
原创博客
原创AI技术博客
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。

狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)
狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)是一种非参数贝叶斯模型,它可以理解为一种聚类方法,但是不需要指定类别数量,它可以从数据中推断簇的数量。这篇博客将描述该模型及其求解过程。
ItemCF--Python
基于项目最近邻的协同过滤算法,面向的是隐偏好数据,数据格式为<userid,itemid>,测试算法的指标为precision和recall
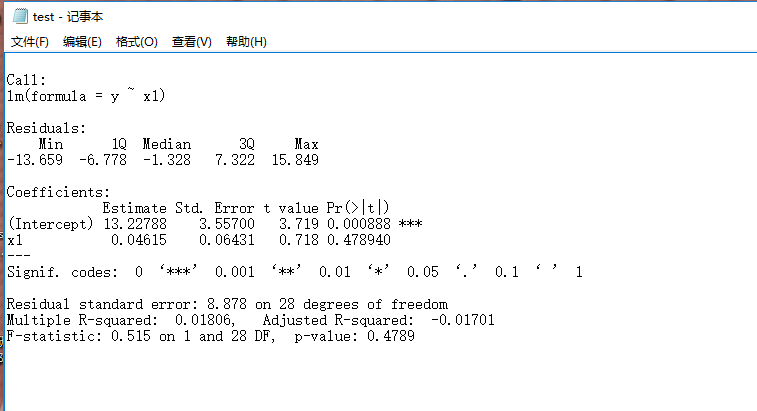
R语言如何将实验结果导出
使用R语言进行数据分析时,我们经常会遇到实验结果输出的问题,例如使用summary函数时,变量太多,控制台输出的结果不全,那么怎么将结果导出呢?
参数估计之极大似然估计、极大后验估计和贝叶斯参数估计
这篇博客主要翻译自Gregor Heinrich的技术博客Parameter estimation for text analysis,介绍极大似然估计、极大后验估计和贝叶斯参数估计的原理和案例
基于PITF模型的个性化标签推荐
本文是Steffen Rendle的Pairwise Interaction Tensor Factorization for Personalized Tag Recommendation的译文。
BPR:面向隐式反馈数据的贝叶斯个性化排序
本文是Steffen Rendle的文章BPR: Bayesian Personalized Ranking from Implicit Feedback的译文
贝叶斯分析推断的一些基础知识
贝叶斯分析在概率模型中有非常重要的作用,这些年以来比较有影响力的模型如LDA、非参数贝叶斯模型等都是基于贝叶斯分析的。贝叶斯分析有一些非常基础性的知识,在这里我们描述了贝叶斯分析里面的一些基本表示和一些分析准则等内容。

层次贝叶斯模型(一) 之 构建参数化的先验分布
这个系列的博客来自于 Bayesian Data Analysis, Third Edition. By. Andrew Gelman. etl. 的第五章的翻译。实际中,简单的非层次模型可能并不适合层次数据:在很少的参数情况下,它们并不能准确适配大规模数据集,然而,过多的参数则可能导致过拟合的问题。相反,层次模型有足够的参数来拟合数据,同时使用总体分布将参数的依赖结构化,从而避免过拟合问题。
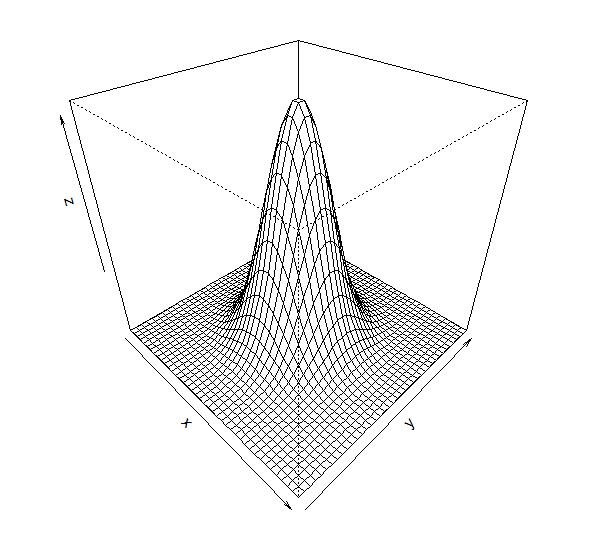
机器学习中的高斯过程
关于高斯过程,其实网上已经有很多中文博客的介绍了。但是很多中文博客排版实在是太难看了,而且很多内容介绍也不太全面,搞得有点云里雾里的。因此,我想自己发表一个相关的内容,大多数内容来自于英文维基百科和几篇文章。
Java读取和操作上G文本数据
在处理文本时,经常遇到超过1g存储的数据,直接简单的读取,可能遇到java空间不足的问题,为解决此问题,可将大文本数据按照行进行切分为很多块,并将每一块存储为一个文本