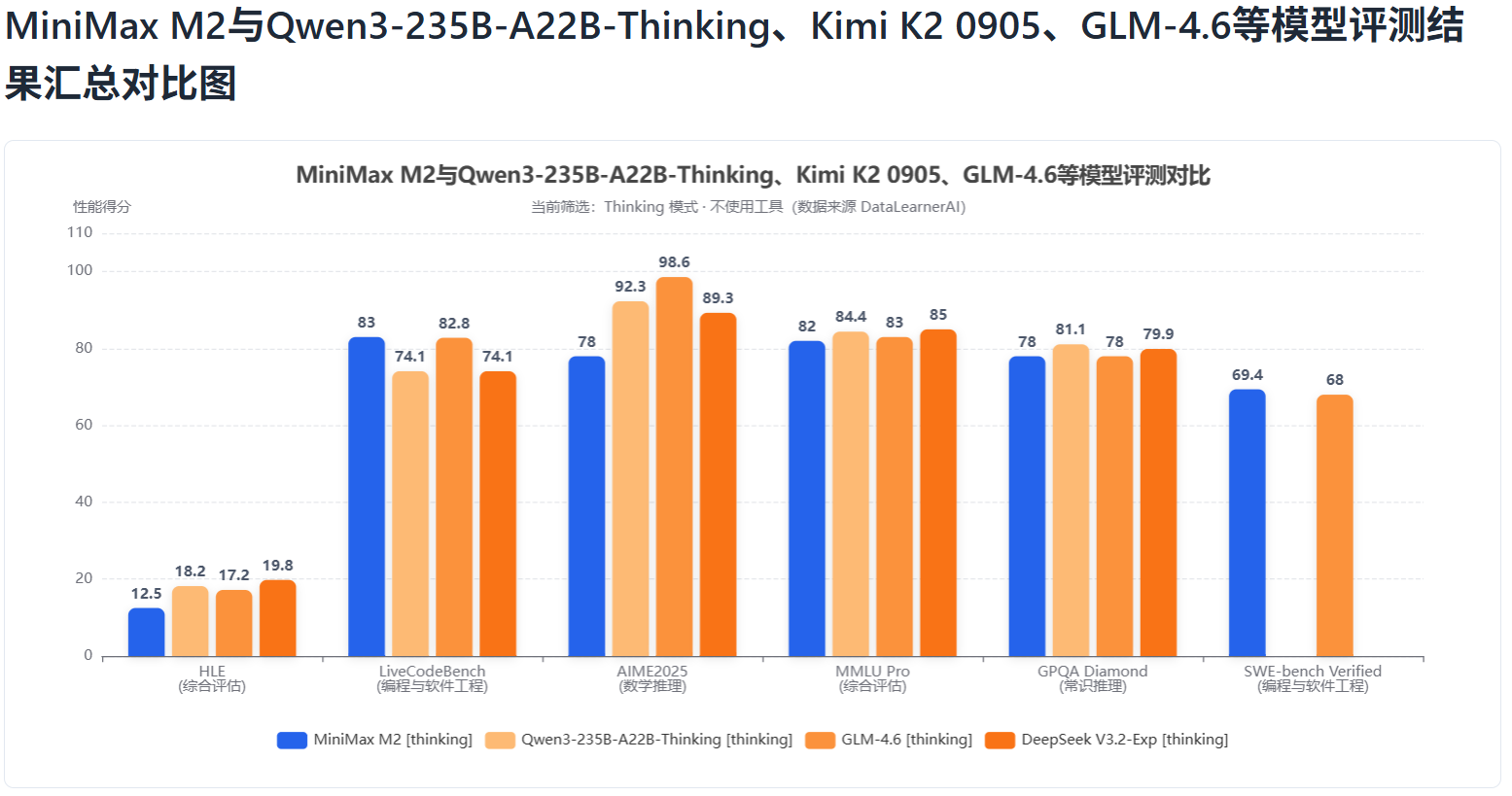
可以看到,在不使用工具的情况下,MiniMax M2模型和其它几个模型对比结果有显著的差异。在非编程任务如HLE、AIME2025上,MiniMax M2模型并不是最好的。甚至AIME2025得分显著低于其它模型。但是在编程方面,如LiveCodeBench、SWE-Bench Verified方面则是最好的。
在使用工具方面,如下图所示,我们也可以看到,Terminal Bench上,MiniMax M2超过GLM 4.6,但是低于DeepSeek V3.2,而τ²-Bench上则显著优于其它模型。前者主要看大模型使用命令行工具的能力,后者则是大模型和人类一起协作完成任务的能力。
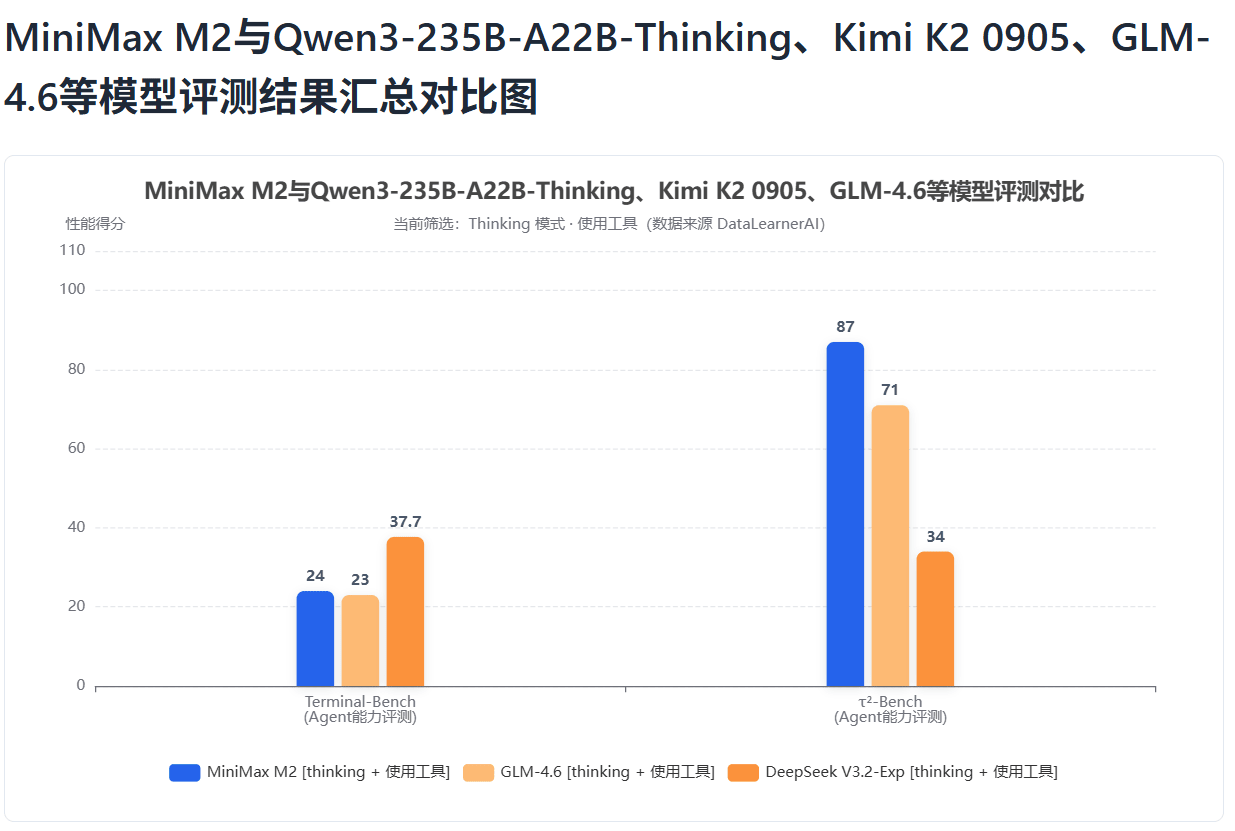
总的来说,MiniMax M2模型目标非常清晰,它没有追求各方面完美,而是在编程或者agentic的工具使用方面追求最好的水平。
也有网友做了一些其它测试,例如使用Claude Code对接GPT-5 Codex和MiniMax M2模型来测试Next.js的使用。最后发现50个问题中,MiniMax M2模型通过了22个,比GPT-5 Codex还要好1个。也是从另一方面证明了这个模型的能力。
MiniMax M2模型总结:免费开源,官方接口价格十分便宜
最后,稍微总结一下MiniMax M2模型。
MiniMax M2模型以MIT协议开源,意味着可以完全免费商用。而官方给的API价格也非常低,输入0.3美元/100 万tokens,输出是1.2美元/100 万tokens。只有Claude Sonnet 4.5的8%!非常便宜。
此外,官方目前的接口也是可以免费使用,直到11月7日。这意味着,大家可以直接使用Claude Code之类的工具随便测试!
总体而已,MiniMax M2模型是国内又一个顶尖的开源模型。最重要的是相比同类的模型,它的推理速度也是目前非常具有吸引力的特性。
关于MiniMax M2模型更多的信息参考DataLearnerAI的大模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/minimax-m2
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
