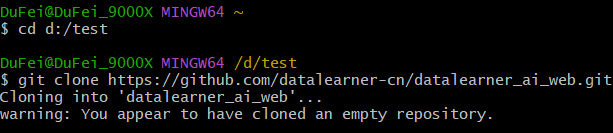
如何使用git从GitHub上下载项目、更新远端项目并提交本地的更改
介绍如何使用git下载远程、更新远程项目到本地,提交本地更改到远程
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
介绍如何使用git下载远程、更新远程项目到本地,提交本地更改到远程

昨天,Copilot团队推出了一个名为GitHub Copilot Labs的VS Code配套扩展。它独立于(并依赖于)GitHub Copilot扩展。它可以用来解释代码和翻译代码。

OpenAI在3月15日发布了一个最新的GPT-3和Codex的版本,这个版本最大的能力就是可以在已有的文本上插入或者编辑新的内容。而不是续写已有的文本。这个能力最大的应用就是重写已有文本,或者用来重构代码。
Git操作记录
tf.nn.softmax_cross_entropy_with_logits函数