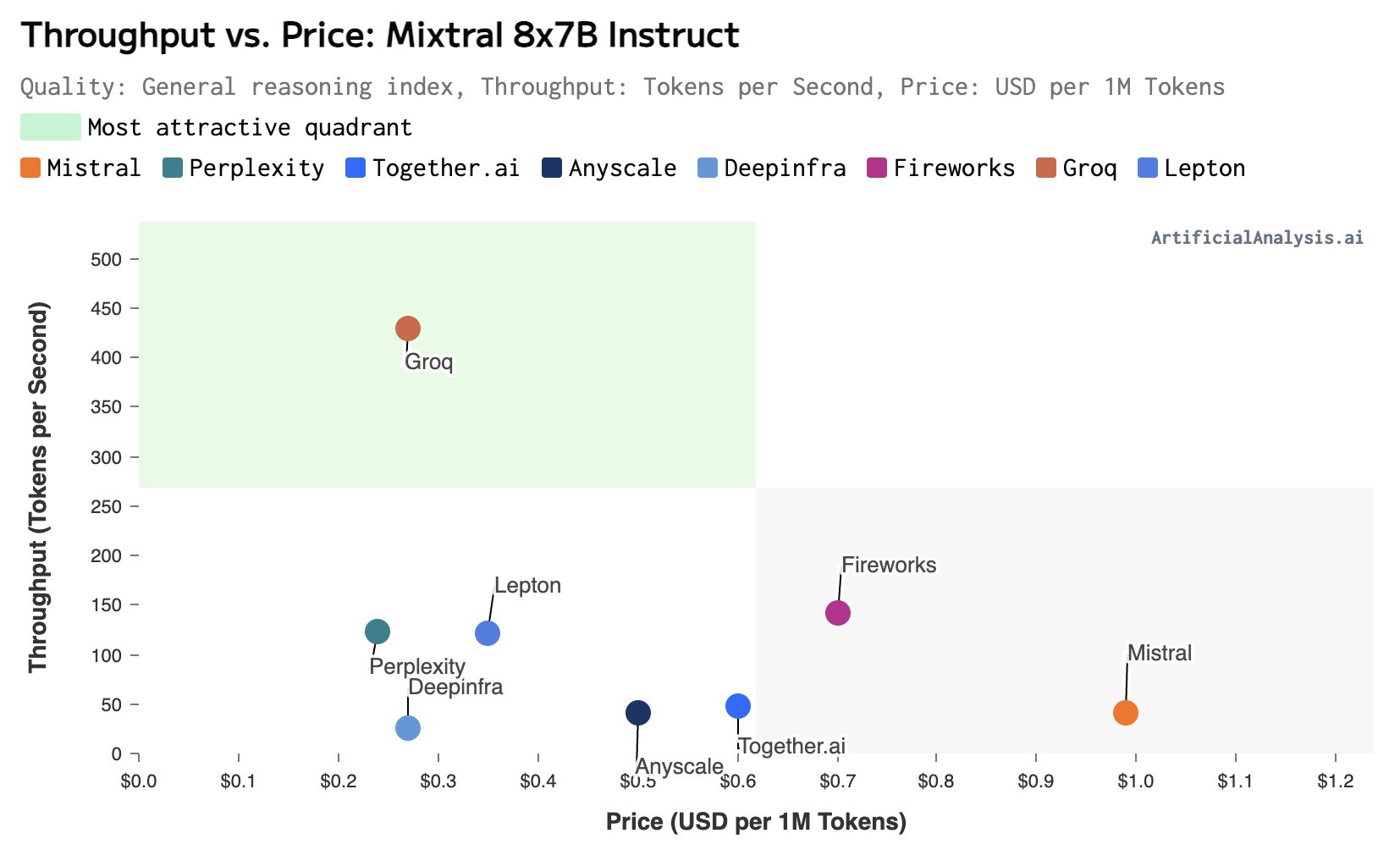
截止目前可能是全球最快的大语言模型推理服务:实机演示Groq公司每秒500个tokens输出的450亿参数的Mixtral 8×7B模型
大模型的推理速度是当前制约大模型应用的一个非常重要的问题。在很多的应用场景中(如复杂的接口调用、很多信息处理)的场景,更快的大模型响应速度通常意味着更好的体验。但是,在实际中我们可用的场景下,大多数大语言模型的推理速度都非常有限。慢的有每秒30个tokens,快的一般也不会超过每秒100个tokens。而最近,美国加州一家企业Groq推出了他们的大模型服务,可以达到每秒接近500个tokens的响应速度,非常震撼。