
大模型评测SimpleVQA全方位深度解析,直击多模态模型“事实幻觉”
随着多模态大语言模型(MLLM)在各个领域的应用日益广泛,一个核心问题浮出水面:我们如何信赖它们生成内容的准确性?当模型需要结合图像和文本进行问答时,其回答是否基于事实,还是仅仅是“看似合理”的幻觉?为了应对这一挑战,一个名为SimpleVQA的新型评测基准应运而生,旨在为多模态模型的事实性能力提供一个清晰、可量化的度量衡。
汇总「多模态评测」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
随着多模态大语言模型(MLLM)在各个领域的应用日益广泛,一个核心问题浮出水面:我们如何信赖它们生成内容的准确性?当模型需要结合图像和文本进行问答时,其回答是否基于事实,还是仅仅是“看似合理”的幻觉?为了应对这一挑战,一个名为SimpleVQA的新型评测基准应运而生,旨在为多模态模型的事实性能力提供一个清晰、可量化的度量衡。
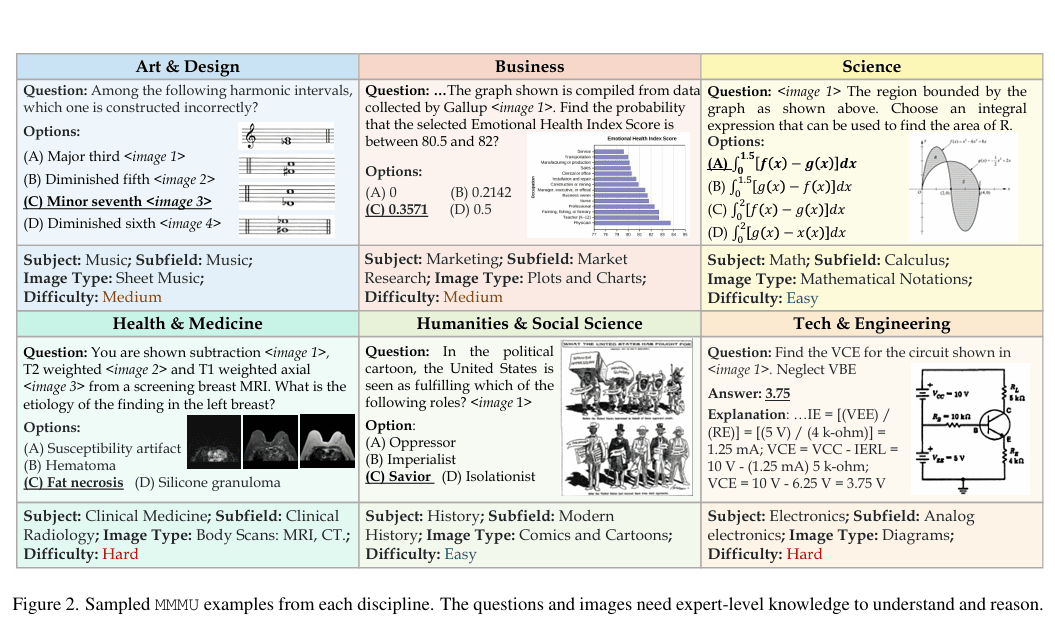
大规模多学科多模态理解与推理基准(MMMU)于2023年11月推出,是一种用于评估多模态模型的复杂工具。该基准测试人工智能系统在需要大学水平学科知识和深思熟虑推理的任务上的能力。与之前的基准不同,MMMU强调跨多个领域的先进感知和推理,旨在衡量朝专家级人工智能通用智能(AGI)的进展。
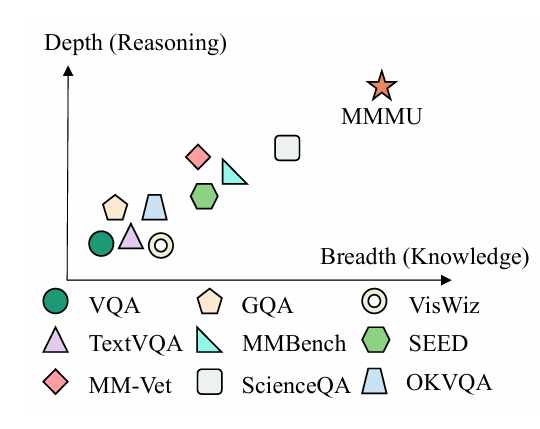
大模型多模态评测基准MMMU(大规模多学科多模态理解和推理基准)是一项旨在评估多模态人工智能模型在复杂跨学科任务中综合能力的测试工具。