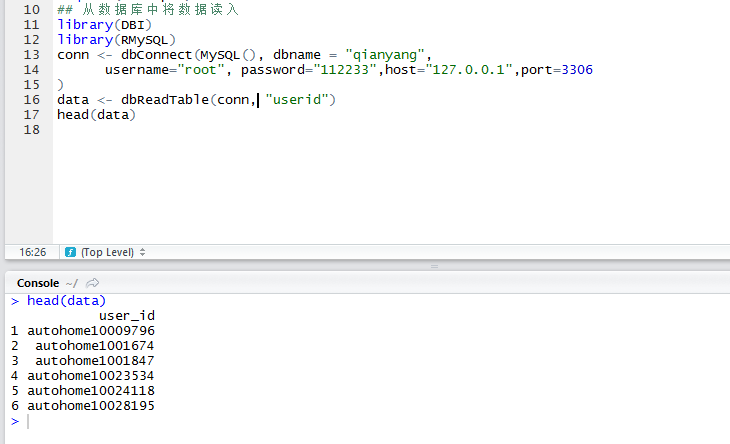
国产开源中文大语言模型再添重磅玩家:清华大学NLP实验室发布开源可商用大语言模型CPM-Bee
5月27日,OpenBMB发布了一个最高有100亿参数规模的开源大语言模型CPM-BEE,OpenBMB是清华大学NLP实验室联合智源研究院成立的一个开源组织。该模型针对高质量中文数据集做了训练优化,支持中英文。根据官方的测试结果,其英文测试水平约等于LLaMA-13B,中文评测结果优秀。
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.
5月27日,OpenBMB发布了一个最高有100亿参数规模的开源大语言模型CPM-BEE,OpenBMB是清华大学NLP实验室联合智源研究院成立的一个开源组织。该模型针对高质量中文数据集做了训练优化,支持中英文。根据官方的测试结果,其英文测试水平约等于LLaMA-13B,中文评测结果优秀。
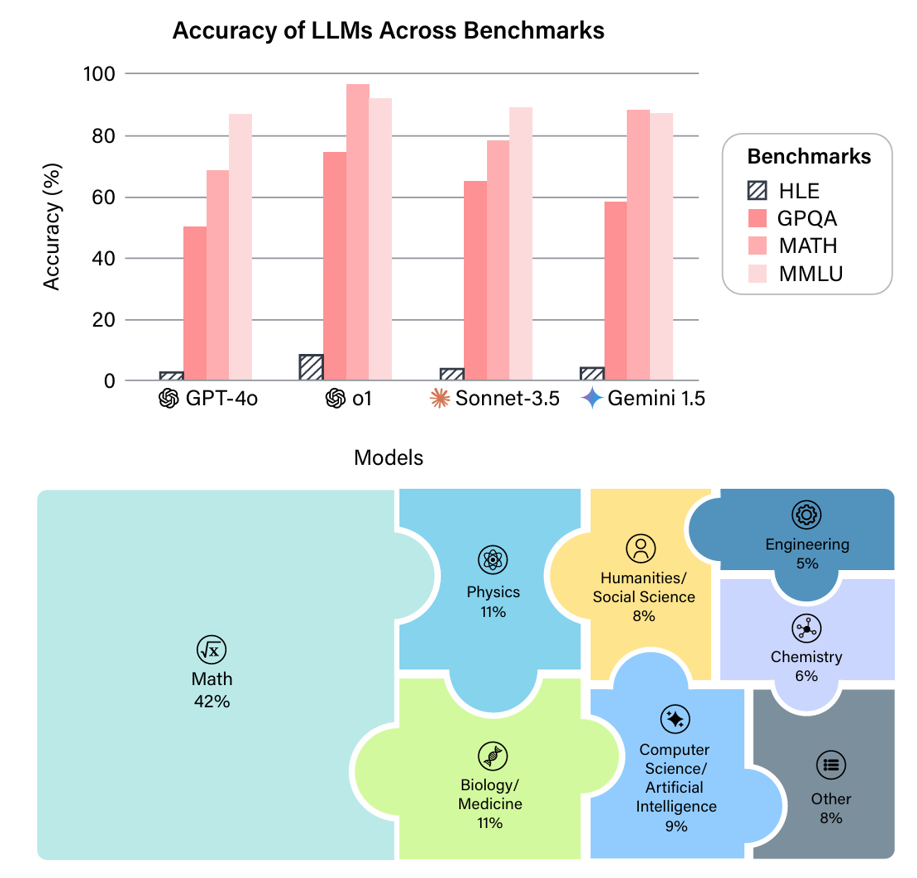
近年来,大语言模型(LLM)的能力飞速提升,但评测基准的发展却显得滞后。以广泛使用的MMLU(大规模多任务语言理解)为例,GPT-4、Claude等前沿模型已能在其90%以上的问题上取得高分。这种“评测饱和”现象导致研究者难以精准衡量模型在尖端知识领域的真实能力。为此,Safety for AI和Scale AI的研究人员推出了Humanity’s Last Exam大模型评测基准。这是一个全新的评测基准,旨在成为大模型“闭卷学术评测的终极考验”。

在使用Dask进行两个dataframe的concatenate操作的时候抛出ValueError,本文记录这个错误以及解决方案。
深度学习本质上是表示学习,它通过多层非线性神经网络模型从底层特征中学习出对具体任务而言更有效的高级抽象特征。针对一个具体的任务,我们往往会遇到这种情况:需要用一个模型学习出特征表示,然后将学习出的特征表示作为另一个模型的输入。这就要求我们会获取模型中间层的输出,下面以具体代码形式介绍两种具体方法。
指标(metrics)和损失函数(loss function)在深度学习和机器学习里面非常常见,很多时候他们的公式都似乎是一样的,在编写程序的时候,二者的区别好像也不是很大。那为什么还会有这两种不同的概念出现呢?本文将简单介绍一下二者的区别和应用。

计算机视觉与自然语言处理是近几年人工智能领域进步最快以及应用最为成熟的两个方向。计算机视觉里面任务涉及面广,有很多细分领域,本文将对计算机视觉领域中比较常见的六种任务进行总结并同时展示以下相关任务的一些成绩。
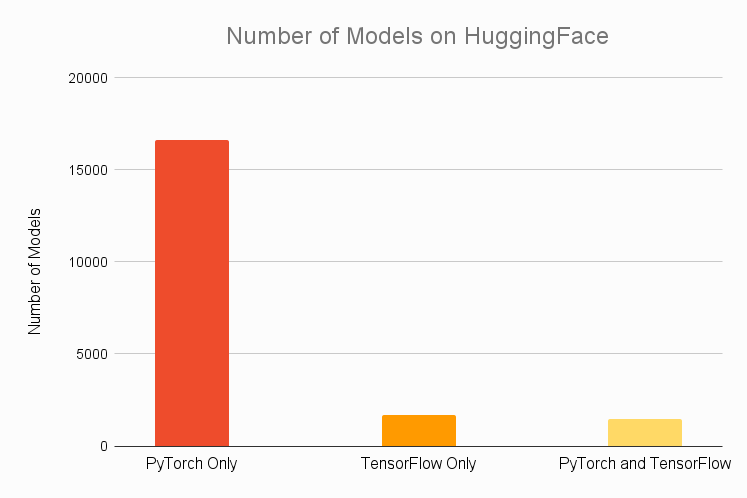
Tensorflow和PyTorch是深度学习最流行的两个框架,二者都有坚定的支持者。一般认为由于Google的支持,TensorFlow的社区支持比较好,在工业应用广泛。但是尽管有keras加持,但易用性方面依然被认为不如PyTorch。而后者最早由Facebook人工智能团队开发。由于其易用性,被认为在科学研究中有广泛使用。那么,最近几年二者发展如何,是否实际还如之前的观点一样,这里AssemblyAI的一个作者做了一些对比。

ChatGPT的Code Interpreter插件让ChatGPT突破了大语言模型本身只能做文本处理的限制,使其可以通过生成并执行Python代码来实现强大的数据分析、图片生成、视频数据处理等操作,大大拓展了ChatGPT的实用范围和价值。在此前的文章中,我们已经分析了Code Interpreter插件的官方实现。而今天,LangChain的官方博客也推出了一种类似的开源方案,让开源模型也可以实现ChatGPT的Code Interperter插件。我们简要描述一下这个方案。
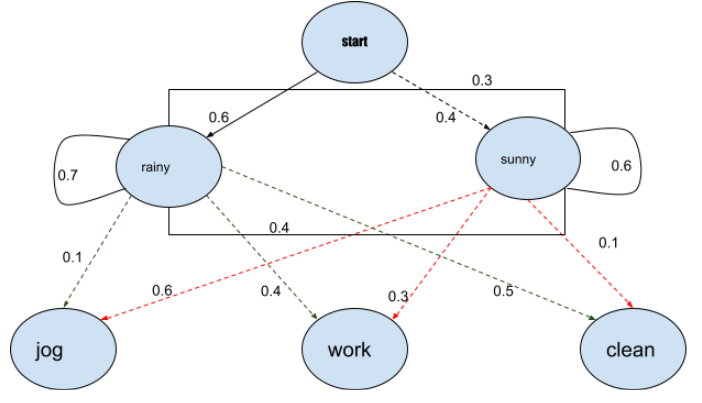
隐马尔可夫模型(HMM)是一种统计模型,也用于机器学习。它可以用来描述取决于内部因素的可观察事件的演变,而这些因素是无法直接观察到的。这是一类概率图形模型,允许我们从一组观察到的变量中预测一串未知的变量。在这篇文章中,我们将详细讨论隐马尔可夫模型。我们将了解它可以使用的背景,我们也将讨论它的不同应用。我们还将讨论HMM在PoS标签中的使用和python的实现。文章中所涉及的主要内容如下。
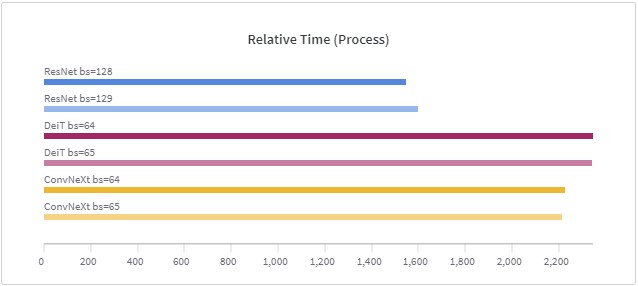
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。
Microsoft Visual C++ 14.0 is required

在Java中,自增是一种非常常见的操作,在自增中,有两种写法,一种是前缀自增(++i),一种是后缀自增(i++)。这里主要简单介绍两种自增的差别。