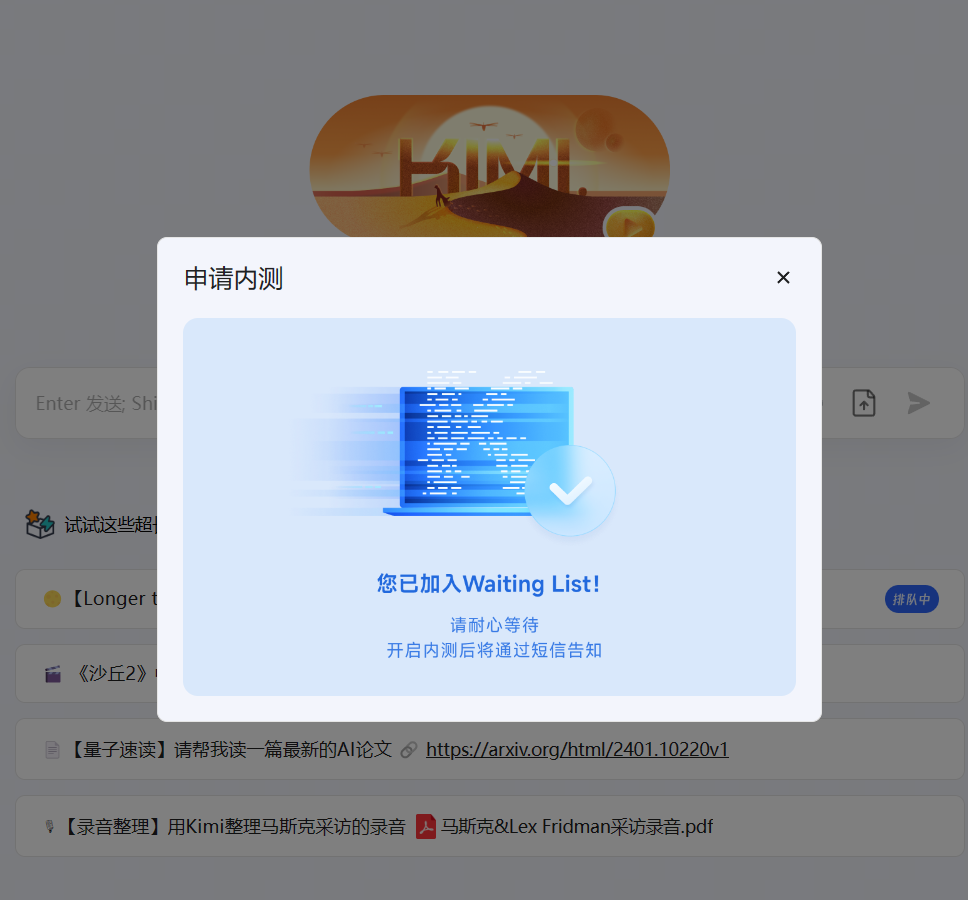
全球首个200万上下文商业产品开始内测!月之暗面Kimi助手开启最长上下文模型内测邀请。
MoonshotAI(月之暗面)是一家中国的大模型初创企业,在2023年4月份成立。其最为著名的产品就是KimiChat,一个完全免费的大模型聊天机器人。就在刚刚,MoonshotAI官方宣布开启200万上下文的KimiChat内测!这应该是全球首个商业产品支持并内测200万上下文输入的模型了!此前其它产品宣布的200万上下文大多数都没有公开商发。
A curated list of original AI and LLM articles related to "Long-Context", updated regularly.
MoonshotAI(月之暗面)是一家中国的大模型初创企业,在2023年4月份成立。其最为著名的产品就是KimiChat,一个完全免费的大模型聊天机器人。就在刚刚,MoonshotAI官方宣布开启200万上下文的KimiChat内测!这应该是全球首个商业产品支持并内测200万上下文输入的模型了!此前其它产品宣布的200万上下文大多数都没有公开商发。

GLM4是智谱AI发布的第四代基座大语言模型,全称General Language Model,最早由清华大学KEG小组再2021年发布。这个基座模型也是著名的开源国产大模型ChatGLM系列的基座模型。本次发布的第四代GLM4的能力相比此前的基座模型提升了60%,已经与世界最强模型Gemini Ultra和GPT-4接近!
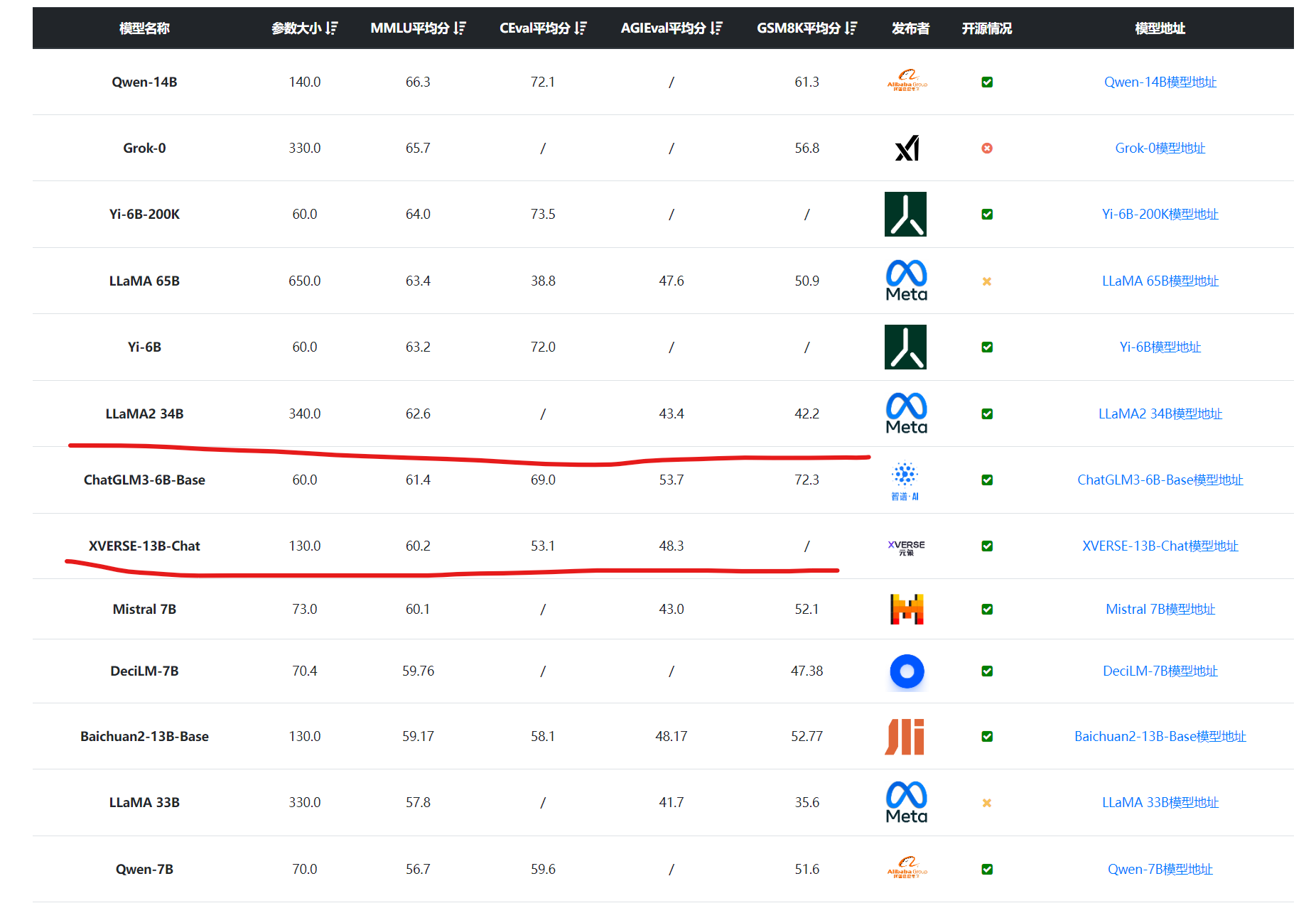
深圳的元象科技开源了一个最高上下文256K的大语言模型XVERSE-13B-256K,可以一次性处理25万字左右,是目前上下文长度最高的大模型,而且这个模型是以Apache2.0协议开源,完全免费商用授权。
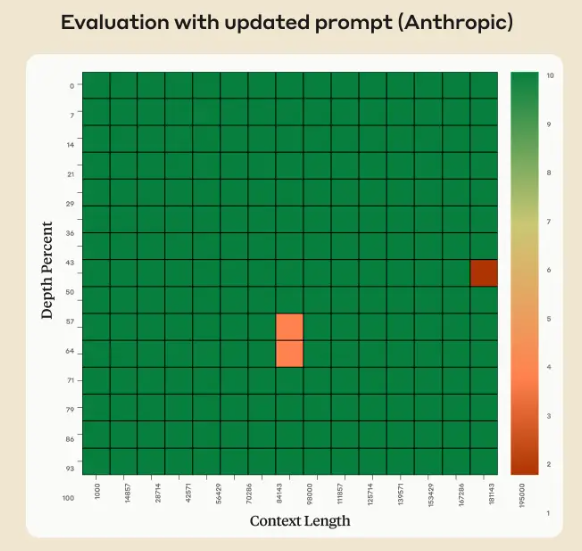
Claude 2.1版本的模型上下文长度最高拓展到200K,也是目前商用领域上下文长度支持最长的模型之一。但是,在模型发布不久之后,有人测试发现模型在超过20K之后效果下降明显。但是Anthropic官方发布了一个说明解释这不是Claude模型本身在超长上下文的真实原因,主要是模型拒绝回答一些与文章主体不符的内容,实际中只需要一句prompt即可提高性能,将模型在超长上下文的水平准确率从27%提高到98%。

GPT-4 Turbo是OpenAI最新发布的号称性能超过当前GPT-4的模型。在新版本的ChatGPT中已经可以使用。而接口也在开放。除了速度和质量外,GPT-4 Turbo最吸引人的是支持128K超长上下文输入。但是,实际测试中GPT-4 Turbo对于超过73K tokens文档的理解能力急速下降。

零一万物(01.AI)是由李开复在2023年3月份创办的一家大模型创业企业,并在2023年6月份正式开始运营。在2023年11月6日,零一万物开源了4个大语言模型,包括Yi-6B、Yi-6B-200K、Yi-34B、Yi-34B-200k。模型在MMLU的评分上登顶,最高支持200K超长上下文输入,获得了社区的广泛关注。

在大语言模型中,上下文长度是指模型可以考虑的输入数据的数量。更长的上下文在大语言模型的实际应用中有非常重要的价值。当前,让大语言模型支持更长的上下文有两种常用的方法,一种是训练支持更长上下文长度的模型,扩展模型的输入,另外一种是检索增强生成的方法(Retrieval Augmentation Generation,RAG)。但二者应该如何选择,这是一个很少能直接比较的问题。为此,英伟达(Nvidia)的研究人员做了一个详细的比较。
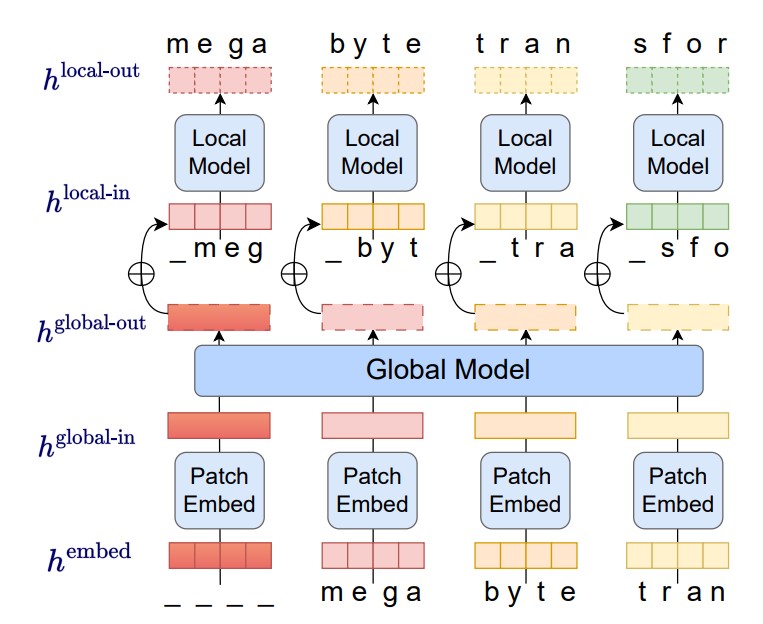
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!

大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。

目前开源领域已经有一些模型宣称支持了8K甚至是更长的上下文。那么这些模型在长上下文的支持上表现到底如何?最近LM-SYS发布了LongChat-7B和LangChat-13B模型,最高支持16K的上下文输入。为了评估这两个模型在长上下文的表现,他们对很多模型在长上下文的表现做了评测,让我们看看这些模型的表现到底怎么样。