OpenAI内部通用大模型已经可以拿到国际数学奥利匹克竞赛金牌:AI推理能力已经接近人类顶级水平
几个小时前,OpenAI的研究人员披露,其一款内部实验性的大语言模型,在模拟的国际数学奥林匹克(International Math Olympiad,IMO)竞赛2025中取得了金牌水平的成绩。这是一个里程碑式的突破,因为IMO被认为是衡量创造性数学推理能力的巅峰,远超以往任何AI基准测试。这项成就并非通过专门针对数学能力对大模型进行定制的方法实现,而是源于通用人工智能研究的根本性突破,尤其是在处理难以验证的任务和长时间推理方面。

OpenAI大模型数学推理能力的进化:从解题到证明
国际数学奥林匹克(IMO)长期被视为 AI 推理能力的试金石。其挑战性在于:
- 超长思维链:竞赛中,人类选手需在9小时内(两场各4.5小时)完成6道原创证明题,平均单题耗时约100分钟,远超当前大模型常见任务(如GSM8K约0.1分钟)。
- 严格约束:闭卷、纯自然语言推导、多页严谨证明——禁用计算工具与形式化验证器(如Lean)。这意味着模型不能使用外部工具。
- 模糊评估:答案并非单一数字,而是需要专家评审数小时才能鉴定的主观性证明。
OpenAI本次公布的实验性模型,正是在严格复现上述环境下进行的测试。最终,该模型在与人类选手相同的规则下解决了6道题中的5道(P1-P5),其证明过程由三位前IMO奖牌得主独立评审并达成共识,最终得分35/42,足以获得金牌(2024年金牌分数线为32分)。
此项成就的核心在于其评估标准的高度和复杂性。与以往的AI基准测试相比,IMO带来了质的飞跃:
- 推理时长的跨越:AI模型的能力已从处理几秒或几分钟内可解决的问题(如GSM8K、MATH基准),跃升至需要以小时为单位进行持续、深度思考的IMO难题。
- 任务性质的转变:过去的数学基准大多要求模型输出一个标准答案。而IMO要求的是长达数页、逻辑严谨、使用自然语言书写的完整证明过程。这要求模型不仅要找到答案,更要构建一个能被人类专家认可的、无懈可击的论证体系。
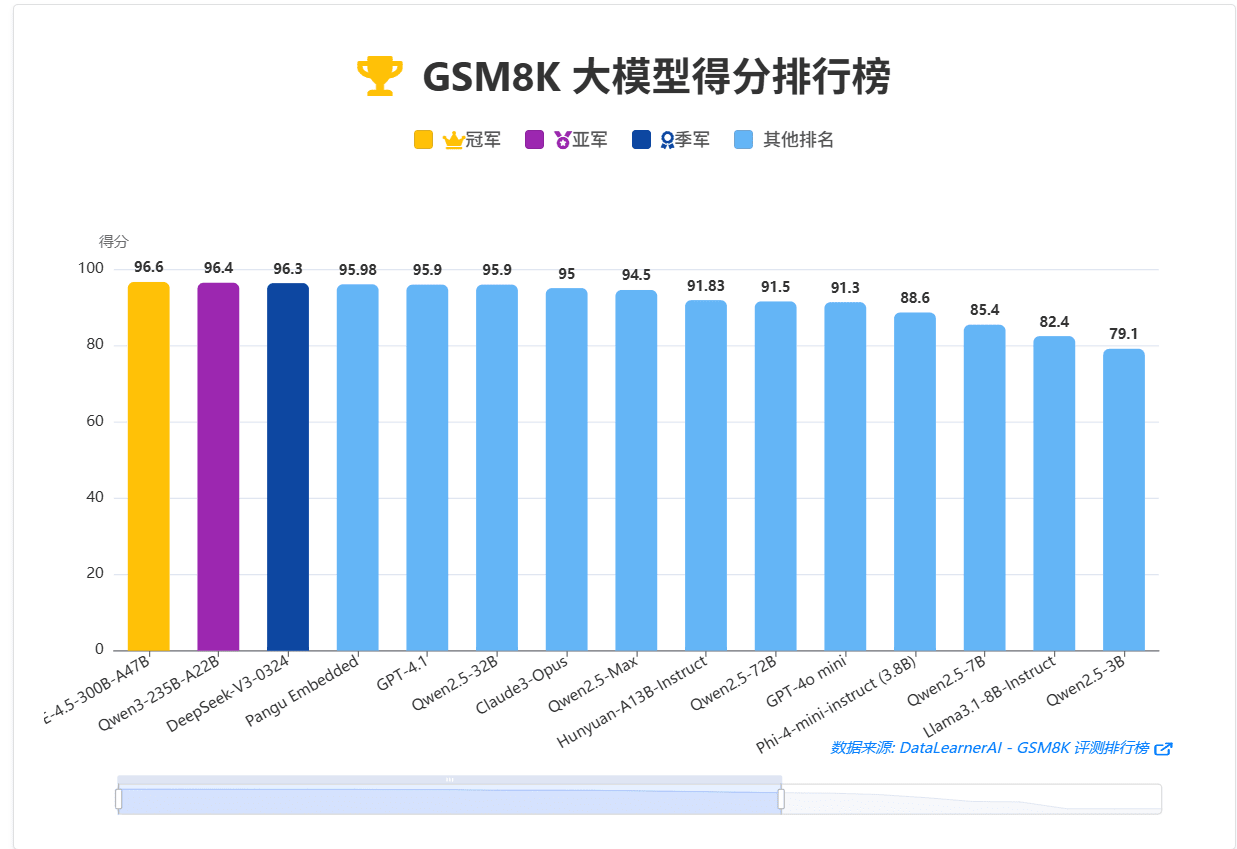
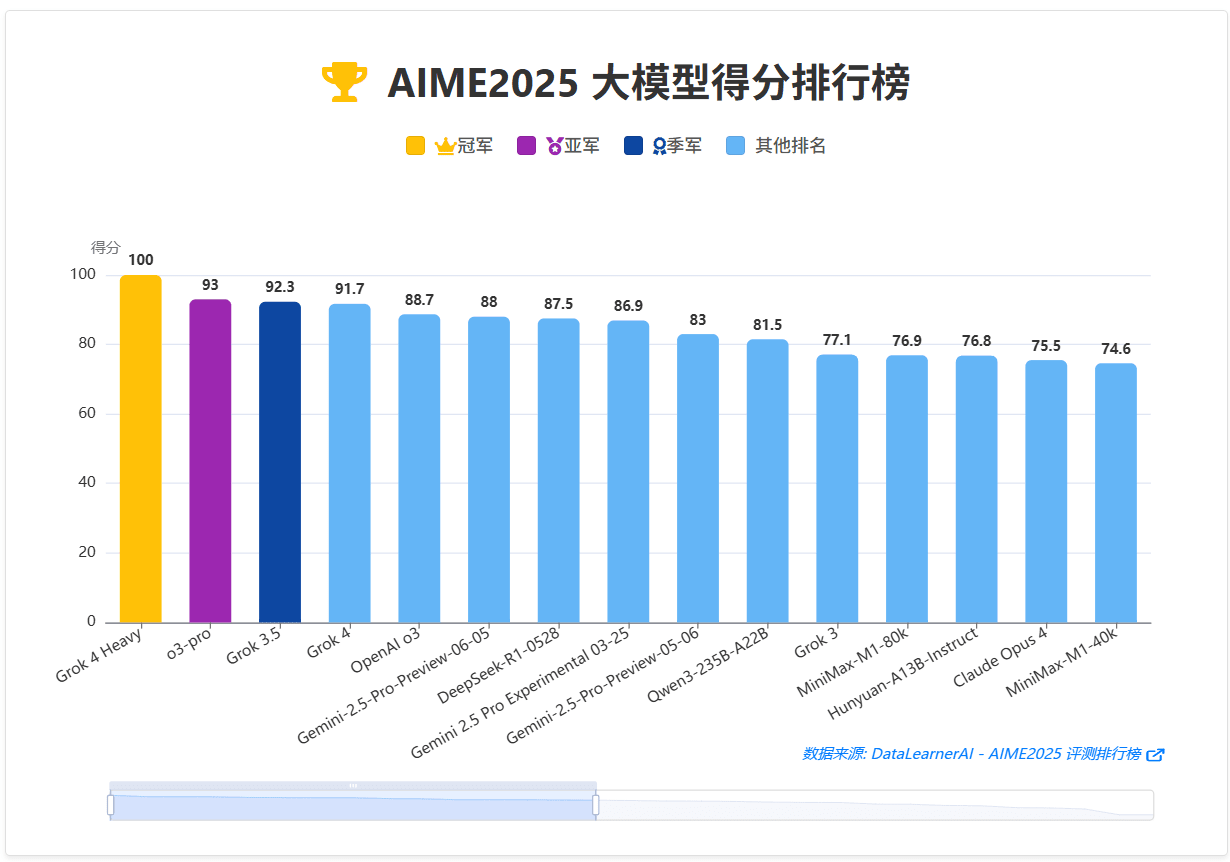
这里,我们也看一下OpenAI大模型解决数学问题的历史飞跃(即平均单题推理时长,大家也可以点击评测基准URL查看我们DataLearnerAI上面这些基准背后模型的水平):
如果大家点进去这些评测其实也可以发现,早期火爆的GSM8K目前很少有新模型再去测试,因为大多数顶尖模型都可以拿到很高的分数,没有区分度。当前AIME还是比较火爆的,但是随着Grok 4 Heavy拿到满分之后,未来应该也会很少人再去测试了。
OpenAI解题的大模型并非专有大模型
OpenAI三位核心研究员在各自的陈述中一致强调,这项成果最重要的部分并非模型在数学上的表现,而是其背后的通用方法论。
这并非一个为IMO量身定制的“偏科”模型,而是一个通用的推理引擎。其突破主要体现在以下方面:
- 通用性 (General-Purpose): Noam Brown特别指出,这不像AlphaGo或Libratus(他之前的作品)那样是为特定任务设计的AI。这是一个通用的推理LLM,其技术可以应用于数学之外的其他领域。
- 处理“难以验证”的任务: IMO证明过程长、逻辑复杂,没有简单的对错答案。Noam和Alex都强调,他们开发了新方法来解决这类奖励信号模糊、难以快速验证的任务。这超越了传统强化学习的范畴,因为传统RL依赖明确奖励信号(如游戏胜负),而IMO证明的评估更为主观。
- 长时间、高效率的“思考”: Noam Brown提到,这个模型可以“思考数小时”,远超之前的模型(o1模型思考几秒,Deep Research模型思考几分钟)。这说明模型具备了进行深度、持久思考的能力和效率。
- 纯自然语言推理: Sheryl强调,模型不依赖任何外部工具,全程使用自然语言进行推理,包括尝试不同策略、观察例子、验证假设等,非常接近人类数学家的思考方式。
这项工作展示了一种不依赖外部形式化工具(如代码解释器或Lean等证明助手),仅通过自然语言进行高级抽象推理的能力。研究院Sheryl也感叹大模型数学能力的提升之快:从GPT-4o在AIME测试中12%的水平,到如今的IMO金牌,仅仅过去了约15个月。
该模型不是GPT-5,仅为实验性质的模型
这个IMO模型是一个前沿的实验品,并非GPT-5,并且在未来数月内不会将同等级别的数学能力集成到公开发布的产品中。这揭示了其前沿研究与商业产品之间存在显著的技术代差和发布时间差。但是官方也公布了该模型的实际证明结果,大家可以去GitHub上看:https://github.com/aw31/openai-imo-2025-proofs/
尽管如此,Alexander也确认了一个好消息:GPT-5即将发布。
当AI的能力从“略低于人类专家”跨越到“略高于人类专家”的门槛时,其角色将从一个辅助工具转变为一个潜在的原创性研究伙伴。正如Sheryl和Noam所展望的,AI未来将有能力推导新的数学定理,或为科学发现做出实质性贡献。
过去,顶级AI的竞争很大程度上围绕着MMLU、GSM8K等标准化基准展开。IMO金牌的达成,为这场竞赛树立了一个新的、更高的标杆。未来的竞争焦点可能会从“谁的模型知识更广、答题更快”,转向“谁的模型能针对复杂、开放、专业的问题进行更深入、更可靠的创造性推理”。这要求AI公司展示其在解决现实世界中那些没有标准答案的难题上的能力。
总而言之,OpenAI的IMO成果不仅是一个技术里程碑,更是一个清晰的信号:前沿AI的发展重心正在从广泛的知识覆盖,深化到专精的、可验证的、类似人类的创造性推理能力。这不仅是对模型能力的重新定义,也为整个行业的演进方向设定了新的航标。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
