
《Effective Java 第三版》笔记之一 创建静态工厂方法而不是使用构造器
本文是Effective Java第三版笔记的第一个之创建静态工厂方法而不是使用构造器
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
本文是Effective Java第三版笔记的第一个之创建静态工厂方法而不是使用构造器
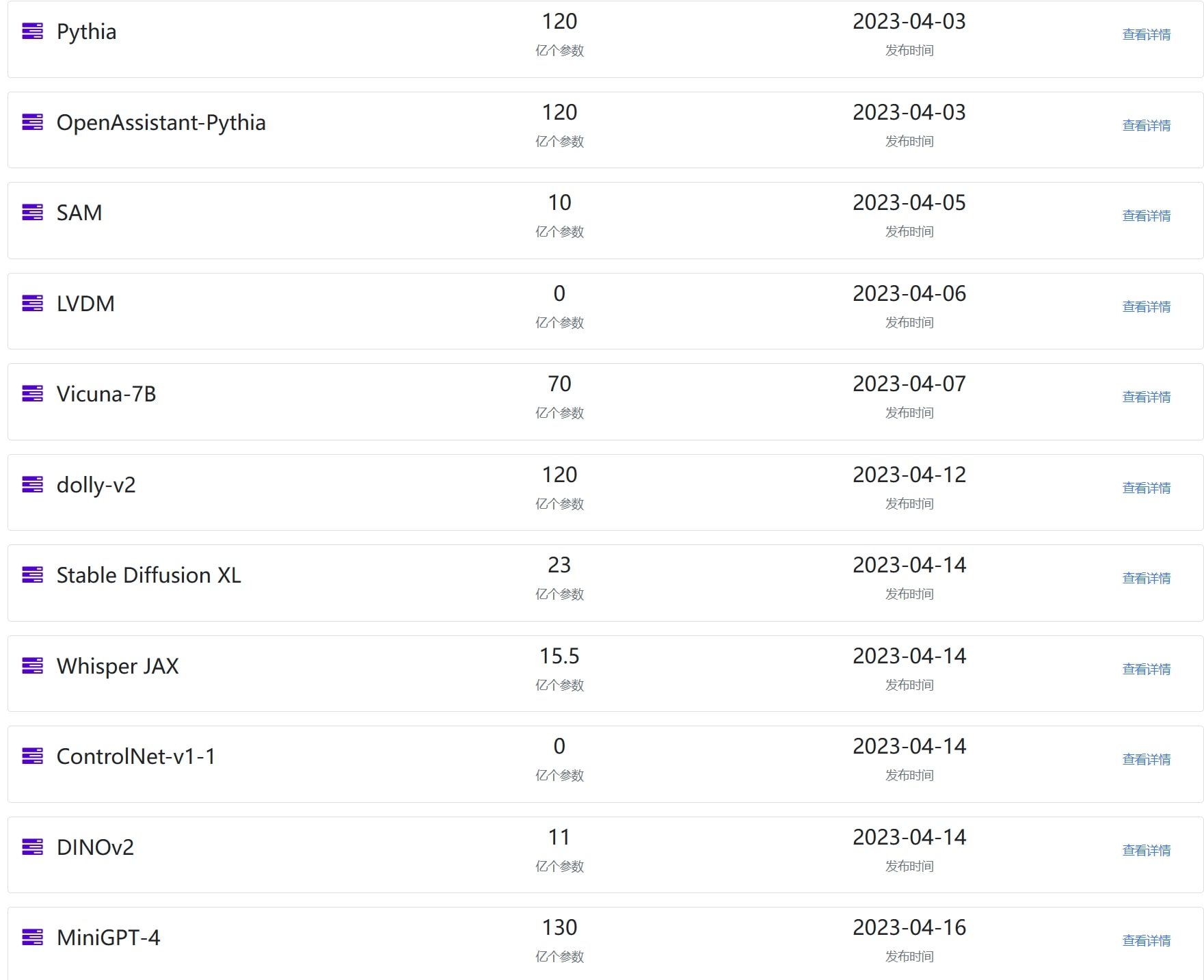
2022年11月底,OpenAI发布ChatGPT,2023年3月14日,GPT-4发布。这两个模型让全球感受到了AI的力量。而随着MetaAI开源著名的LLaMA,以及斯坦福大学提出Stanford Alpaca之后,业界开始有更多的AI模型发布。本文将对4月份发布的这些重要的模型做一个总结,并就其中部分重要的模型进行进一步介绍。
随着互联网的高速发展,人类进入了一个信息爆炸的时代,每个人的生活都充满了结构化和非结构化的数据。另外,随着以博客、社交网络、基于位置的服务LBS为代表的新型信息发布方式的不断涌现,以及云计算、物联网技术的兴起,数据正以前所未有的速度在不断地增长和积累,数据已经渗透到当今每一个行业和业务职能领域成为重要的产生因素,以数据为驱动的大数据时代已经不可避免地到来。本文主要围绕大数据特征、处理系统、以及大数据分析来阐述大数据环境下的数据分析在思想、流程、方法等方面的转变,以及围绕此主题而出现的相关关键技术与方法。
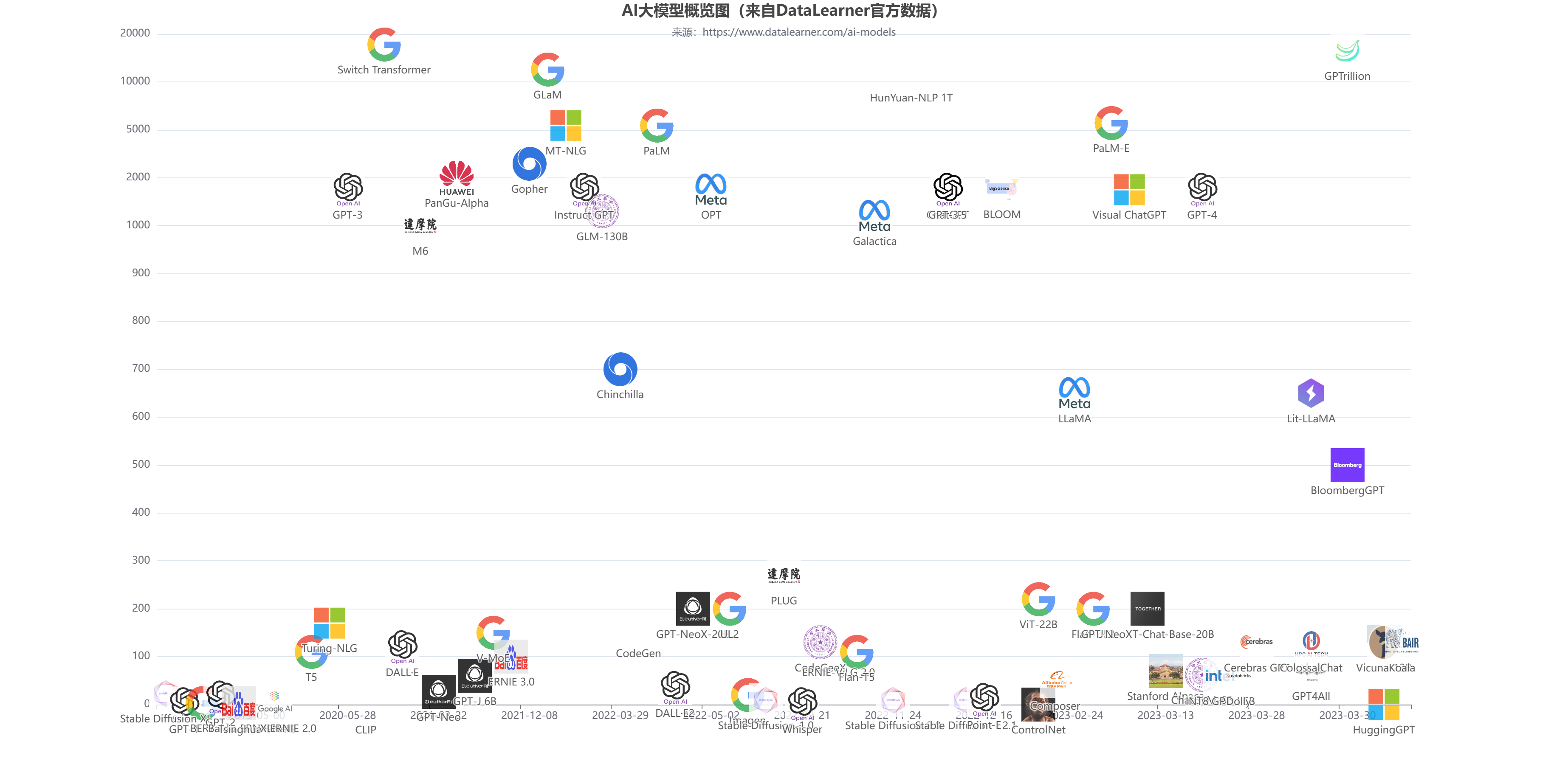
本文主要描述了阿里眼中国内各家企业的大模型水平以及一些硬件算力的判断,同时结合部分其它信息整理。里面涉及到当前国内各大企业模型水平判断(如百度文心一言、华为盘古等)以及算力储备信息。
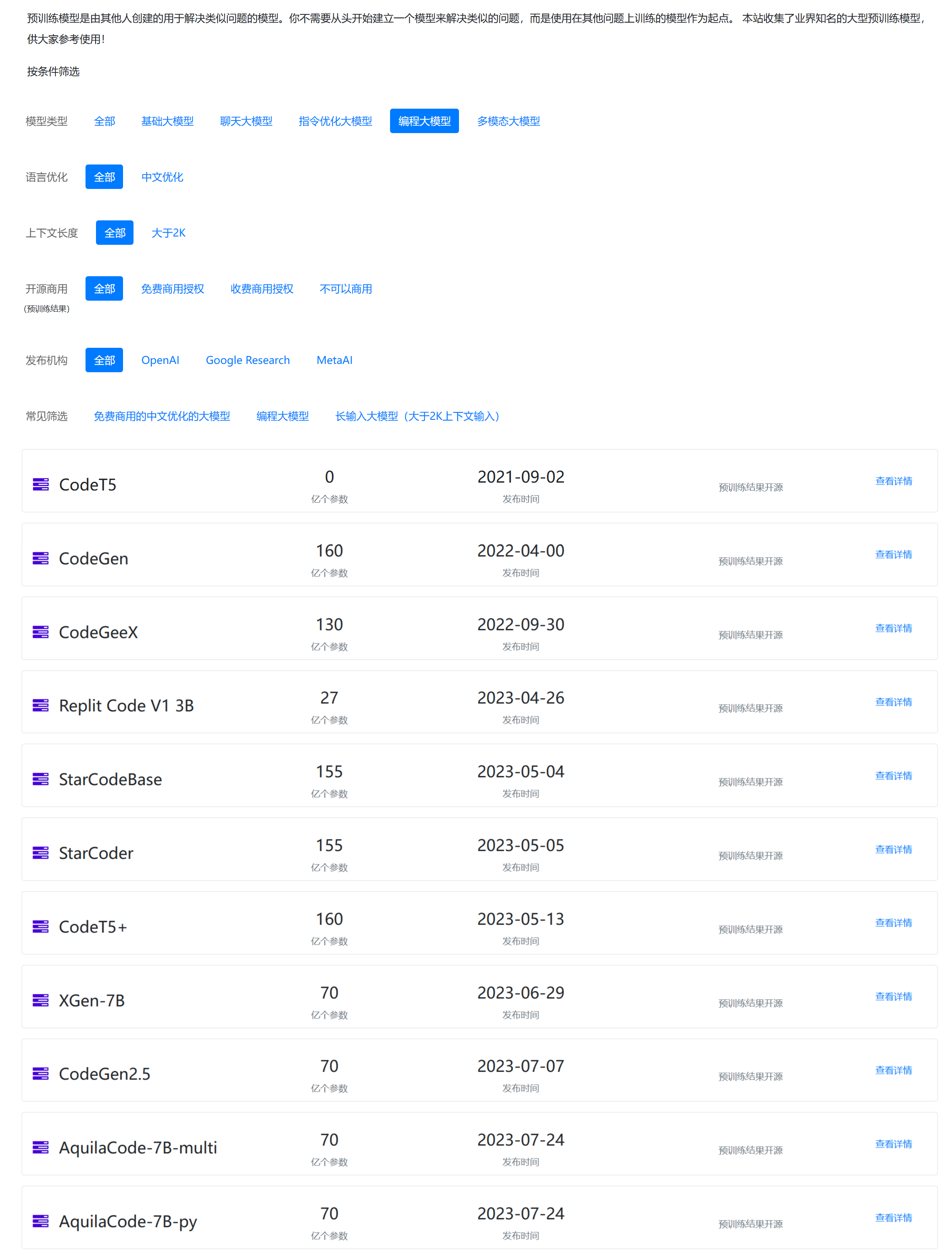
编程大模型是大语言模型的一个非常重要的应用。刚刚,清华大学系创业企业智谱AI开源了最新的一个编程大模型,CodeGeeX2-6B。这是基于ChatGLM2-6B微调的针对编程领域的大模型。
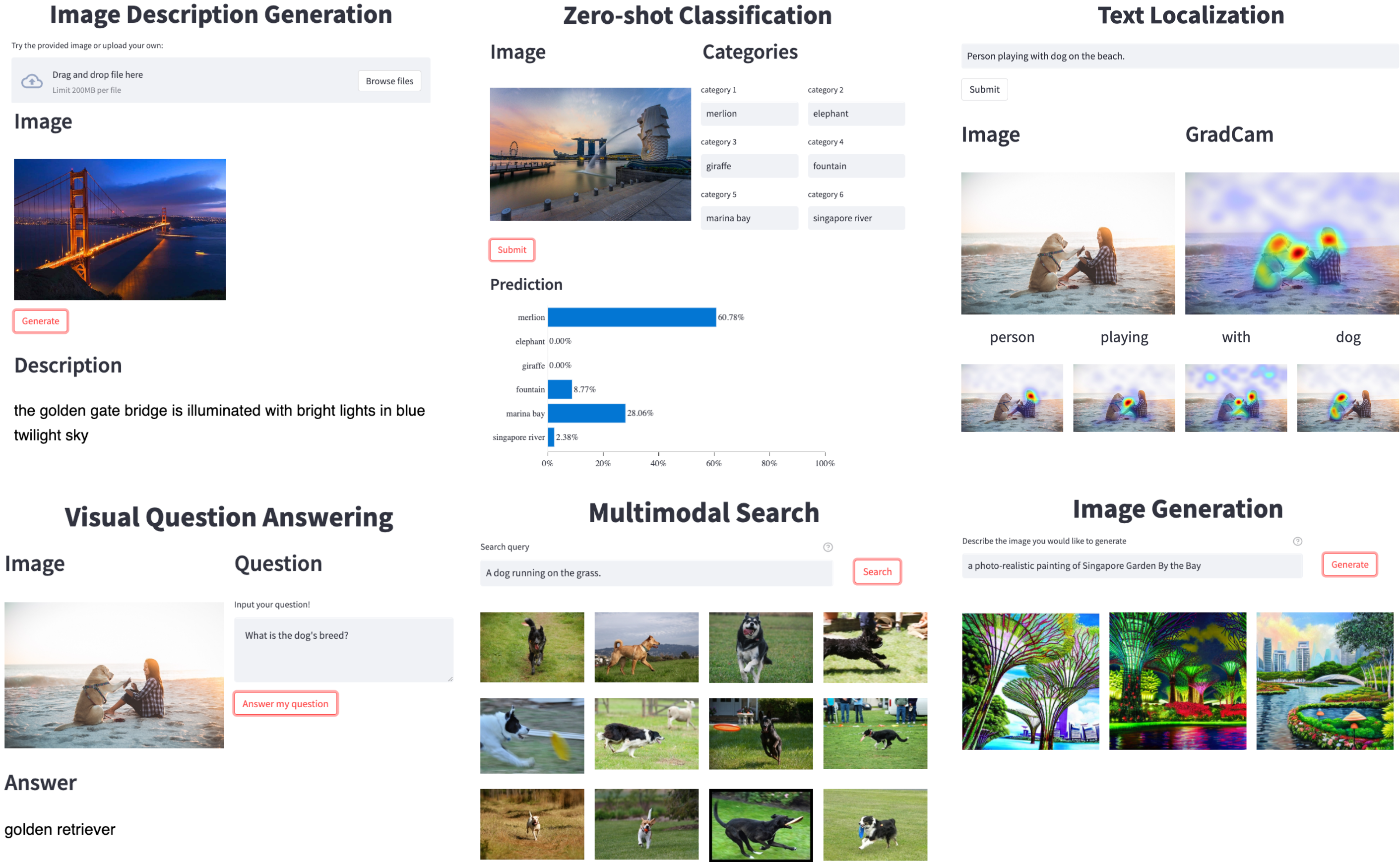
Salesforce的研究人员开发了LAVIS(LAnguage-VISION的缩写),这是一个开源的库,用于在丰富的常见任务和数据集系列上训练和评估最先进的语言-视觉模型,并用于在定制的语言-视觉数据上进行现成的推理。

Stable Diffusion是最近很火的Text-to-Image预训练模型(详细信息:https://www.datalearner.com/ai-resources/pretrained-models/stable-diffusion )。而现在,相关的视频教程已经出现。fast.ai的团队宣布了一门新的深度学习课程《From Deep Learning Foundations to Stable Diffusion》上线!
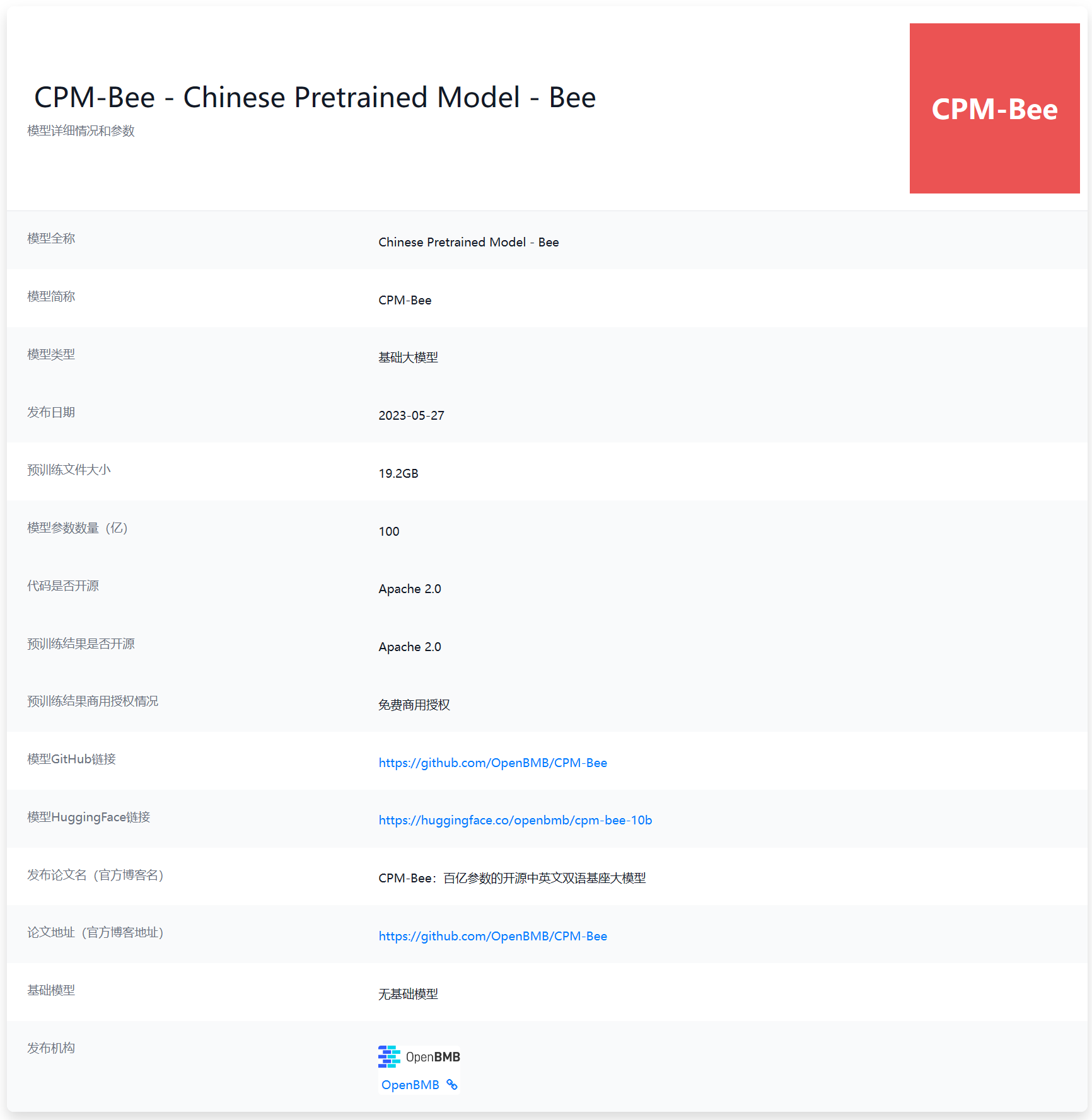
最近几个月,国产大语言模型进步十分迅速。不过,大多数企业发布的大模型均为商业产品,少数开源的LLM则有较高的商业授权费用或者商用限制。对于希望使用LLM能力的中小企业以及个人来说都不是很合适。本次给大家介绍的是目前国产开源领域里面一个十分优秀且具有潜力的大语言模型CPM-Bee 10B。该模型来自清华大学NLP实验室,参数规模100亿,最重要的是对个人和企业用户均提供免费商用授权,十分友好!

数据科学项目为我们提供了很好的机会提升我们的技能和知识。这篇博客提供了17个数据科学的项目,都是可以免费获取的项目,大家可以通过这些诶项目学习数据科学相关知识。

今天,时隔一年后,OpenAI发布了第二代的DALL·E模型。相比较第一代的模型,DALL·E 2,以4倍的分辨率生成更真实和准确的图像。
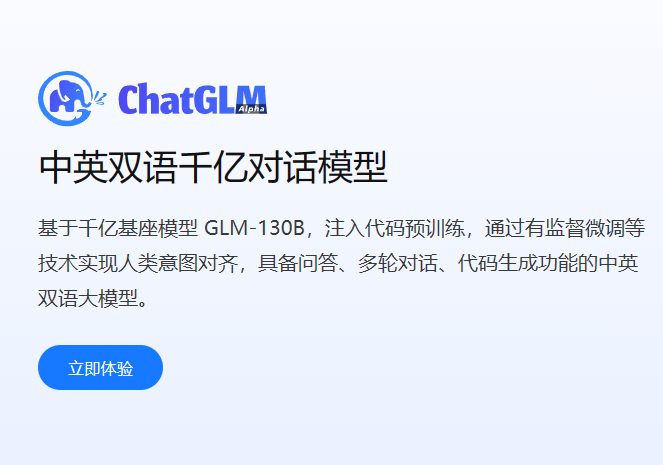
ChatGLM系列是智谱AI发布的一系列大语言模型,因为其优秀的性能和良好的开源协议,在国产大模型和全球大模型领域都有很高的知名度。今天,智谱AI开源其第三代基座大语言模型ChatGLM3-6B,官方说明该模型的性能较前一代大幅提升,是10B以下最强基础大模型!

昨天,HuggingFace的大语言模型排行榜上突然出现了一个评分超过LLaMA-65B的大语言模型:Falcon-40B,引起了广泛的关注。本文将简要的介绍一下这个模型。截止2023年5月27日,Falcon-40B模型(400亿参数)在推理、理解等4项Open LLM Leaderloard任务上评价得分第一,超过了之前最强大的LLaMA-65B模型。
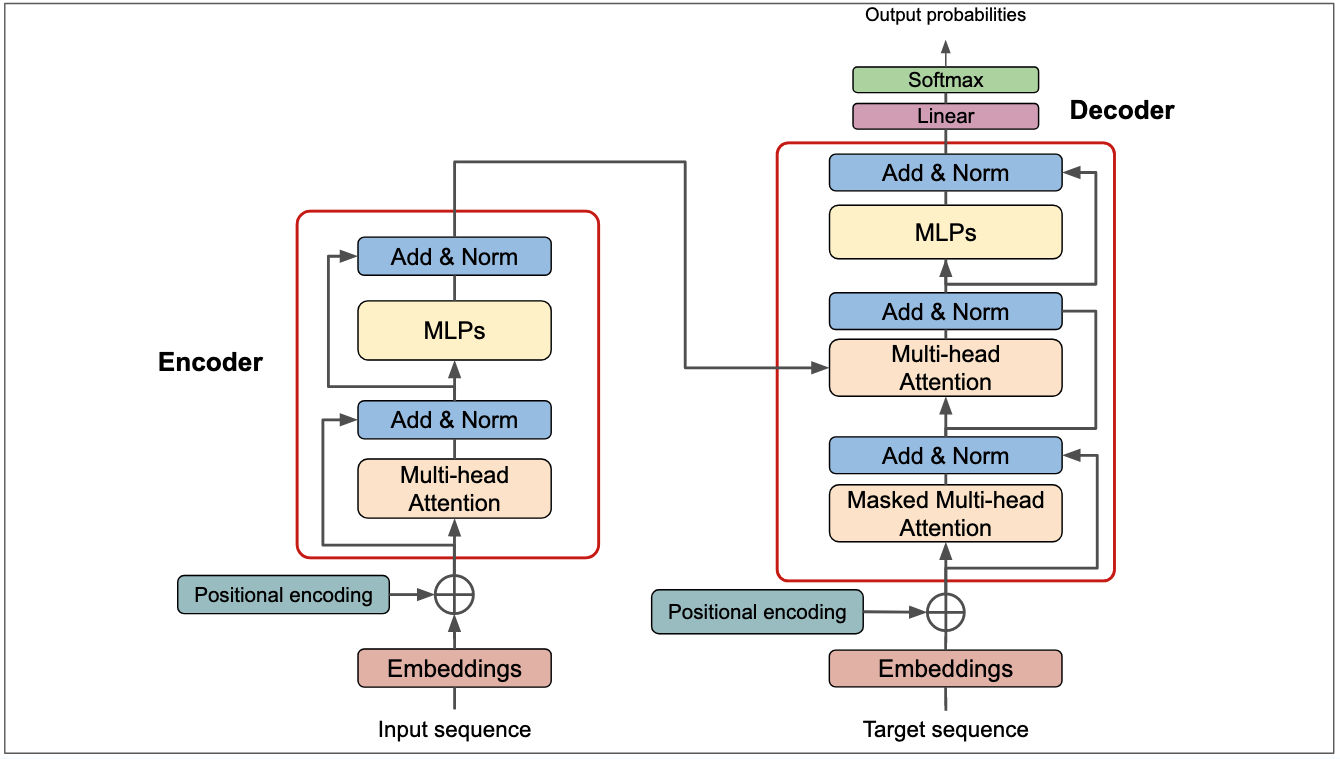
CMU的工程人工智能硕士学位的研究生Jean de Nyandwi近期发表了一篇博客,详细介绍了当前大语言模型主流架构Transformer的历史发展和当前现状。这篇博客非常长,超过了1万字,20多个图,涵盖了Transformer之前的架构和发展。此外,这篇长篇介绍里面的公式内容并不多,所以对于害怕数学的童鞋来说也是十分不错。本文是其翻译版本,欢迎大家仔细学习。

随着ChatGPT的火爆以及MetaAI开源了LLaMA,各家公司好像一夜之间都有了各种ChatGPT模型的研发实力。而针对不同任务和应用构建的LLM更是层出不穷。那么,如何选择合适的模型完成特定的任务,甚至是使用多个模型完成一个复杂的任务似乎仍然很困难。为此,浙江大学与微软亚洲研究院联合发布了一个大模型写作系统HuggingGPT,可以根据输入的任务帮我们选择合适的大模型解决!
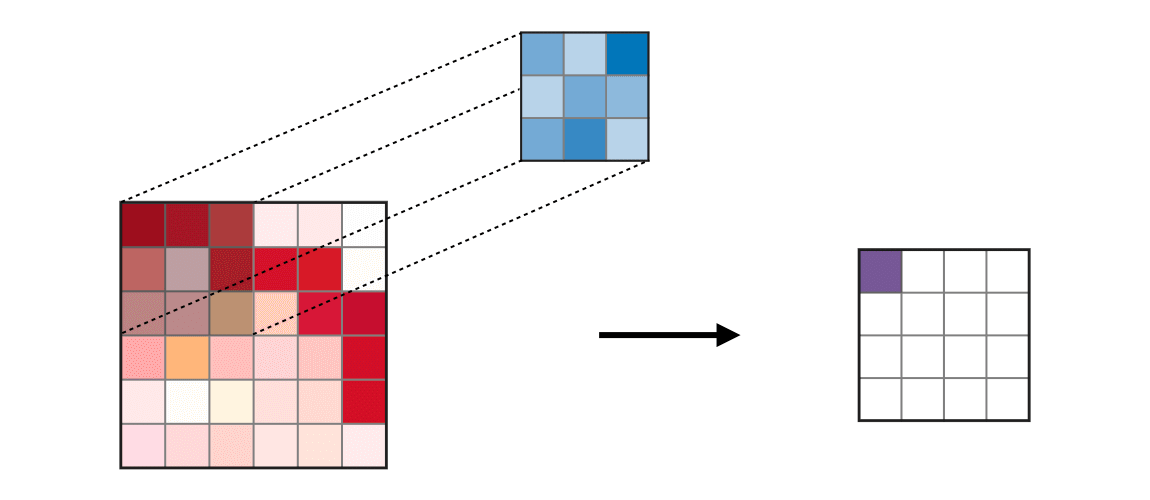
CS 230 ― Deep Learning是斯坦福大学视觉实验室(Stanford Vision Lab)的Shervine Amidi老师开设的深度学习课程,他在课程网站上挂了一个关于深度学习示意图的网站,这里面包含了各种深度学习相关概念的示意图和动图,十分简单明了。
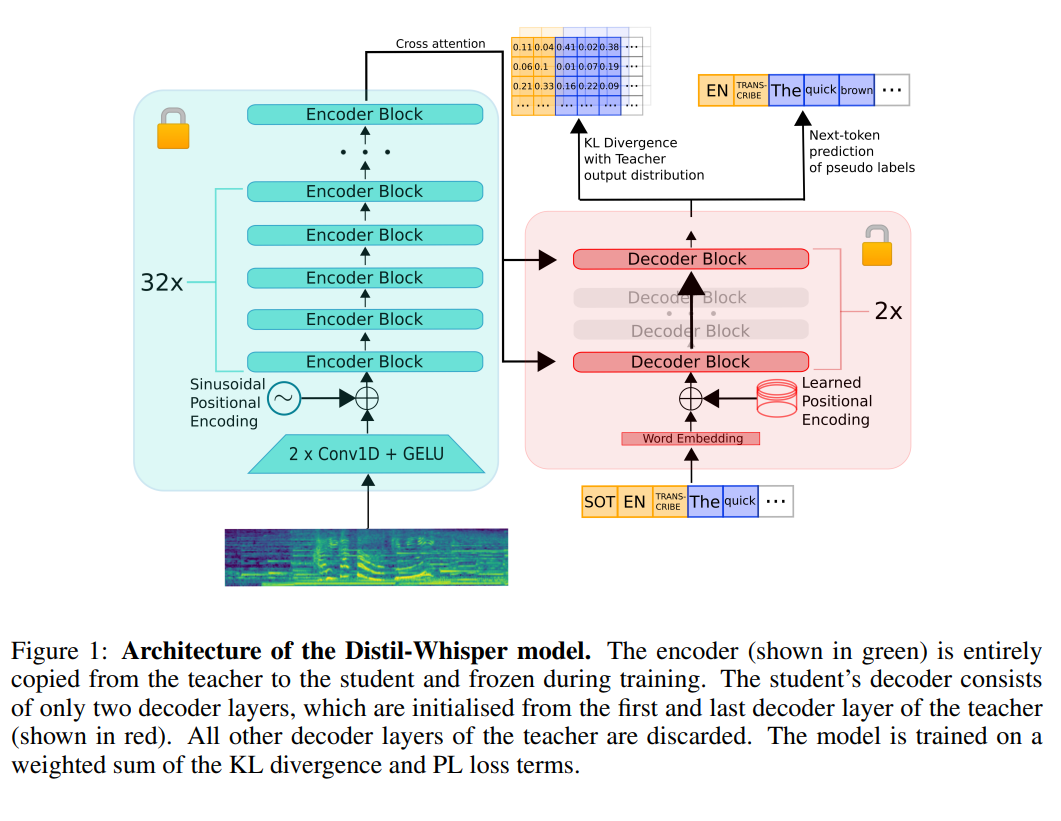
语音识别在实际应用中有非常多的应用。早先,OpenAI发布的Whisper模型是目前语音识别模型中最受关注的一类,也很可能是目前ChatGPT客户端语音识别背后的模型。HuggingFace基于Whisper训练并开源了一个全新的Distil-Whisper,它比Whisper-v2速度快6倍,参数小49%,而实际效果几乎没有区别。
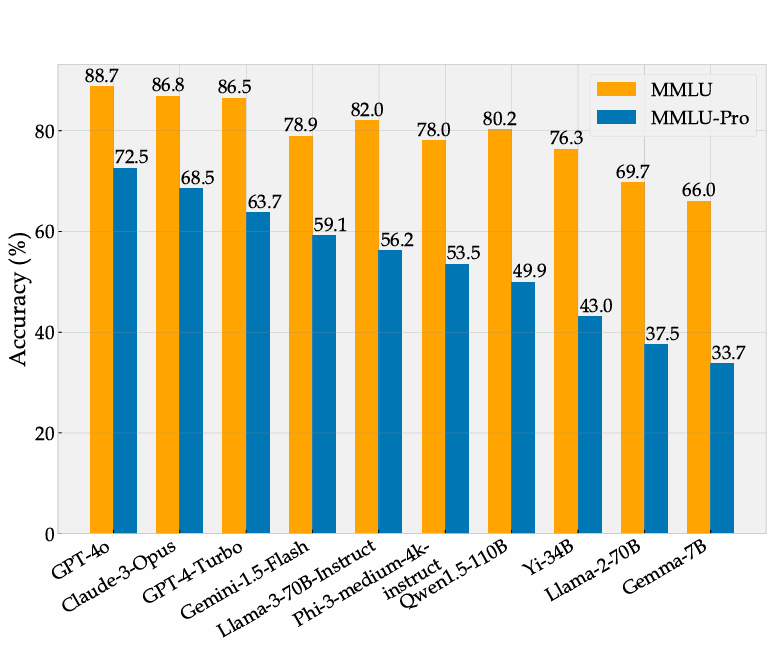
大模型已经对很多行业产生了巨大的影响,如何准确评测大模型的能力和效果,已经成为业界亟待解决的关键问题。生成式AI模型,如大型语言模型(LLMs),能够生成高质量的文本、代码、图像等内容,但其评测却相对很困难。而此前很多较早的评测也很难区分当前最优模型的能力。 以MMLU评测为例,2023年3月份,GPT-4在MMLU获得了86.4分之后,将近2年后的2024年年底,业界最好的大模型在MMLU上得分也就90.5,提升十分有限。 为此,滑铁卢大学、多伦多大学和卡耐基梅隆大学的研究人员一起提出了MMLU P
