
重磅!Kimi K2.5发布,依然免费开源!原生多模态MoE架构,全球最大规模参数的开源模型之一,官方评测结果比肩诸多闭源模型!可以驱动100个子Agent执行!
2026年1月27日,月之暗面(Moonshot AI)发布新一代模型Kimi K2.5。根据官方说明,这是Kimi K2的后续版本,目前已通过Kimi.com网页端和App向用户推送。该模型同步上线Kimi API开放平台及编程助手Kimi Code,模型权重与相关代码也在Hugging Face开源。
A curated list of original AI and LLM articles related to "多模态大模型", updated regularly.
2026年1月27日,月之暗面(Moonshot AI)发布新一代模型Kimi K2.5。根据官方说明,这是Kimi K2的后续版本,目前已通过Kimi.com网页端和App向用户推送。该模型同步上线Kimi API开放平台及编程助手Kimi Code,模型权重与相关代码也在Hugging Face开源。

就在刚才,智谱推出了两个语音识别模型:闭源的 GLM-ASR 和开源的 GLM-ASR-Nano-2512。与过去他们更多关注通用大模型或多模态模型不同,这次聚焦的是语音转文字(ASR)任务,尤其面向中文语境、方言与复杂环境。以下是对这两款模型已知公开资料的整理与分析。

DeepSeek AI团队重磅推出DeepSeek-OCR,该模型不仅在文档提取上达到了行业领先水平,更通过创新的视觉压缩技术,将长上下文处理效率提升了 10 倍以上。根据测算,在A100-40G的一个GPU上,它每天可以将20万页的文档图像数据转为Markdown文本!

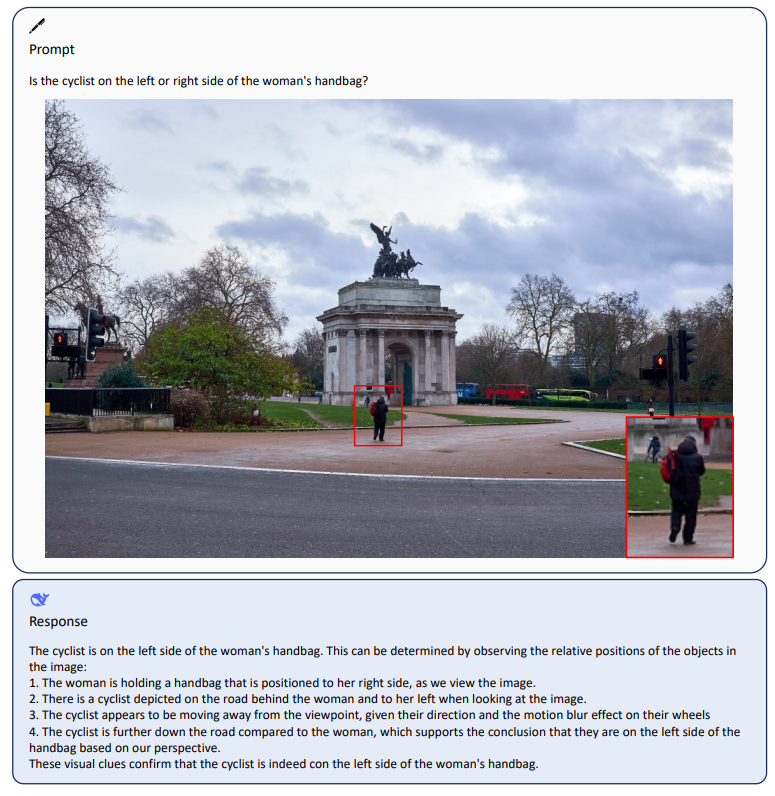
GLM-4.1V-Thinking是智谱AI(Zhipu AI)与清华大学KEG实验室联合推出的多模态推理大模型。这款模型并非简单的版本迭代,而是通过一个以“推理为中心”的全新训练框架,旨在将多模态模型的能力从基础的视觉感知,推向更复杂的逻辑推理和问题解决层面。多模态理解能力接近720亿的Qwen2.5-VL-72B。

继Gemma系列模型发布并迅速形成超过1.6亿次下载的繁荣生态后,Google再次推出了其在端侧AI领域的重磅力作——Gemma 3n。这款模型并非一次简单的迭代,而是基于全新的移动优先(mobile-first)架构,旨在为开发者提供前所未有的设备端多模态处理能力。Gemma 3n的定位是成为一款高效、强大且灵活的开源模型,直接与设备端AI领域的其他先进模型(如Phi-4、Llama系列的小参数版本)竞争,其核心特性在于原生支持图像、音频、视频和文本输入。
Qwen2.5-Omni-7B是阿里巴巴发布的一款端到端全模态大模型,支持文本、图像、音频、视频(无音频轨)的多模态输入与实时生成能力,可同步输出文本与自然语音的流式响应。目前,该模型在HuggingFace以Apache2.0协议开源,可以免费商用授权。
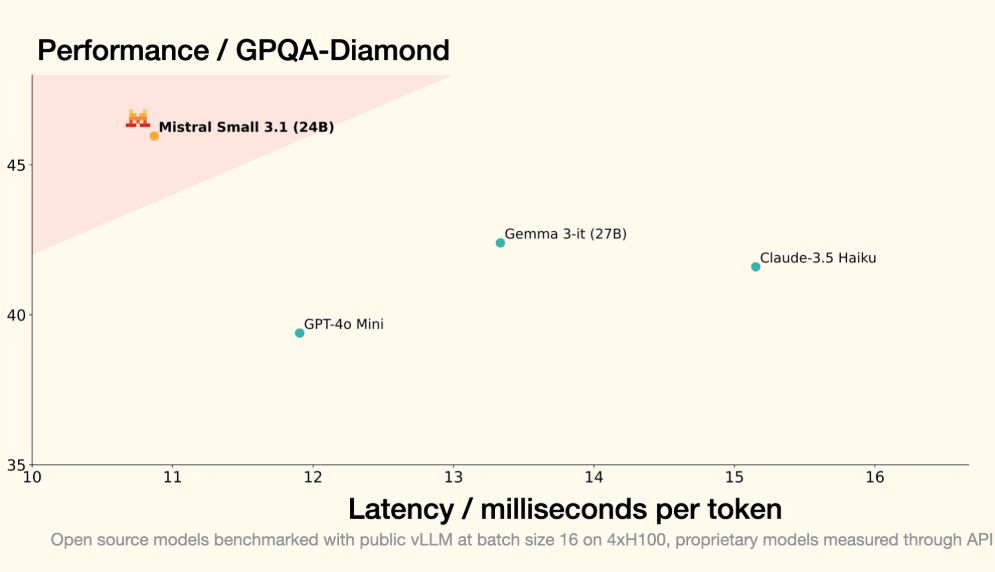
欧洲大模型之光MistralAI开源了2个全新的多模态大模型,即Mistral-Small-3.1-24B基座版本和指令微调版本。这两个大模型均以Apache2.0协议开源,因此可以完全免费商用。而官方也给出了这个模型在多个评测集上的效果,高于GPT-4o-mini和Gemma 3 27B。因为其参数规模较小,推理速度可以达到每秒150个tokens,同时支持多种语言,是一个非常值得关注的小而美的多模态大模型。
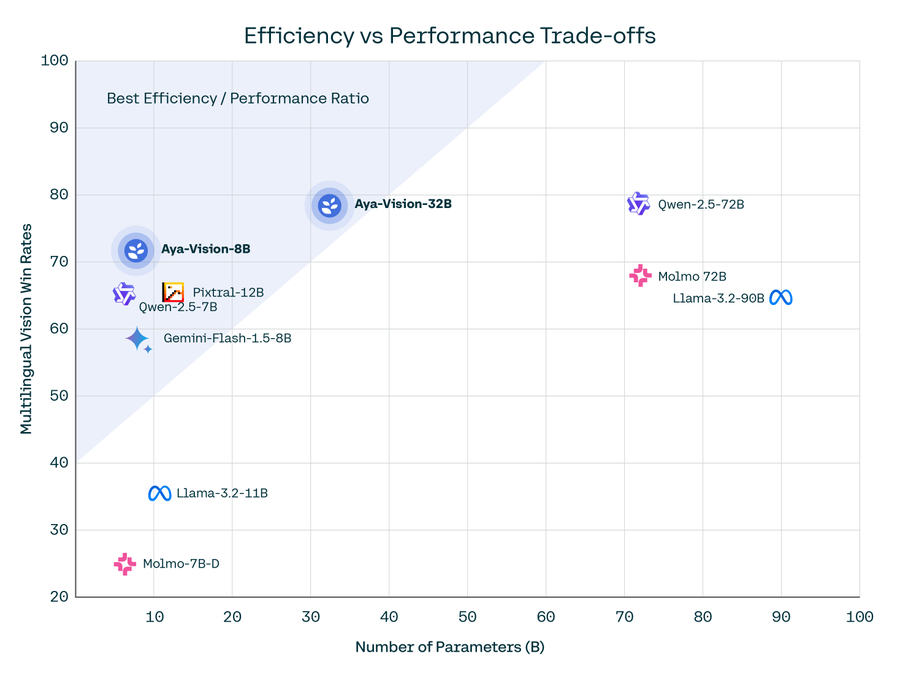
Cohere For AI 推出了 Aya Vision 系列,这是一组包含 80 亿(8B)和 320 亿(32B)参数的视觉语言模型(VLMs)。这些模型针对多模态AI系统中的多语言性能挑战,支持23种语言。Aya Vision 基于 Aya Expanse 语言模型,并通过引入视觉语言理解扩展了其能力。该系列模型旨在提升同时需要文本和图像理解的任务性能。

OpenAI在GPT-4发布一年之后再次更新其基础模型,发布最新的GPT-4o模型,其中o代表的是omni,即“全能”的意思。GPT-4o相比较此前最大的升级是对多模态的支持以及性能的提升。GPT-4o在各方面比GPT-4更强,但是速度更快,开发者接口的价格则只有一半!
深度求索是著名量化机构幻方量化旗下的一家大模型初创企业,成立与2023年7月份。他们开源了很多大模型,其中编程大模型DeepSeek-Coder系列获得了非常多的好评。而在今天,DeepSeek-AI再次开源了全新的多模态大模型DeepSeek-VL系列,包含70亿和13亿两种不同规模的4个版本的模型。

Google Gemini是Google最新发布的大模型系列。这是一系列的多模态的大模型,谷歌官方宣布在各项评分中Gemini超过了GPT-4V。但是,谷歌的宣传视频过于夸张被很多人质疑造假嫌疑,导致被全网嘲讽。而今天,Google官方的Gemini多模态接口开放,DataLearnerAI第一时间申请测试,结果让人惊喜。
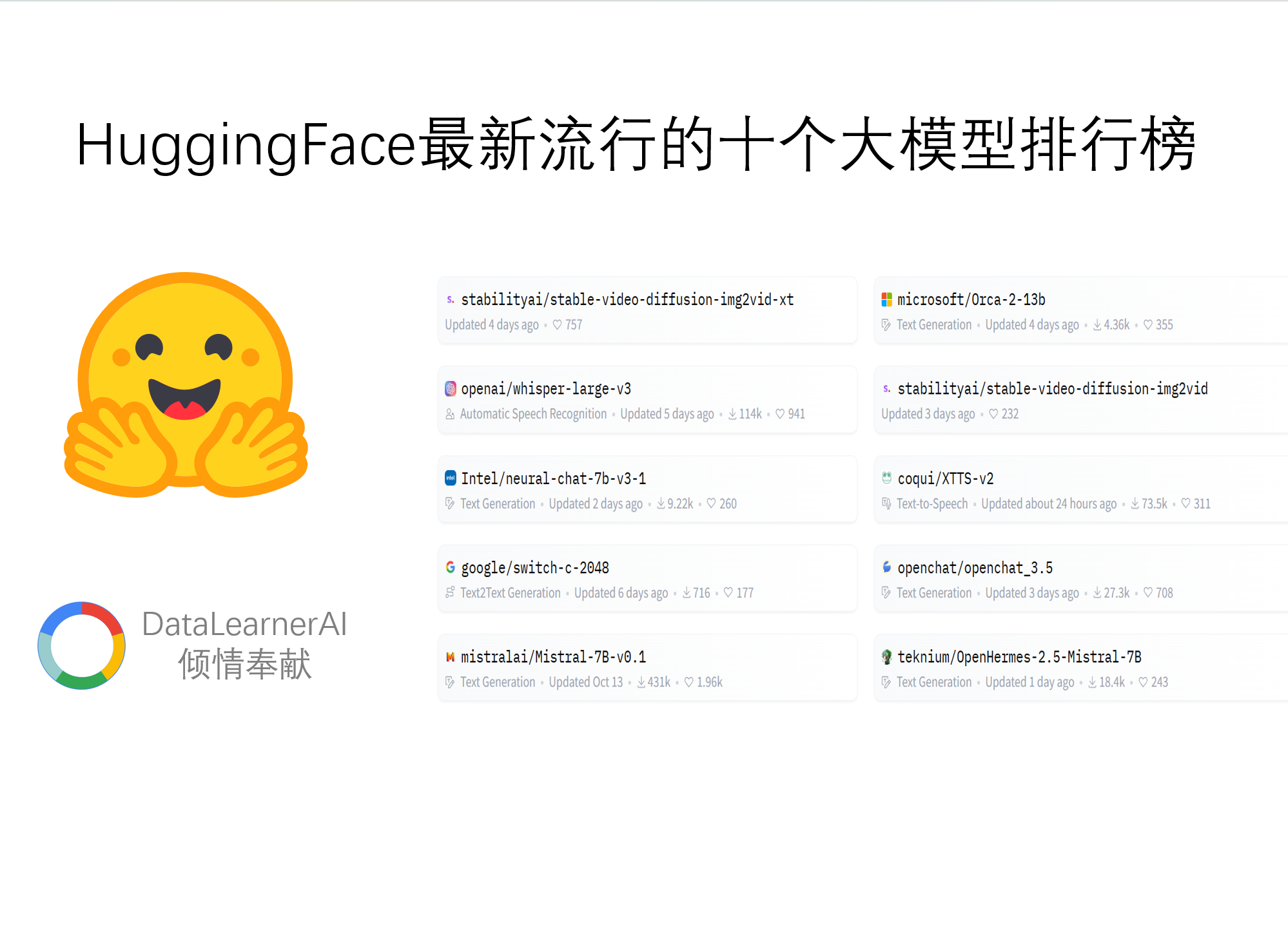
在本周,HuggingFace最流行的十个大模型多模态模型占了4个,包括StabilityAI最新开源的文本生成视频大模型Stable Video Diffusion、Coqui最新的语音合成大模型XTTS第二代等都吸引了大量的关注多。而大语言模型中,谷歌开源了2022年就已经发布的Switch大模型,该模型号称参数可以达到上万亿,也是十分有意思。
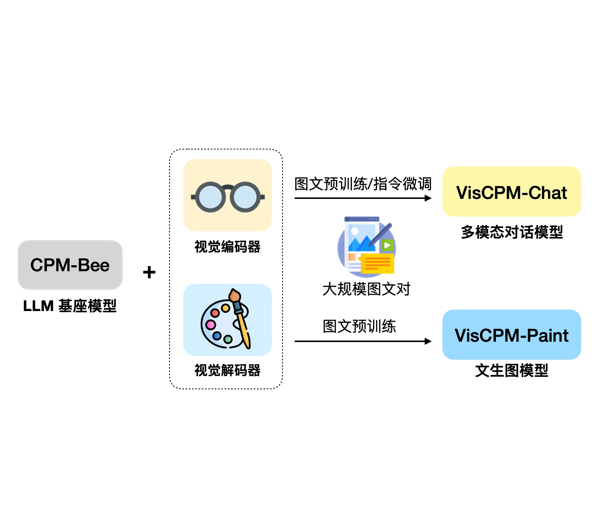
大模型的发展正在从单纯的语言模型向多模态大模型快速发展。尽管GPT-4号称也是一个多模态大模型,但是受限于GPU资源,GPT-4没有开放任何多模态的能力(参考:https://www.datalearner.com/blog/1051685866651273 )。目前大家所能接触到的多模态大模型很少。今天,清华大学NLP小组带来了新的选择,发布了VisCPM系列多模态大模型。VisCPM系列包含2类多模态大模型,分别针对多模态对话和文本生成图片进行优化。
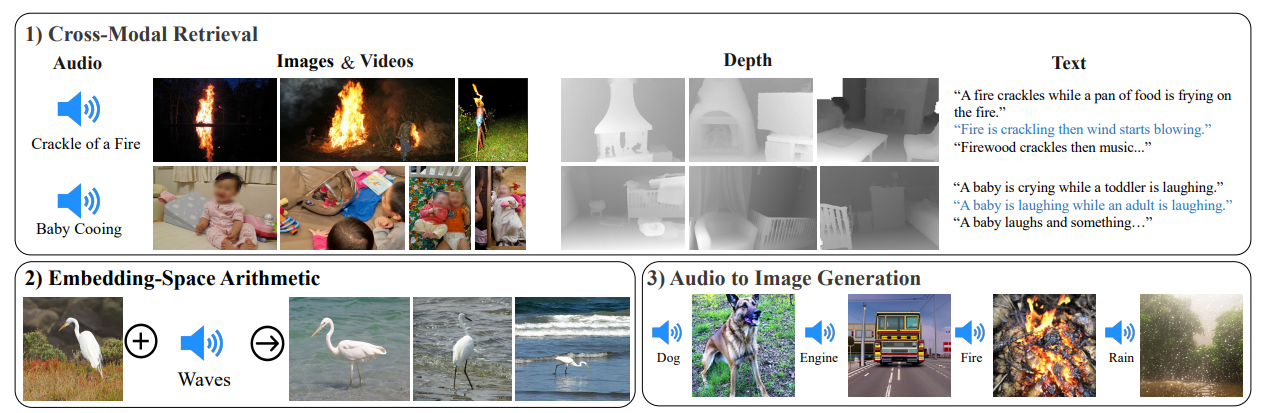
当前,大语言模型主要是基于生成式自然语言处理模型为主。少部分多模态模型可以处理文本、图片和视频信息。但是,AI模型目前还无法像人类一样接受周围的多模态信息进行处理,如图像、文本、声音等。但是,昨天MetaAI发布了一个可以听说读写的AI大模型ImageBind,它可以同时处理6种数据,并输出。本文将简单介绍一下这个模型。