CohereAI开源了2个Aya Vision多模态大模型:80亿和320亿两种规格多模态大模型,评测结果超越Qwen2.5 72B和Llama 3.2 90B,支持23种语言
622 views
Cohere For AI 推出了 Aya Vision 系列,这是一组包含 80 亿(8B)和 320 亿(32B)参数的视觉语言模型(VLMs)。这些模型针对多模态AI系统中的多语言性能挑战,支持23种语言。Aya Vision 基于 Aya Expanse 语言模型,并通过引入视觉语言理解扩展了其能力。该系列模型旨在提升同时需要文本和图像理解的任务性能。
Aya Vision的主要特点
- 多语言支持:覆盖23种语言,通过数据增强技术提升对弱势语言的性能。
- 多模态能力:支持图像描述生成、视觉问答(VQA)、文本生成以及图像到文本的翻译等任务。
- 模型规模:提供两种配置——Aya Vision 8B 和 Aya Vision 32B,在性能与计算效率之间提供不同的平衡选择。
- 动态图像分辨率处理:自动调整并将高分辨率图像分割为更小的部分,以提取更详细的图像特征。
- Pixel Shuffle Downsampling:通过4倍压缩图像tokens,降低计算成本,同时保留关键信息。
Aya Vision技术架构
Aya Vision 模型采用模块化架构,包含以下组件:
- 视觉编码器:基于 SigLIP2-patch14-384,负责从图像输入中提取视觉特征。
- 视觉语言连接器:将图像特征映射到语言模型的嵌入空间。
- LLM 解码器:8B模型使用经过优化的 Cohere Command R7B,擅长指令跟随;32B模型则使用 Aya Expanse 32B,后者经过多语言多样化数据集的额外训练。
- 训练过程:
- 视觉语言对齐:通过冻结视觉和语言组件,训练视觉语言连接器。
- 监督微调(SFT):在23种语言的多模态任务上联合训练连接器和语言模型。
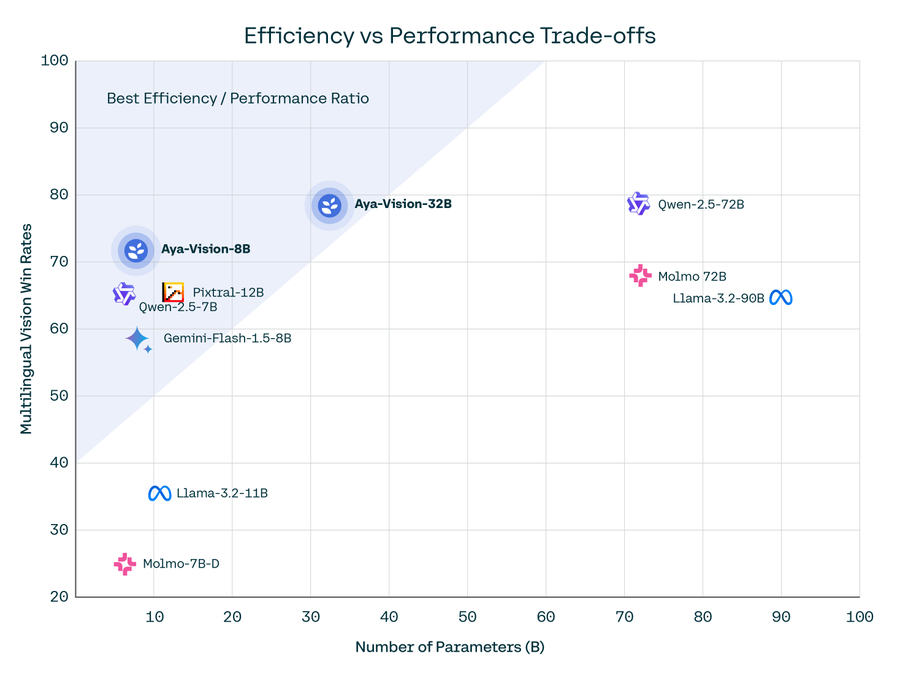
Aya Vision 32B和Aya Vision 8B的评估结果
Aya Vision 在两个多语言基准上进行了评估:
- AyaVisionBench:专为23种语言的视觉语言任务设计的自定义数据集,涵盖图像描述生成、OCR和文档理解等类别。
- mWildVision:Wild Vision Bench 的多语言版本,翻译成了23种语言。
Aya Vision 模型在多种任务和语言上,始终优于更大的模型,例如 Llama-3.2 90B Vision、Molmo 72B 和 Qwen2.5-VL 72B。
5. 开源与社区集成
Aya Vision 8B 和 32B 都以开源权重形式发布在 Hugging Face 上,以支持研究与开发。
- 数据集:AyaVisionBench 和 mWildVision 数据集已公开。
- 社区访问:可通过 WhatsApp 和 Hugging Face Spaces 测试这些模型。
- 代码示例:提供 Colab 笔记本,帮助开发者将这些模型集成到应用中。
不过需要注意的是,这两个开源模型都不是商用授权的,可以用于研究和测试。
Aya Vision 32B模型更多信息参考DataLearnerAI模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/aya-vision-32b Aya Vision 8B模型更多信息参考DataLearnerAI模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/aya-vision-8b
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
