MistralAI正式官宣开源全球最大的混合专家大模型Mixtral 8x22B,官方模型上架HuggingFace,包含指令微调后的版本!
今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
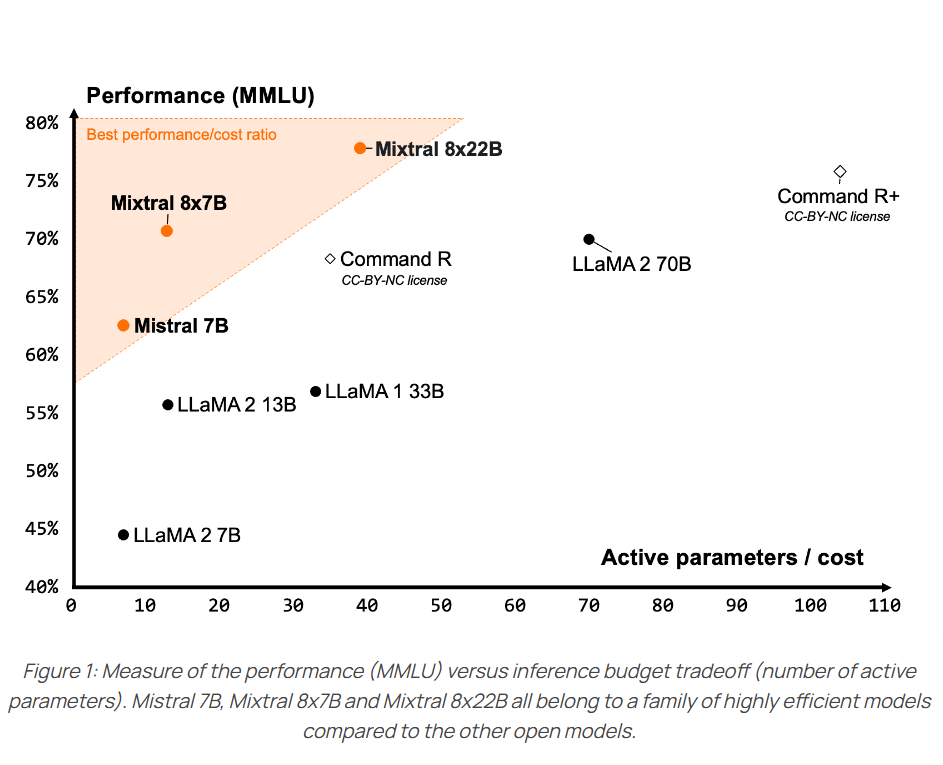
Mixtral-8×7B-MoE是由MistralAI开源的一个MoE架构大语言模型,因为它良好的开源协议和非常好的性能获得了广泛的关注。就在刚才,Mixtral-8×7B-MoE的继任者出现,MistralAI开源了全新的Mixtral-8×22B-MoE大模型。

在人工智能快速发展的今天,创新型模型如Mixtral 8x7B的出现,不仅推动了技术的进步,还为未来的AI应用开辟了新的可能性。这款基于Sparse Mixture of Experts(SMoE)架构的模型,不仅在技术层面上实现了创新,还在实际应用中展示了卓越的性能。尽管一个月前这个模型就发布,但是MistralAI今天才上传了这个模型的论文,我们可以看到更详细的信息。