重磅!MetaAI开源4050亿参数的大语言模型Llama3.1-405B模型!多项评测结果超越GPT-4o,与Claude-3.5 Sonnet平分秋色!
Llama系列大语言模型是由MetaAI开源的一系列大语言模型。作为最早开源的大语言模型,Llama系列对大模型开源社区的推动有目共睹。而现在MetaAI开源Llama3.1系列模型,其中包括迄今为止最大规模的开源大语言模型Llama3.1-405B,参数规模达到了4050亿!其多项评测结果超过GPT-4、GPT-4o模型,与Claude3.5-Sonnet几乎有来有回!

Llama3.1系列模型简介
Llama3.1系列模型是Llama3系列模型继续训练的结果,包含3个不同参数规模的版本,分别是80亿参数规模的Llama3.1-8B、700亿参数规模的Llama3.1-70B和4050亿参数规模的Llama3.1-405B。这三个不同规模的模型训练数据量都达到了15万亿tokens。上下文长度均为128K。
这里15万亿数据来自公开可用数据集,而微调数据集除了公开数据外,还包含了2500万合成的数据
Llama3.1模型支持多个不同的语种,但是仅支持文本输入和输出。Llama3.1系列模型依然是自回归架构的语言模型。其微调版本的模型做过有监督微调和RLHF训练。该模型支持英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。从上表也可以看出,Llama3.1系列模型支持代码输出。
Llama3.1系列模型评测结果
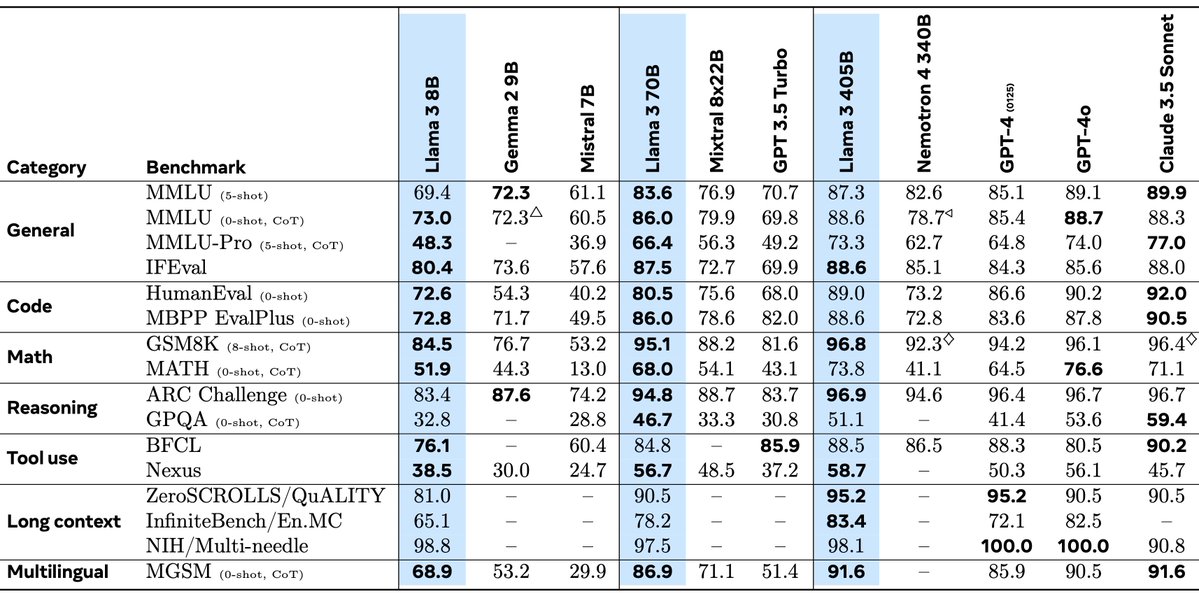
官方公布了Llama3.1系列模型的评测结果,从结果看,Llama3.1系列模型相比此前的Llama3系列模型提升似乎不明显。以80亿参数的Llama3.1-8B为例,其MMLU、ARC-Challenge、BoolQ得分几乎没有变化。但是在部分评测中如CommonSenseQA、BIG-Bench Hard有少许提升。
而最大规模的Llama3.1-405B的评测结果甚至很多方面不如Claude-3.5-Sonnet,十分奇怪。
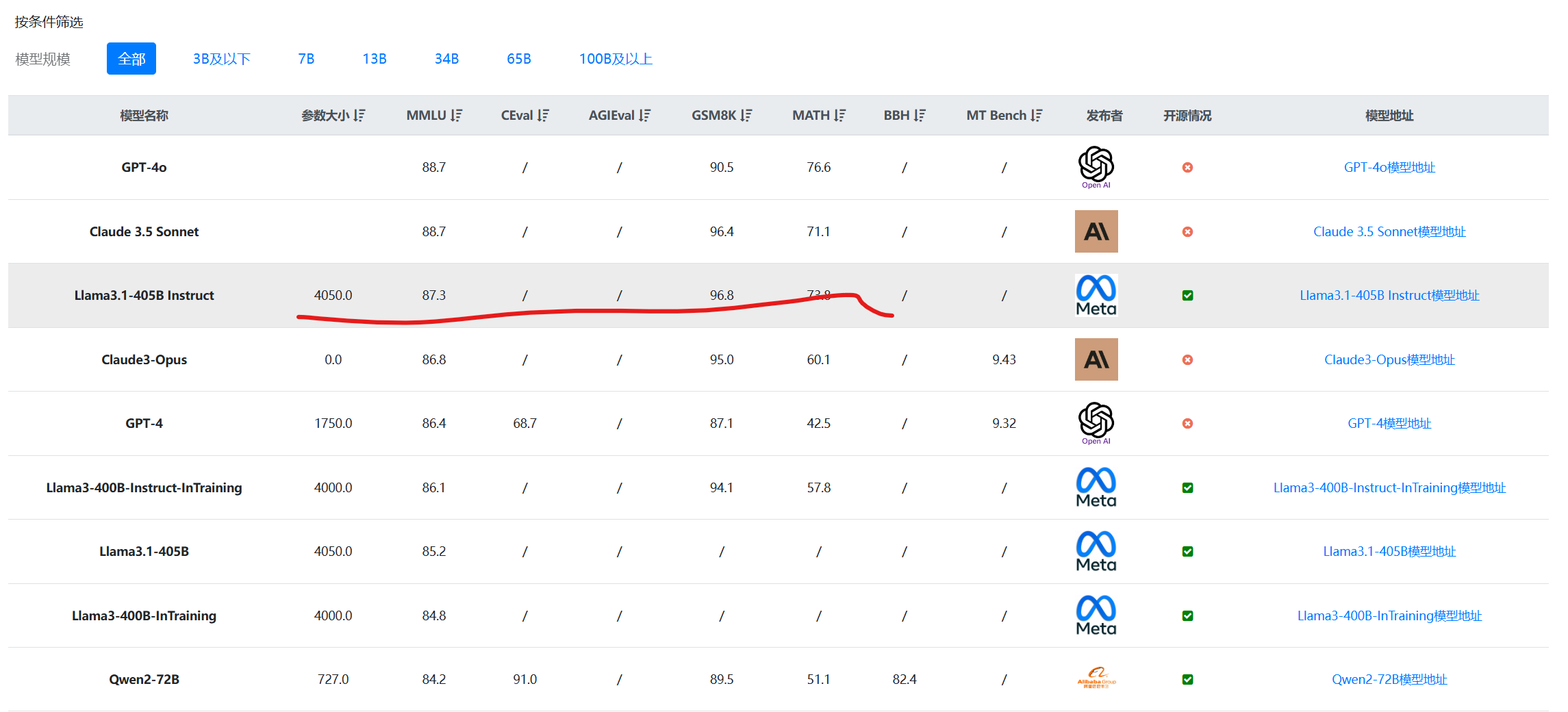
根据DataLearnerAI收集的评测结果看,Llama3.1-405B-Instruct模型在各项评测中排名都很优秀,与GPT-4o、Claude3.5-Sonnet都很接近。
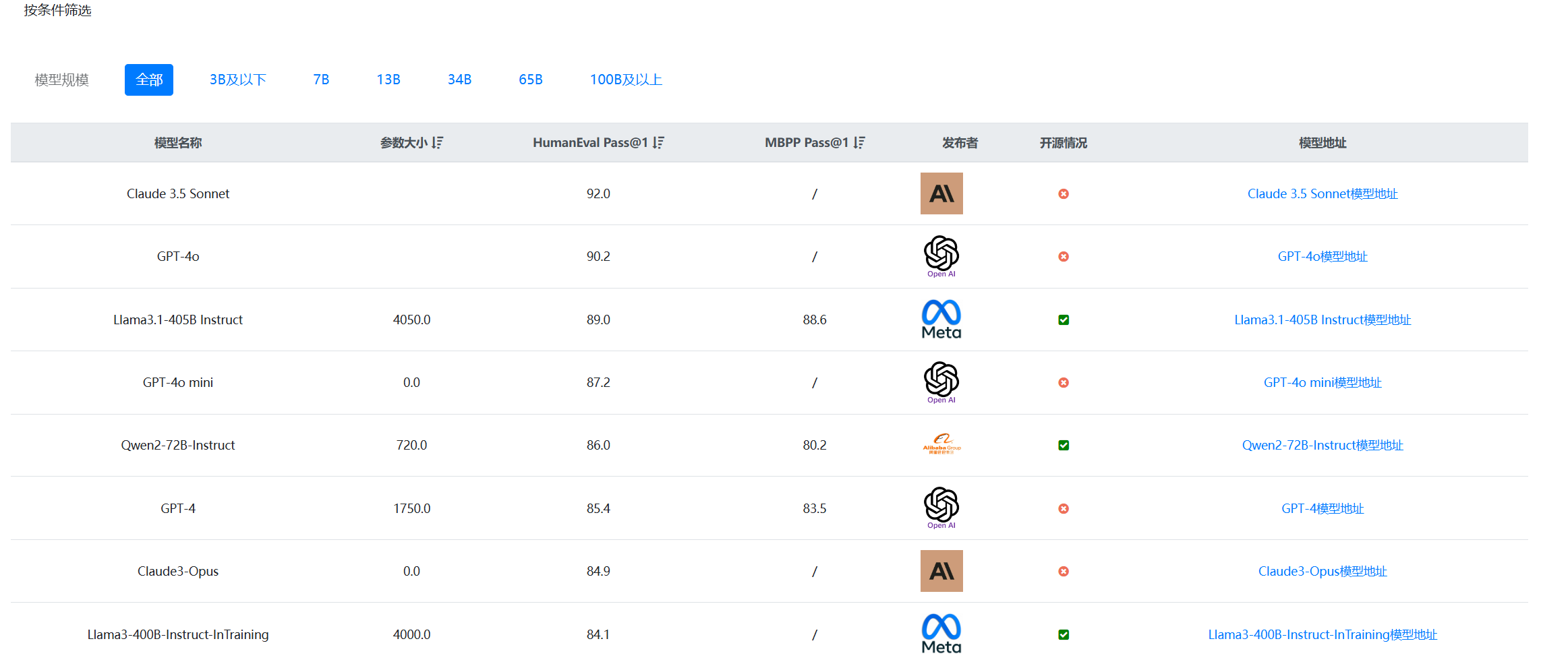
其作为通用大模型,编程水平也是一级棒!
Llama3.1系列模型的训练成本
MetaAI一如既往的公布了Llama系列的训练时间和硬件信息,这一点也比较少见。如下表所示:
Llama3.1系列模型的开源地址
Llama3.1系列模型的开源协议是允许商用的,包括4050亿参数规模的Llama3.1-405B,但是使用的时候必须显著提示“Built with Llama”。此外,月活用户超过7亿,必须向Meta申请额外许可。但是,对于我们影响最大的还是该协议遵守贸易合规,这意味着受到制裁的企业可能无法使用。
Llama3.1系列模型的开源地址等其它信息参考DataLearnerAI大模型信息卡:
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
