阿里巴巴的第二代通义千问可能即将发布:Qwen2相关信息已经提交HuggingFace官方的transformers库
------------2023年1月31日更新------------ 在HuggingFace上发现了一个可能是5亿参数规模的Qwen2模型,其名称是0.5B,这意味着可能有一个仅需1GB显存就能允许的Qwen2模型。
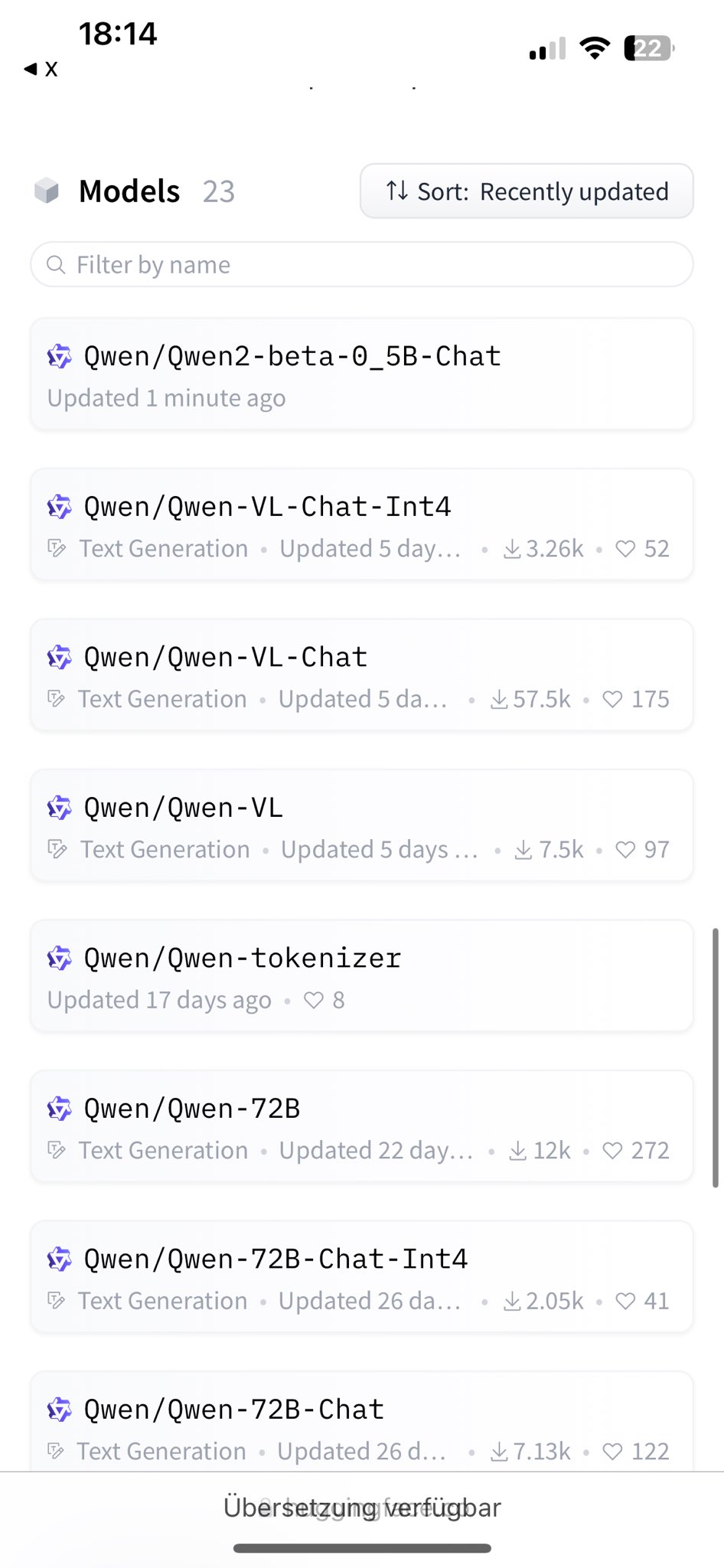
------------2023年1月30日更新------------ 有用户发现Leaderboard上有Qwen2的模型在测试,包括Qwen2-14B、Qwen2-72B,这意味着第二代的Qwen模型至少已经有70亿参数、140亿参数和720亿参数三个不同规模版本。
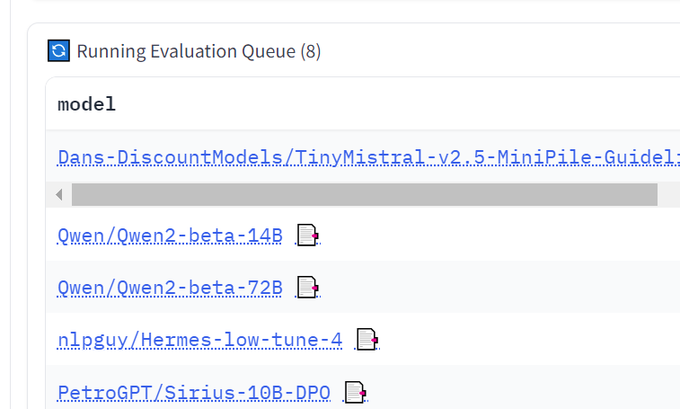
------------2023年1月21日更新------------ Qwen团队成员在推特回复Qwen2目前只有beta,可能在下个月初发布。
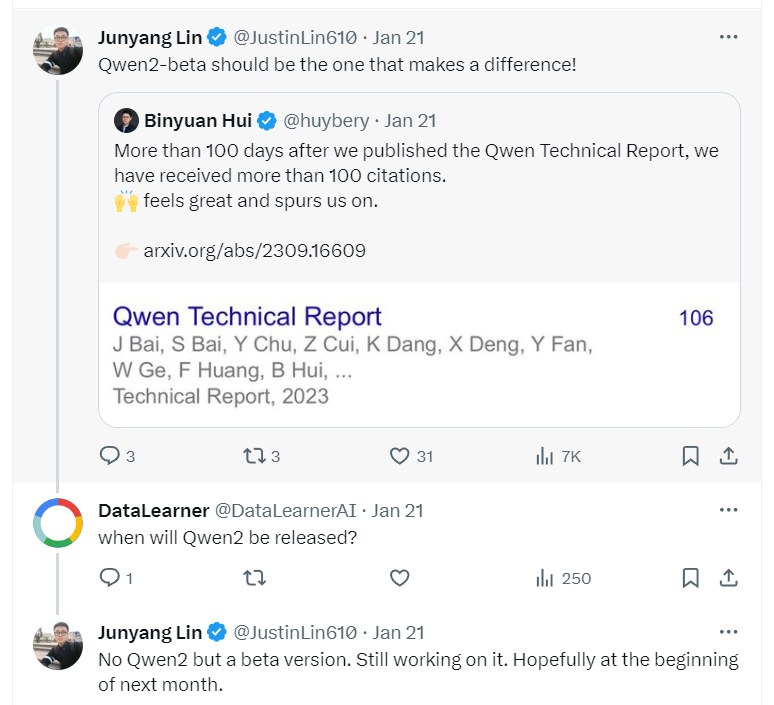
------------2023年1月20日更新------------ Qwen团队成员在推特回复Qwen2的水平会超过GPT-3.5。
通义千问是阿里巴巴开源的一系列大语言模型。Qwen系列大模型最高参数量720亿,最低18亿,覆盖了非常多的范围,其各项评测效果也非常好。而昨天,Qwen团队的开发人员向HuggingFace的transformers库上提交了一段代码,包含了Qwen2的相关信息,这意味着Qwen2模型即将到来。

从提交的代码信息看,Qwen2系列模型包含了很多不同的尺寸,每一个参数规模的模型都包含基座模型和聊天对齐的chat版本。而目前md文件透露的信息看,70亿参数规模的Qwen2-7B-beta和Qwen-7B-Chat-beta是最早发布的第二代Qwen模型。
此外,关于Qwen2的一些模型架构技术信息如下:
-
Transformer Architecture with SwiGLU activation: 不多说,最主流的transformer架构,不变。但是,SwiGLU激活函数是GLU变体,可以让模型学习表达更加复杂的模式。
-
QKV bias:在Transformer模型中,Q、K、V分别代表查询(Query)、键(Key)和值(Value)。这些向量是通过输入向量与对应的权重矩阵相乘得到的。QKV bias表示在计算Q、K、V时添加可学习的偏置项。
-
GQA:Grouped-query attention,它是一种插值方法,介于多查询和多头注意力之间,可以在保持接近多头注意力的质量的同时,达到与多查询注意力相当的速度。
-
Mixture of SWA and Full Attention: SWA指的是Sliding Window Attention,是一种注意力模式,用于处理长序列输入的问题。而full attention则是传统的注意力机制,考虑序列中所有元素的交互。这里的mixture可能指的是这两种注意力机制的结合使用。
-
Improved Tokenizer Adaptive to Multiple Natural Languages and Code: 这说明模型使用了一种改进的分词器,它不仅适用于多种自然语言,还能处理代码。在自然语言处理和编程语言处理中,分词器用于将文本分解成更小的单位(如词、字符或其他符号),这是理解和处理文本的基础步骤。
此外,配置文件透露的信息还包括:词汇表大小151936,这个和第一代模型一样。模型支持的上下文大小4K。最重要的这个模型开源协议依然是Apache 2.0,免费可商用。不过,目前什么时候发布还不确定。但是,Qwen模型的质量值得期待。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
