智谱AI发布国产最强大模型GLM4,理解评测与数学能力仅次于Gemini Ultra和GPT-4,编程能力超过Gemini-pro,还有对标GPTs商店的GLMs
GLM4是智谱AI发布的第四代基座大语言模型,全称General Language Model,最早由清华大学KEG小组再2021年发布。这个基座模型也是著名的开源国产大模型ChatGLM系列的基座模型。本次发布的第四代GLM4的能力相比此前的基座模型提升了60%,已经与世界最强模型Gemini Ultra和GPT-4接近!

GLM-4基座模型介绍
这是在智谱AI开发者大会上推出的新一代基座大语言模型,GLM4相比较此前最大的特点是三个变化:性能全面提升、上下文长度更长、支持更强的多模态能力。GLM-4在DataLearnerAI的模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/GLM4
各项评测结果大幅提升:性能全面增强
GLM4公布了其在各项评测的结果,包括MMLU理解评测、GSM8K数学逻辑和代码水平上,都有大幅提升。

如上图所示,是GLM4与Google Gemini Ultra和GPT-4的对比结果。从图中的对比结果可以看到,阅读理解方面,GLM4与Google Geimin Ultra差距不大,比GPT-4低5分左右,这也是目前已知的基座大模型中排名最好的国产模型了,此前突破80分的是李开复零一万物的Yi-34B模型,这个得分也比ChatGLM3-6B-Base提高了20分!而数学推理方面,GSM8K的评测结果显示,GLM4得分87.6,也是超过了Google的Gemini Pro,仅次于GPT-4和Gemini Ultra。不过,Gemini Pro的评测虽然好,但是Bard体验一般,很多反馈不行。而编程能力方面,GLM4的得分也很不错,接近Gemini-ultra的分数。这个图中把GPT-4的结果列为67,但是微软测试结果是82,按照实际体验看,GPT-4为82是合理的。
下图是DataLearner综合评测按照MMLU排序的结果:
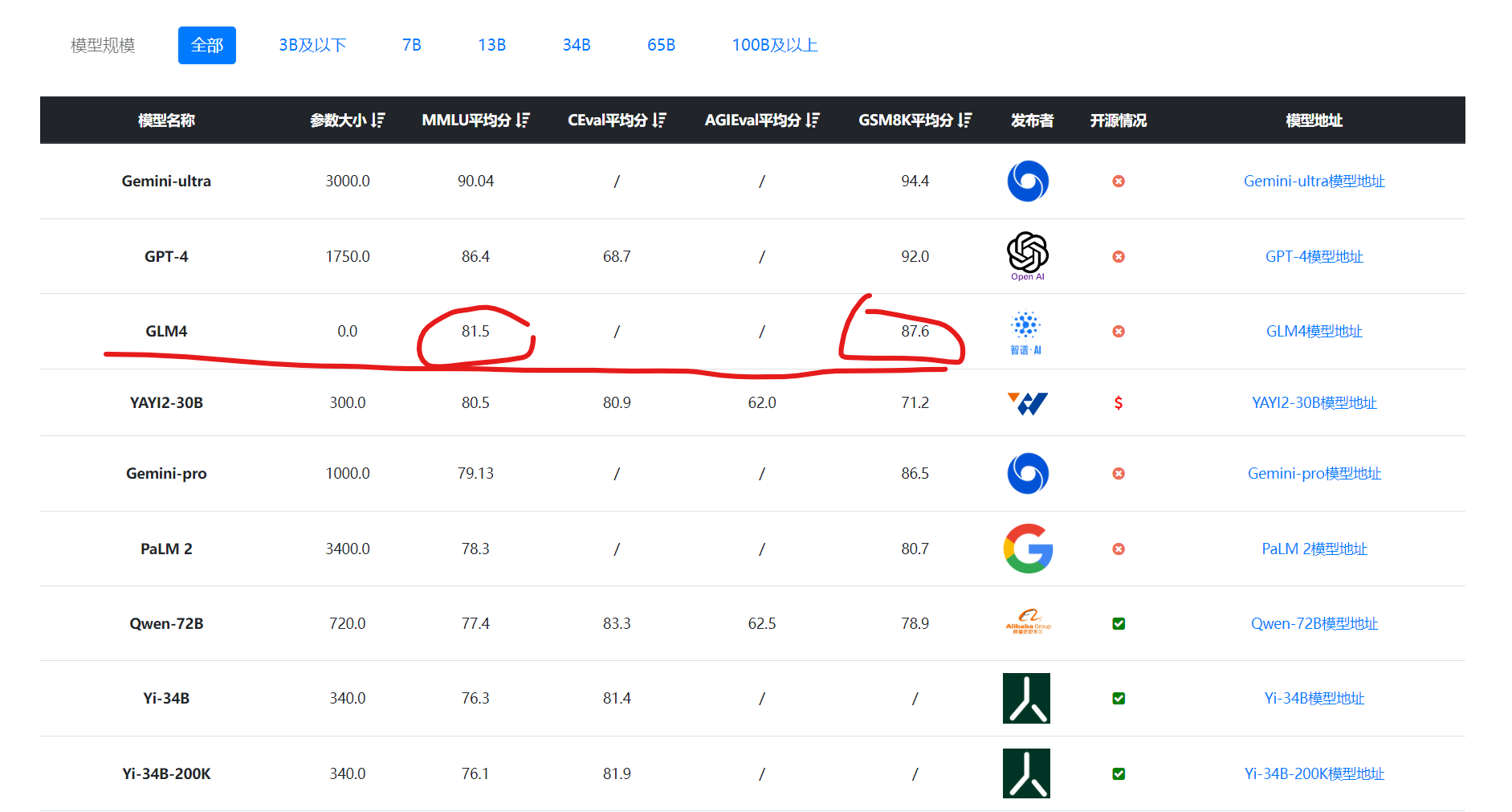
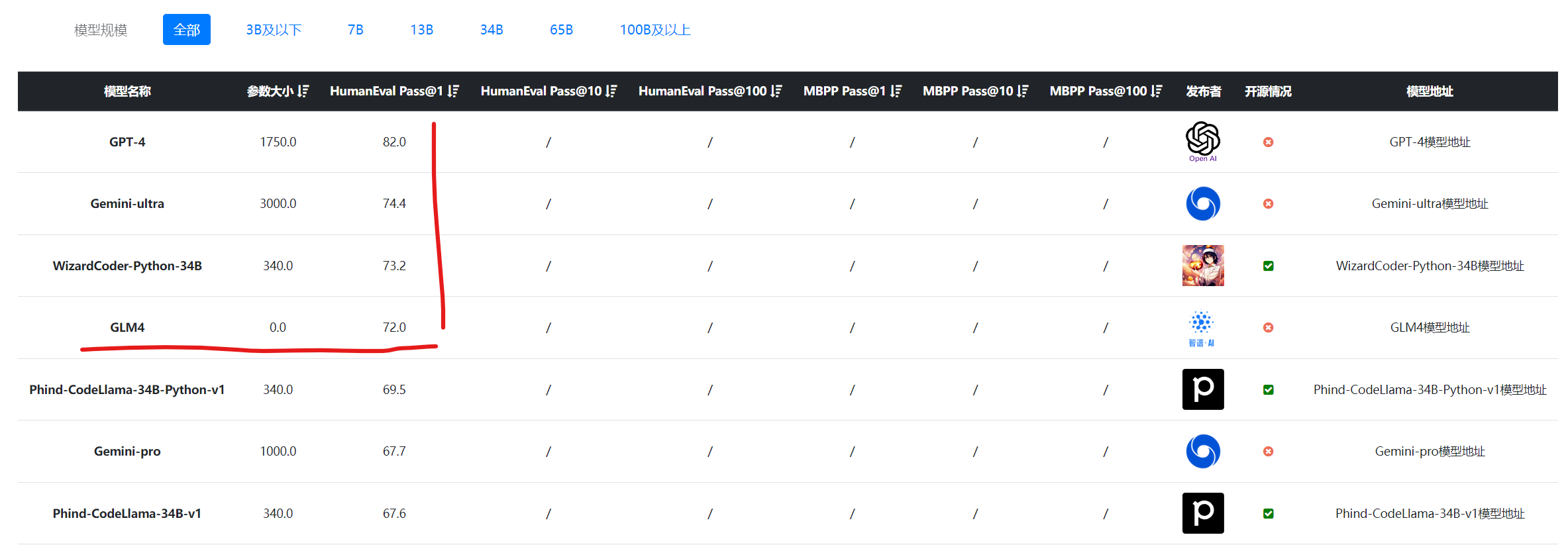
以及编程评测按照HumanEval排序的结果,可以看到,不论哪个对比,GLM4的表现都可以理解为与GPT-4和Gemini Ultra差不多,应该是比GPT-4略低。
GLM4最高支持128K超长上下文
在之前的模型中,智谱AI的模型最高支持32K上下文长度,而本次GLM4的发布,将上下文的长度提升到了128K,与GPT-4对齐。他们也根据此前的“needle in a haystack”(大海捞针)测试(详情参考此前GPT-4与Claude的测试:https://www.datalearner.com/blog/1051699526438975 和 https://www.datalearner.com/blog/1051701947131881 )。

大模型“大海捞针”测试就是给定一篇超长上下文,然后插入一句与全文无关的内容,用大模型针对这个无关内容提问,如果大模型能准确回答,则说明大模型超长上下文支持良好,这个测试虽然不严谨,但是某种程度上可以代表大模型对超长上下文的支持水平。具体测试过程可以参考前面DataLearner的内容。
从上图看,GLM4-128K的在超长上下文的水平表现上与GPT-4-Turbo和Claude-2.1几乎完全一致。表现非常不错~
GLM4的多模态支持
除了基础语言能力的提升,GLM4在多模态的支持上也更强。这里提到的就是CogView3,这是底层基于GLM4为语言模型的多模态大模型,在各项评测结果中非常不错,与DALL·E3的水平几乎一致。

下图是一些生成图片的样例:

画面还是非常精致的。
GLM-4 All Tools
此次,智谱AI还推出了对标GPT-4 All Tools的GLM-4 All Tools,一个集合了各种工具,可以自主规划任务分解任务并执行的一个类似AI Agent模式的大模型系统。这个系统相比较基座模型,可以通过调用代码解释器、网络浏览器工具等提升模型的水平。根据测试,这个模型系统比基座模型在各项评测结果中有更好的提升。
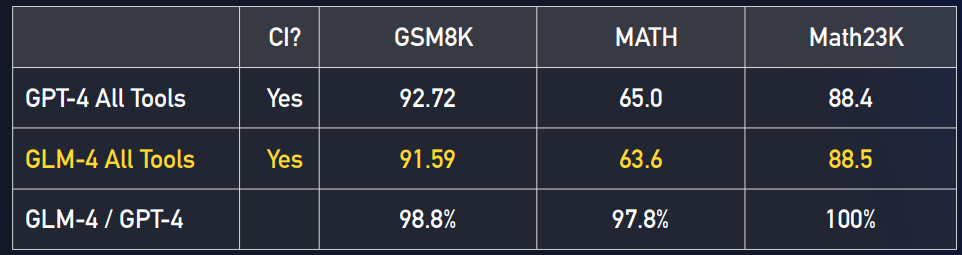
这里的GSM8K的分数已经达到了91.59分,而底座模型GLM4则是87.6分。
GLMs商店
此次智谱AI还推出了对标GPTs商店的GLMs商店,开发者可以自定义GLMs来推出基于GLM4的自定义大模型服务,也会有开发者分成计划,不过官网还未更新,暂不确定具体能力和水平。
总结
智谱AI是国内在大模型领域走的非常快的创业公司,他们开源的ChatGLM系列在国内也是获得了非常大的关注。去年共迭代了三个版本,而此次GLM4的发布让大家看到了一个更加接近OpenAI的国产大模型企业和大模型产品,智谱AI的发展值得关注。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
