
CerebrasAI开源可以在iPhone上运行的30亿参数大模型:BTLM-3B-8K,免费可商用,支持最高8K上下文输入,仅需3GB显存
大模型的进展非常快,但是如何在移动端部署和使用依然是一个非常大的挑战。今天,CerebrasAI联合Opentensor一起开源了一个30亿参数规模的模型BTLM-3B-8K,官方宣称其性能接近70亿参数规模的大模型,但是运行的资源却很低,最低量化版本只需要不到4GB显存即可。
汇总「模型压缩」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
大模型的进展非常快,但是如何在移动端部署和使用依然是一个非常大的挑战。今天,CerebrasAI联合Opentensor一起开源了一个30亿参数规模的模型BTLM-3B-8K,官方宣称其性能接近70亿参数规模的大模型,但是运行的资源却很低,最低量化版本只需要不到4GB显存即可。

大模型虽然效果很好,但是对资源的消耗却非常高。更麻烦的其实不是训练过程慢,而是峰值内存(显存)的消耗直接决定了我们的硬件是否可以来针对大模型进行训练。最近LightningAI官方总结了使用Fabric降低大模型训练内存的方法。但是,它也适用于其它场景。因此,本文总结一下相关的方法。
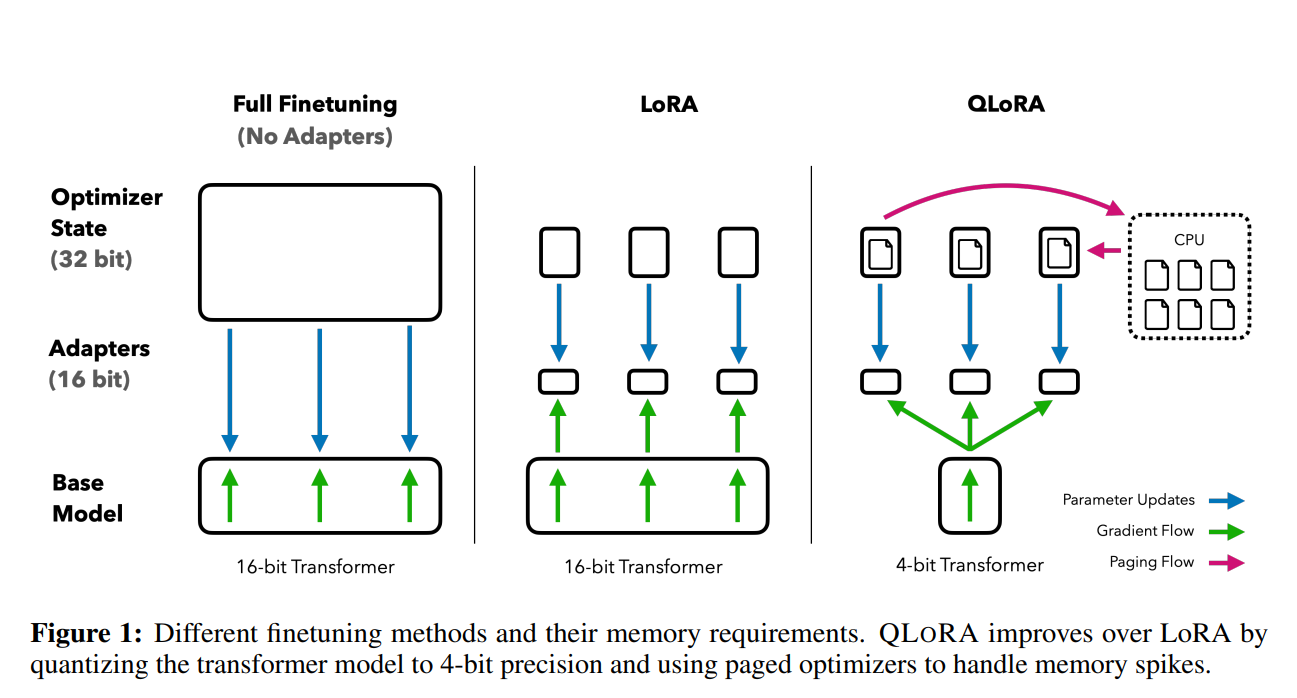
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,不过根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!