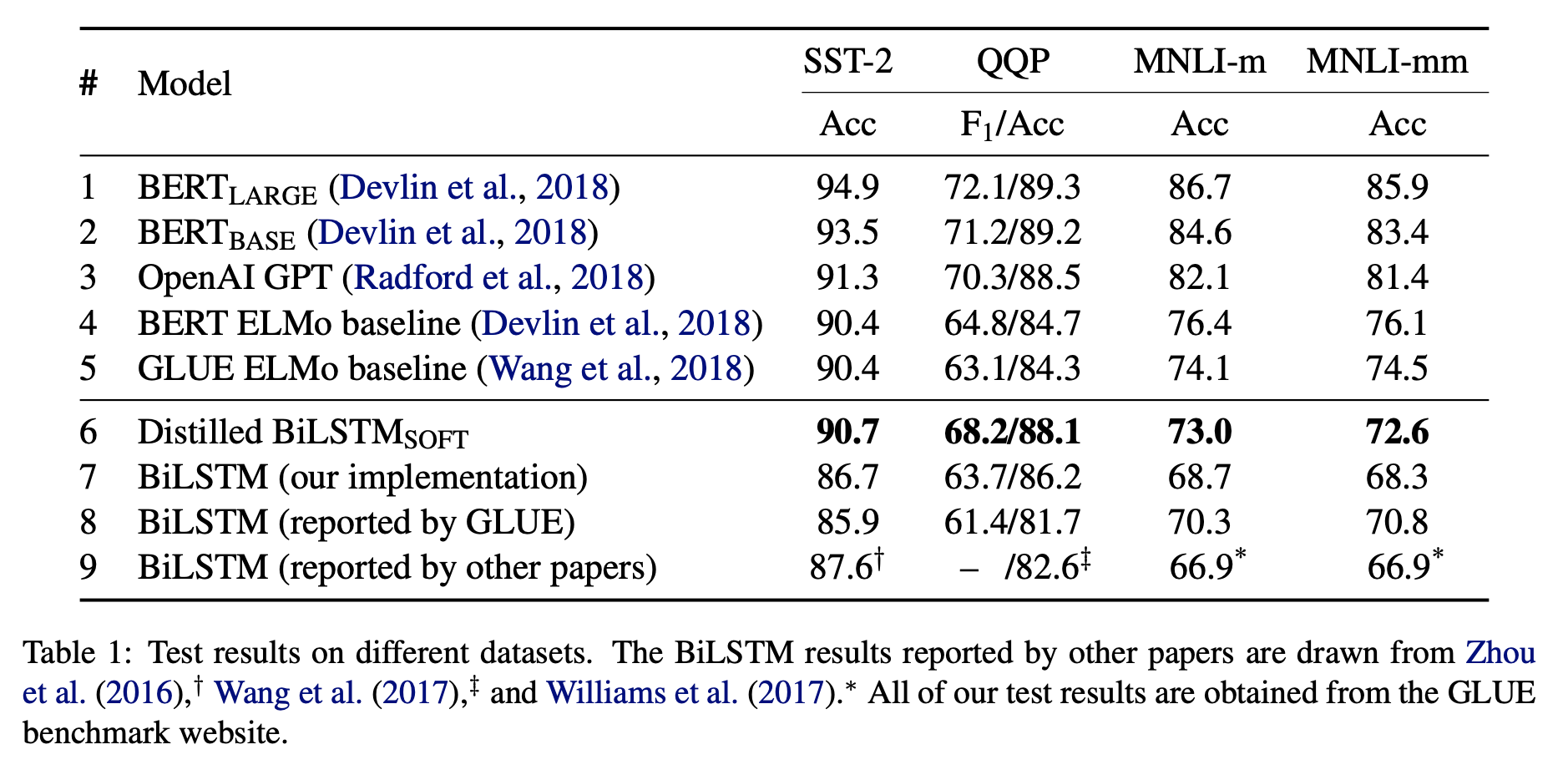
比Office Copilot更快一步~基于AI大语言模型生成PPT、Word和网页的应用的新产品测试~Gamma.APP,PPT打工人必备
大语言模型(Large Language Model,LLM)已经在很多领域都产生了巨大的影响。但是其中最为大家所期待的功能之一就是基于idea生成PPT、Word文档等。此前微软Office Copilot已经吸引了很多人的关注,但目前依然没有开放。而今天DataLearnerAI发现了一个类似的产品,来自洛杉矶初创企业Gamma的产品目前已经支持基于文本生成PPT、Word和网页应用了,本文带大家简单体验一下这个产品。