7种交叉验证(Cross-validation)技术简介(附代码示例)
交叉验证是一种用于估计机器学习模型性能的统计方法。它是一种评估统计分析结果如何推广到独立数据集的方法。简单来说,就是将数据集分成不同的部分,然后某些部分训练,某些部分测试,某些部分验证,这样可以最大程度避免过拟合以及测试模型在陌生数据集的性能。
汇总「机器学习」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
交叉验证是一种用于估计机器学习模型性能的统计方法。它是一种评估统计分析结果如何推广到独立数据集的方法。简单来说,就是将数据集分成不同的部分,然后某些部分训练,某些部分测试,某些部分验证,这样可以最大程度避免过拟合以及测试模型在陌生数据集的性能。

机器学习相关的竞赛为大家学习使用算法提供了一个非常好的平台和机会。既能检验大家学习的算法的实际应用情况,也可以帮助我们学习到很多有用的技巧。很多竞赛也都产生了优秀的算法思想与经验。所以积极参加比赛是一种非常重要的学习方式。本文总结目前正在举办的比赛,各位可以根据自己的情况参与。

机器学习是这几年很热门的学习和工作的方向。但是机器学习相关算法的入门却并不容易。本文参考自MLTUT的博文,列举了2021年适合初学者的十个最佳机器学习网络课程供大家学习参考。

预测问题一直是机器学习领域最重要的问题之一。很多算法包括回归、决策树等都是用来解决预测的常用算法。预测问题的核心是基于已有的有标签的数据来判断新数据的标签。一般来说,根据预测标签是离散的还是连续的可以分成分类问题和回归问题。注意,本篇博客主要是快速回顾描述各个模型的优缺点,因此不会对模型有很深的介绍。
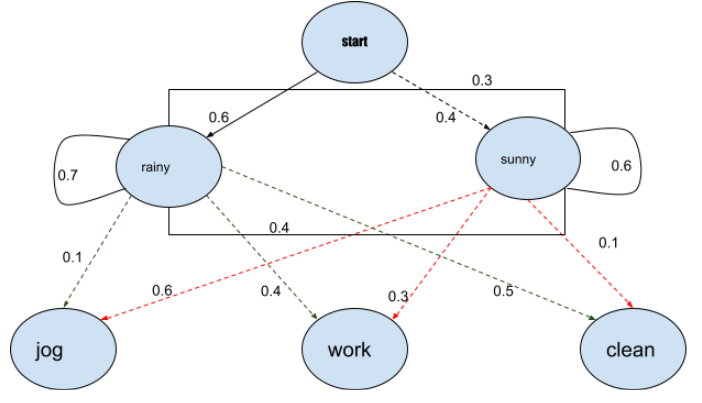
隐马尔可夫模型(HMM)是一种统计模型,也用于机器学习。它可以用来描述取决于内部因素的可观察事件的演变,而这些因素是无法直接观察到的。这是一类概率图形模型,允许我们从一组观察到的变量中预测一串未知的变量。在这篇文章中,我们将详细讨论隐马尔可夫模型。我们将了解它可以使用的背景,我们也将讨论它的不同应用。我们还将讨论HMM在PoS标签中的使用和python的实现。文章中所涉及的主要内容如下。
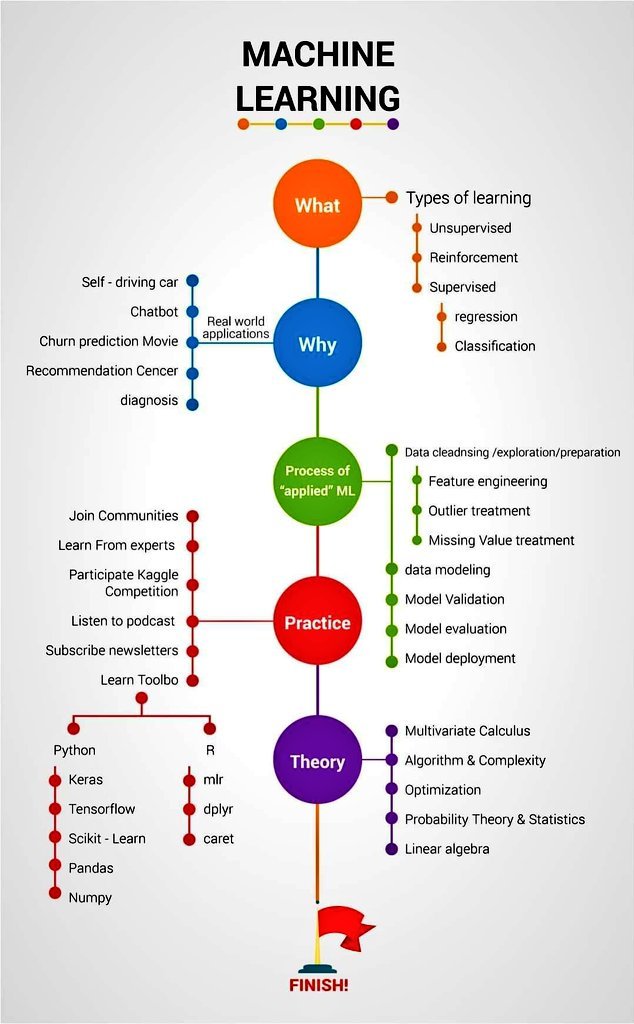
这是推特上Ternium的CIO发的一个图,关于机器学习理论和实践概念的信息图。这个图概括了机器学习实践流程的相关概念,简洁明了。对于入门的同学有很好的总结作用。

本篇是《阿里云天池大赛赛题解析-机器学习篇》的第一部分工业蒸汽量预测的第三章-特征工程的内容,并附带了一些知识点的网页链接。内有数据预处理、特征降维等内容。
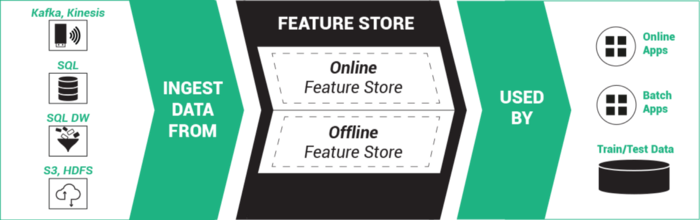
在2020年的亚马逊reInvent发布会上,亚马逊正式发布了一项新的服务,即Amazon SageMaker Feature Store,中文简介是适用于机器学习特征的完全托管的存储库。 Feature Store是这两年兴起的另一个关于人工智能系统的基础设施,应该也是未来几年最重要的人工智能基础设施之一。本文将介绍一下Feature Store是什么以及为什么很多企业开始推广这个东西。

Scikit-Learn有很优秀的机器学习处理思想,包括TensorFlow等新框架都借鉴了它的设计思想。最近的更新也让Scikit-Learn更加强大。在描述这个更新之前我们先简单看一下历史,然后让我们一起看看都有什么新内容吧。

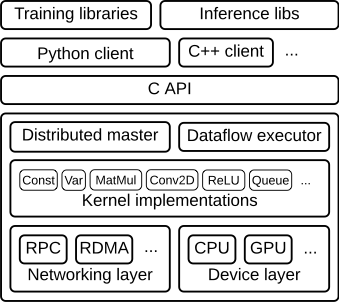
随着深度学习的火热,对计算机算力的要求越来越高。从2012年AlexNet以来,人们越来越多开始使用GPU加速深度学习的计算。 然而,一些传统的机器学习方法对GPU的利用却很少,这浪费了很多的资源和探索的可能。在这里,我们介绍一个非常优秀的项目——RAPIDS,这是一个致力于将GPU加速带给传统算法的项目,并且提供了与Pandas和scikit-learn一致的用法和体验,非常值得大家尝试。

机器学习是实现人工智能最重要的方法之一,包括深度学习等都属于机器学习中的一种方法。因此,机器学习的应用被认为是实现人工智能应用的重要途径。人工智能的应用目标是使用计算机(机器)来代替或者辅助人工来完成某项任务。机器学习在解决业务问题的应用需要谨慎考虑。本文提供一些步骤可以参考。
在统计学中,普通最小二乘法(OLS)是一种用于在线性回归模型中估计未知参数的线性最小二乘法。这篇博客将简要描述其参数的求解过程。
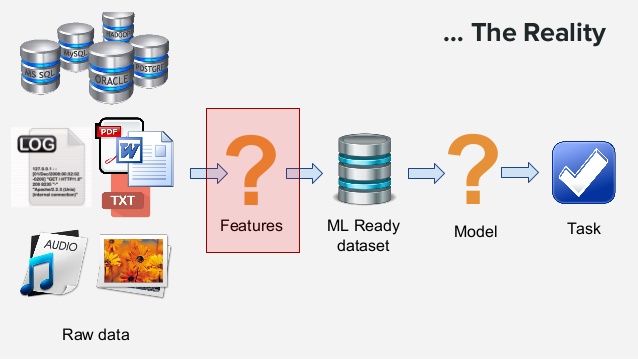
机器学习的特征工程是将原始的输入数据转换成特征,以便于更好的表示潜在的问题,并有助于提高预测模型准确性的过程。找出合适的特征是很困难且耗时的工作,它需要专家知识,而应用机器学习基本也可以理解成特征工程。
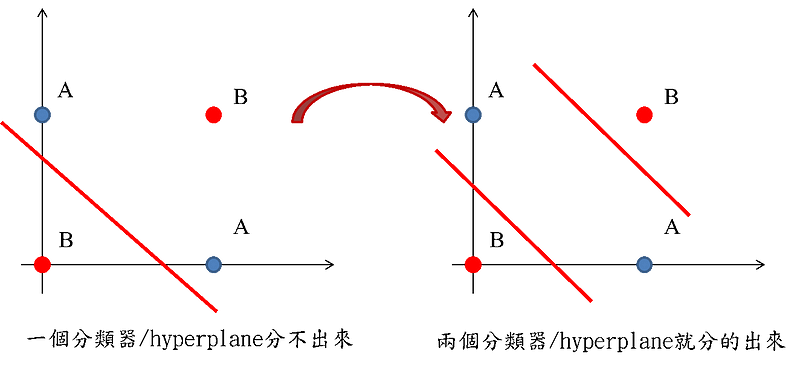
集成学习(Ensemble Learning)是解决有监督机器学习的一类方法,它的思路是基于多个学习算法的集成来获取一个更好的预测结果。本文将介绍相关概念,并对一些注意事项进行总结。




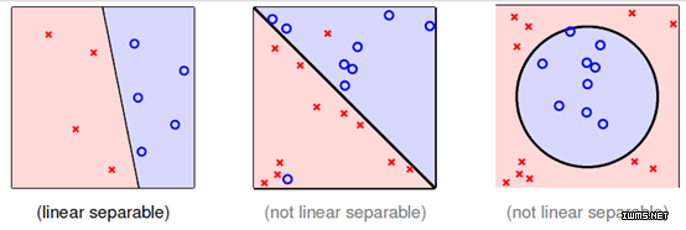
在机器学习或者深度学习中,正则项是我们经常遇到的概念。它对提高模型的准确性和泛化能力非常重要。本文详细描述了正则项的来源以及与其他概念的相关关系。
人工神经网络,简称神经网络,是一种模仿生物神经网络的结构和功能的数学模型或者计算模型。其实是一种与贝叶斯网络很像的一种算法。之前看过一些内容始终云里雾里,这次决定写一篇博客。弄懂这个基本原理,毕竟现在深度学习太火了。