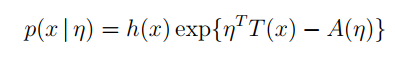
指数分布族(Exponential Family)相关公式推导及在变分推断中的应用
指数分布族(Exponential Family)相关公式推导及在变分推断中的应用
汇总「推断」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
指数分布族(Exponential Family)相关公式推导及在变分推断中的应用
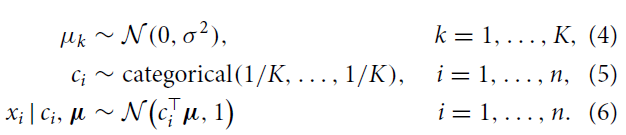
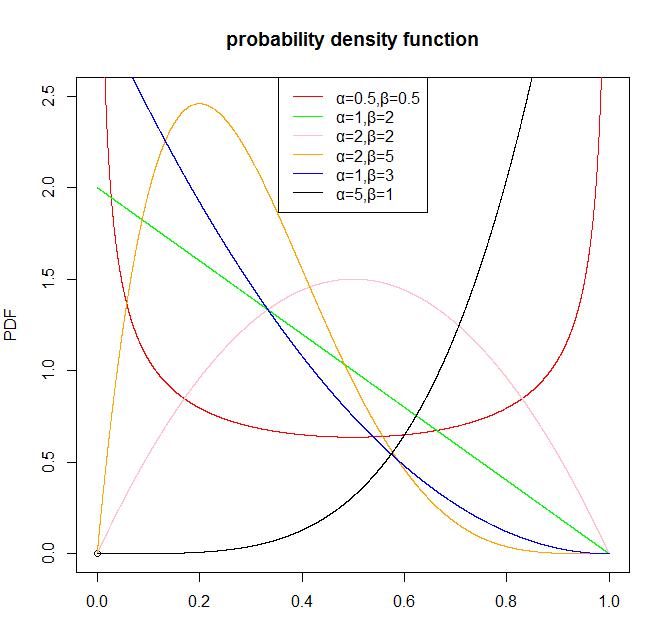
贝塔分布(Beta Distribution)是一个连续的概率分布,它只有两个参数。它最重要的应用是为某项实验的成功概率建模。在本篇博客中,我们使用Beta分布作为描述。
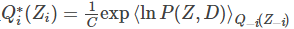
变分贝叶斯是一类用于贝叶斯估计和机器学习领域中近似计算复杂(intractable)积分的技术。它主要应用于复杂的统计模型中,这种模型一般包括三类变量:观测变量(observed variables, data),未知参数(parameters)和潜变量(latent variables)。

EM(expectation-maximization)算法是统计学中求统计模型的最大似然和最大后验参数估计的一种迭代式算法,模型一般是依赖于不可观测的潜在变量。

这个系列的博客来自于 Bayesian Data Analysis, Third Edition. By. Andrew Gelman. etl. 的第五章的翻译。实际中,简单的非层次模型可能并不适合层次数据:在很少的参数情况下,它们并不能准确适配大规模数据集,然而,过多的参数则可能导致过拟合的问题。相反,层次模型有足够的参数来拟合数据,同时使用总体分布将参数的依赖结构化,从而避免过拟合问题。

我们对层次贝叶斯推断的策略与一般的多参数问题一样,但由于在实际中层次模型的参数很多,所以比较困难。在实际中,我们很难画出联合后验概率分布的图形。但是,我们可以使用近似的基于仿真的方法。 在这个部分,我们提出一个联合了分析的和数值的方法从联合后验分布p(θ, φ|y)中获取仿真结果,以 小鼠肿瘤实验的beta-binormial模型为例,总体分布是p(θ|φ),与似然函数p(y|θ)是共轭的。对于很多非共轭层次模型,更高级的算法将在后面叙述。即使针对更复杂的问题,使用共轭分布来获取近似估计也是很有用的。
这个系列的博客来自于 Bayesian Data Analysis, Third Edition. By. Andrew Gelman. etl. 的第五章的翻译。实际中,简单的非层次模型可能并不适合层次数据:在很少的参数情况下,它们并不能准确适配大规 模数据集,然而,过多的参数则可能导致过拟合的问题。相反,层次模型有足够的参数来拟合数据,同 时使用总体分布将参数的依赖结构化,从而避免过拟合问题。本节将讲述互换性并建立层次模型