阿里巴巴开源国内最大参数规模大语言模型——高达720亿参数规模的Qwen-72B发布!还有一个可以在手机上运行的18亿参数的Qwen-1.8B
Qwen系列是阿里巴巴开源的一系列大语言模型。在此前的开源中,阿里巴巴共开源了3个系列的大模型,分别是70亿参数规模和140亿参数规模的Qwen-7B和Qwen-14B,还有一个是多模态大模型Qwen-VL。而此次阿里巴巴开源了720亿参数规模的Qwen-72B,是目前国内最大参数规模的开源大语言模型,应该也是全球范围内首次有和Llama2-70B同等规模的大语言模型开源。

目前,阿里开源了4个不同参数规模的Qwen大模型:
Qwen-72B模型简介
Qwen-72B模型是在3万亿tokens数据上训练的结果。该数据集包含了中、英文等多个语言的语料,同时包含了代码、数学等数据。Qwen-72B训练数据的词表为15万的。最高支持32K上下文长度。
Qwen-72B模型训练的具体参数如下:
Qwen-72B参数规模720亿,半精度(FP16)模型的载入需要144GB以上的显存!而Int4量化之后需要最少48GB的显存才可以推理。
Qwen-1.8B模型简介
此次开源的模型除了Qwen-72B的超大规模参数模型外,还有一个18亿参数规模的模型Qwen-1.8B。这个模型最高支持8K上下文输入,经过了充分训练(2.2万亿tokens数据集),官方宣传效果远超过近似规模模型。Qwen-1.8B模型在MMLU的评测结果如下:
虽然当前小模型不多,但是Qwen-1.8B效果还不错。而且这个模型最低int8/int4版本仅需2GB显存就可以推理。生成2048长度的序列只需要3GB显存,微调需要6GB显存!
Qwen-72B模型的多语言支持
注意,虽然Qwen-72B的模型虽然主要支持中英文,但是在多语言场景下支持也非常有前景。根据官方的信息:
在分词器方面,相比目前主流开源模型以中英词表为主,Qwen-72B使用了超过15万token大小的词表。 该词表在GPT-4使用的BPE词表cl100k_base基础上,对中文、多语言进行了优化,在对中、英、代码数据的高效编解码的基础上,对部分多语言更加友好。
下图是Qwen-72B模型在各种语言上的压缩比例:
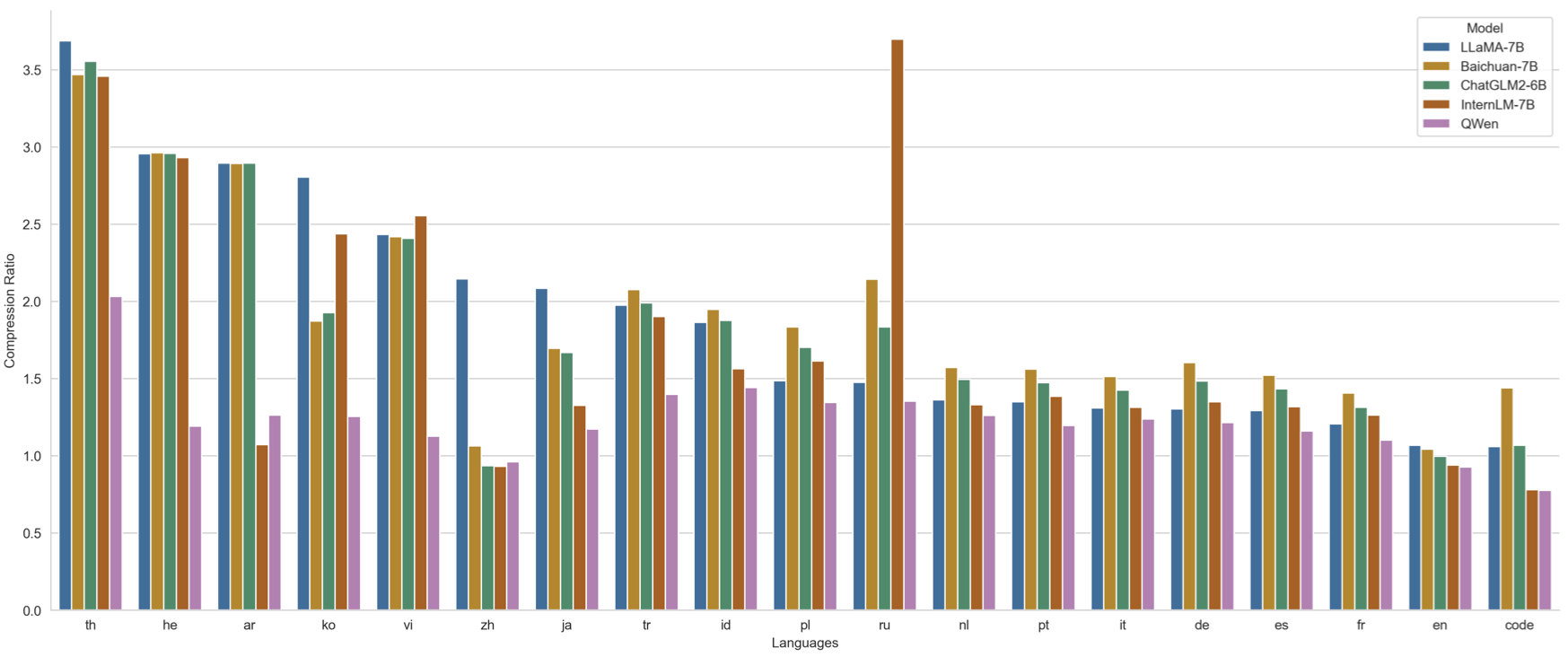
这意味着Qwen-72B开源很容易拓展到其他语言的支持!
Qwen-72B模型的评估效果
Qwen-72B模型的评测结果非常好。在GSM8K(数学逻辑)和MMLU(意图理解与通用知识)的评测都是目前开源模型最强,超过了李开复的零一万物的Yi-34B模型,仅次于GPT-4和Google的PaLM2模型。
下图是DataLearnerAI大模型综合排行截图:
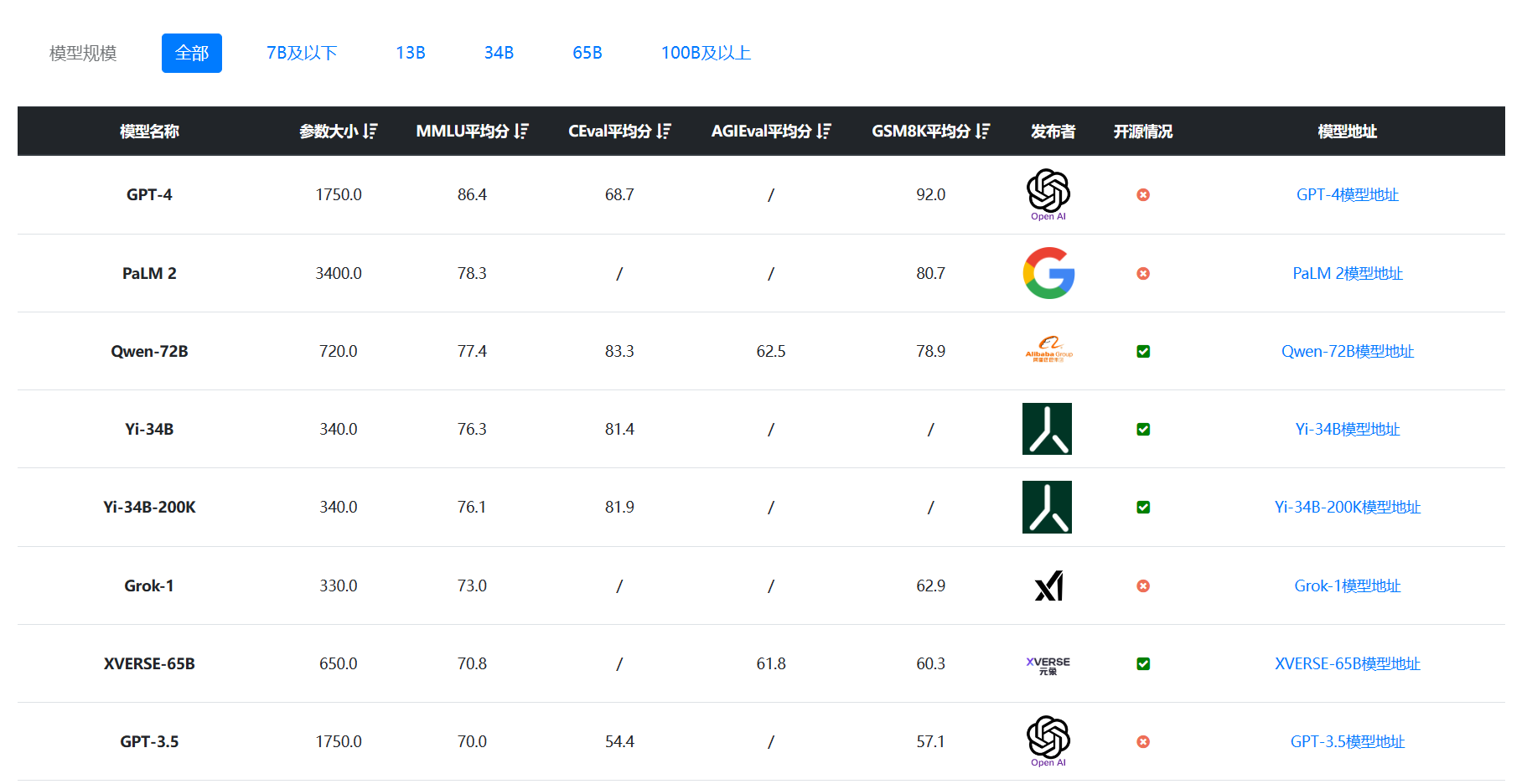
这些得分也是目前国内开源模型中最强的。
此外值得一提的是,Qwen-1.8B模型的MMLU得分和LLaMA2 7B差不多,证明这个模型虽然不大,但是能力还是很不错的~
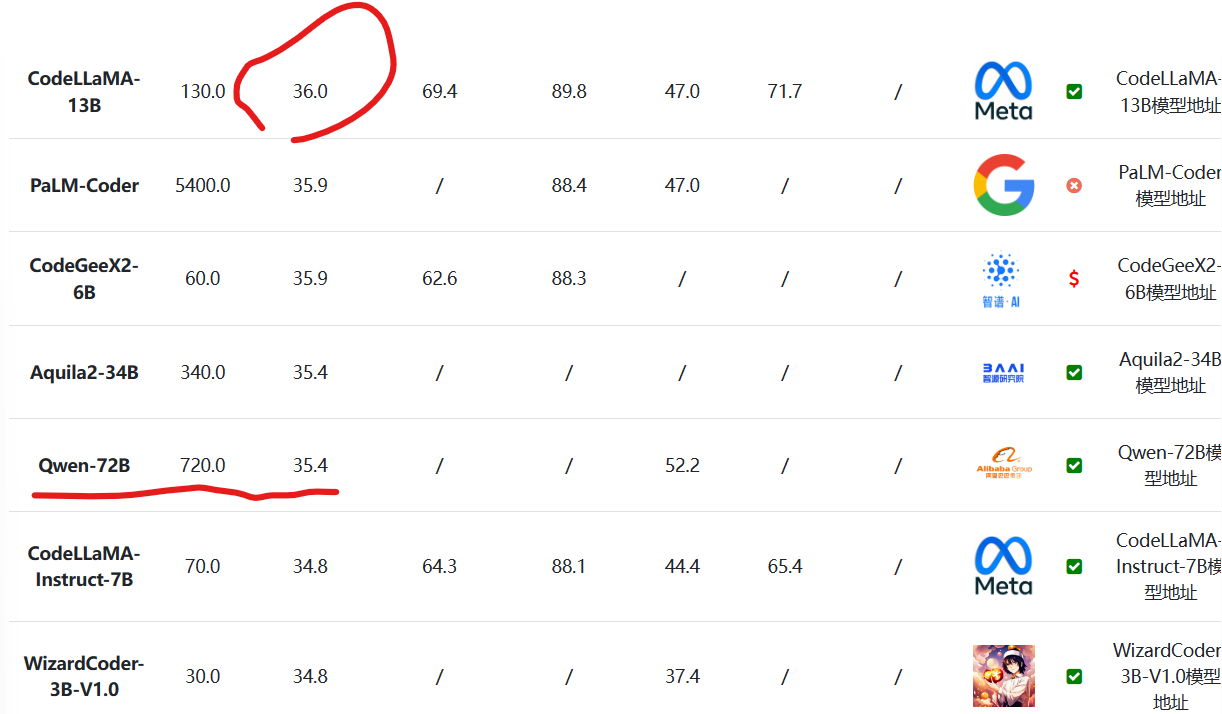
不过值得一提的是,这两个模型的代码评分都很一般,在HuamanEval得分上不如CodeLLaMA-13B:
Qwen-72B模型的开源地址和其它资源
Qwen-72B模型对学术和个人完全开放,商用的情况如果月活低于1亿(100 millions),那就直接商用即可。如果月活超过100万那则需要申请,申请应该也是免费。Qwen-72B模型商用申请地址:https://dashscope.console.aliyun.com/openModelApply/Qwen-72B-Chat
Qwen-72B地址和资源参考DataLearnerAI信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/Qwen-72B
Qwen-1.8B地址和资源参考DataLearnerAI信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/Qwen-1_8B
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
