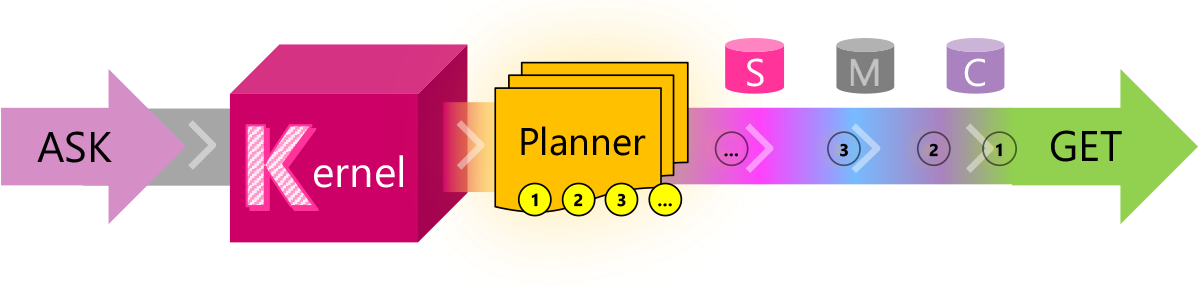
看特斯拉前AI总监、OpenAI前知名研究员Andrej Karpathy如何看AI大模型编程(Claude Code这样的工具):AI Agent正在重塑编码工作流,2026年的软件工程大变革
本文整理了 Andrej Karpathy 在 2025 年底关于 AI Agent 编程的核心观点。基于其使用 Claude Code 等大模型的真实工程经验,Karpathy 认为软件工程正从“手动编码”转向“由 AI Agent 执行、人类定义目标与约束”的新范式。文章同时分析了 AI Agent 在效率提升之外带来的工程风险、技能退化与内容质量问题,并指出 2026 年将是行业系统性消化 AI Agent 能力的关键一年。