LangChain提升大模型基于外部知识检索的准确率的新思路:更改传统文档排序方法,用 LongContextReorder提升大模型回答准确性!
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。
使用大模型基于外部文档数据进行检索问答的一般模式
尽管大模型的能力很强,但是在没有外部数据检索支持的情况下,所有的大模型只能回答其训练数据所覆盖的问题。当你的问题超出这些范围的时候,大模型是无法给出合理的答案。
因此,使用大模型基于私有知识的问答是大模型最常用的解决方案之一。下图是这个方法的主要流程:
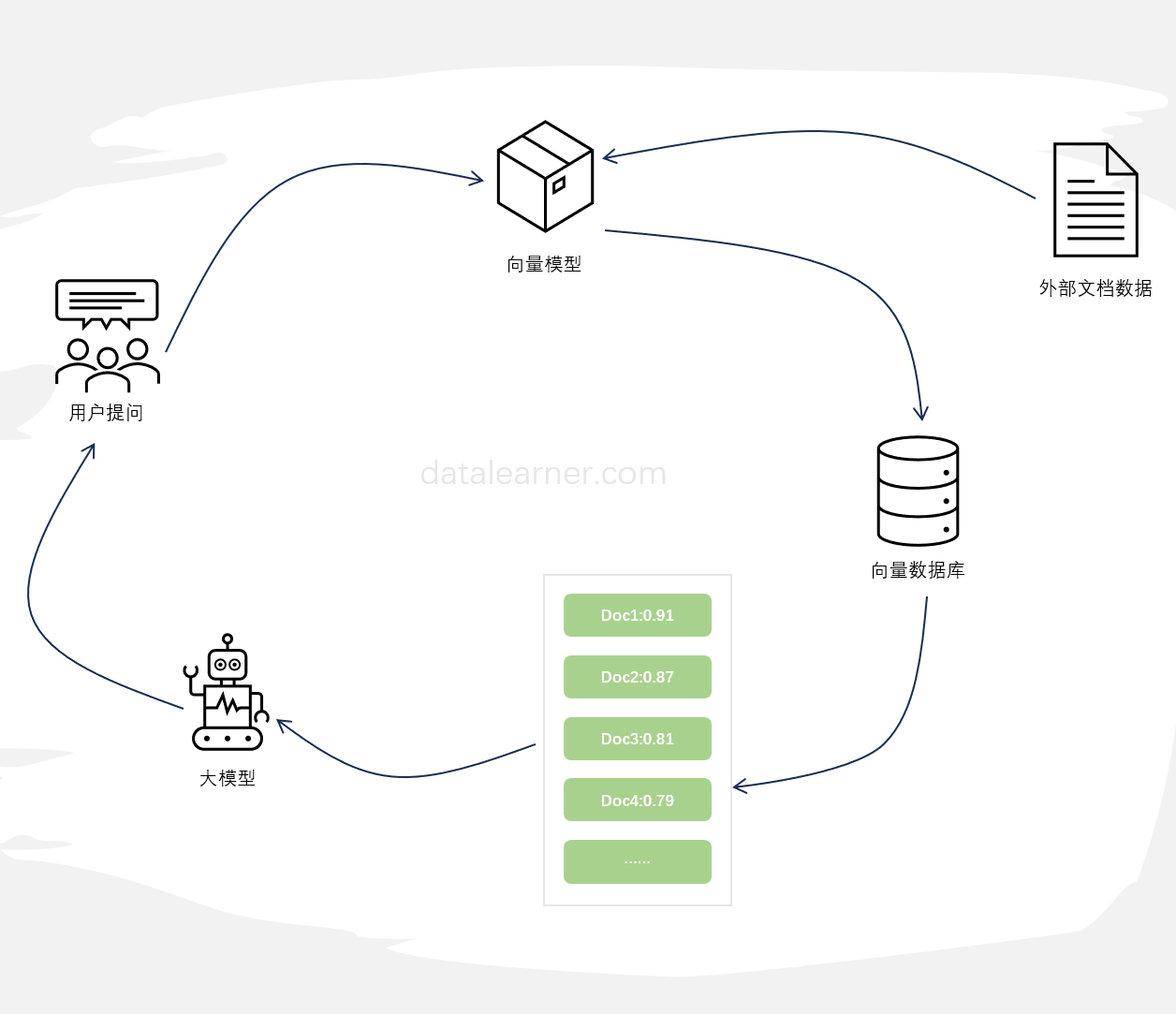
它的基本思想是通过以下步骤来生成回答:
-
信息检索(Retrieval):首先,系统使用检索技术(例如,从大型文档库中检索相关文档)来获取与用户提出的问题或查询相关的信息。
-
文本生成(Generation):接下来,系统使用大型语言模型(例如,GPT-3)来生成与检索到的信息相关的自然语言回答或解释。
这个方法的优势在于它能够利用外部知识库中的信息来支持生成更丰富、更准确的回答。但是,回答的准确性强烈依赖于检索步骤是否可以返回正确的内容。因此,这里需要解决2个问题:
-
如何找到与用户相关的数据?
-
如何让大模型基于返回的数据准确回答?
对于第一个问题,目前最常用的方式是使用向量大模型,将文本数据以向量的形式存入数据库,并通过向量的相似性检索的方式来匹配与用户提问相关的内容。这部分依赖向量大模型的向量化是否准确,也依赖外部数据是否有合理的分割(不能所有的知识转化成一个向量,而是需要分割数据后转化再存入向量数据库)。
第二个问题则是由于第一个问题不能完全解决导致的。向量检索返回的内容显然不止一个,这意味着需要大模型基于检索的结果进行回答。通常情况下,我们会根据文档与问题之间的向量相似度得分,将检索到的文档按降序插入到上下文中。
这里问题就来了,第一个问题不是本次关注的重点,我们关注第二个问题。
大模型在多文档检索问题的缺陷
当我们将第一步中返回的最相似的文档进行排序后,与用户的问题一起送给大模型,实际上是想让大模型在长上下文中准确识别定位到合适的内容进行回答。
这与多轮对话中的核心问题有点类似,就是需要在超长的内容中做主题检索(著名的开源大模型Vicuna的开发组织LM-SYS曾经做过大模型超长上下文测评,其核心观点就是大模型超长对话中的核心能力就是主题检索,参考:支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3)。
问题的关键在于,当我们将最检索得到的最相似的文档放在上下文的顶部,最不相似的文档放在底部时,大多数基于大型语言模型(Large Language Models,LLMs)表现都很差。这个研究和发现来自斯坦福大学此前的一项研究,参考:大模型如何使用长上下文信息?斯坦福大学最新论文证明,你需要将重要的信息放在输入的开始或者结尾处!
这个论文里面最核心的观点就是输入数据的重要信息没有出现在开始或者结尾位置,大模型可能会出现找不到答案的情况!如下图所示:
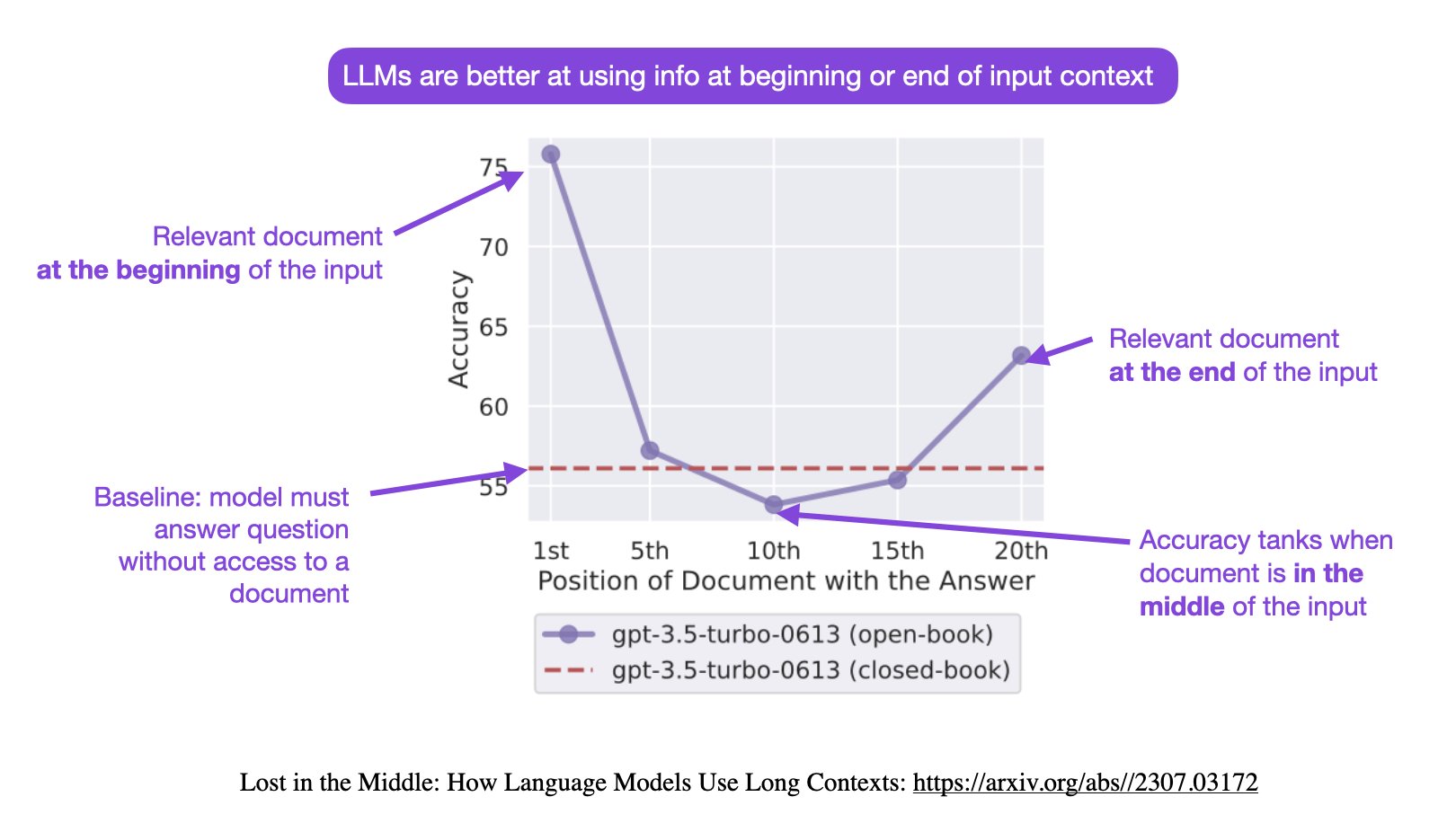
上图表明在大语言模型的输入上下文中改变相关信息的位置(即回答输入问题的段落的位置)会导致一个U形性能曲线——模型更擅长使用出现在输入上下文的开头或结尾的相关信息,而当模型需要访问和使用位于输入上下文中部的信息时,性能显著下降!
因此,如果我们将检索到的最相似的文档放在上下文的顶部,最不相似的文档放在底部时,大模型的系统往往会忽略上下文中间的文档。这意味着最不相似的文档被放在了一个LLMs容易忽略的位置,从而影响了性能!
emmmm~这是十分容易被忽视的问题!因为检索的不准确性,所以返回多个文档几乎是所有方案都会做的行为。而这自然而然的行为却可能造成很大的影响!
LangChain的解决方案
为了解决这个问题,LangChain提出了一种创新的方法,即在检索后重新排序文档。这种方法的关键思想是将最相似的文档放在顶部,然后将接下来的几个文档放在底部,将最不相似的文档放在中间。这样,最不相似的文档将位于LLMs通常容易迷失的位置。最重要的是,LangChain最新的LongContextReorder自动执行这个操作,使其非常便捷。
如下图所示:
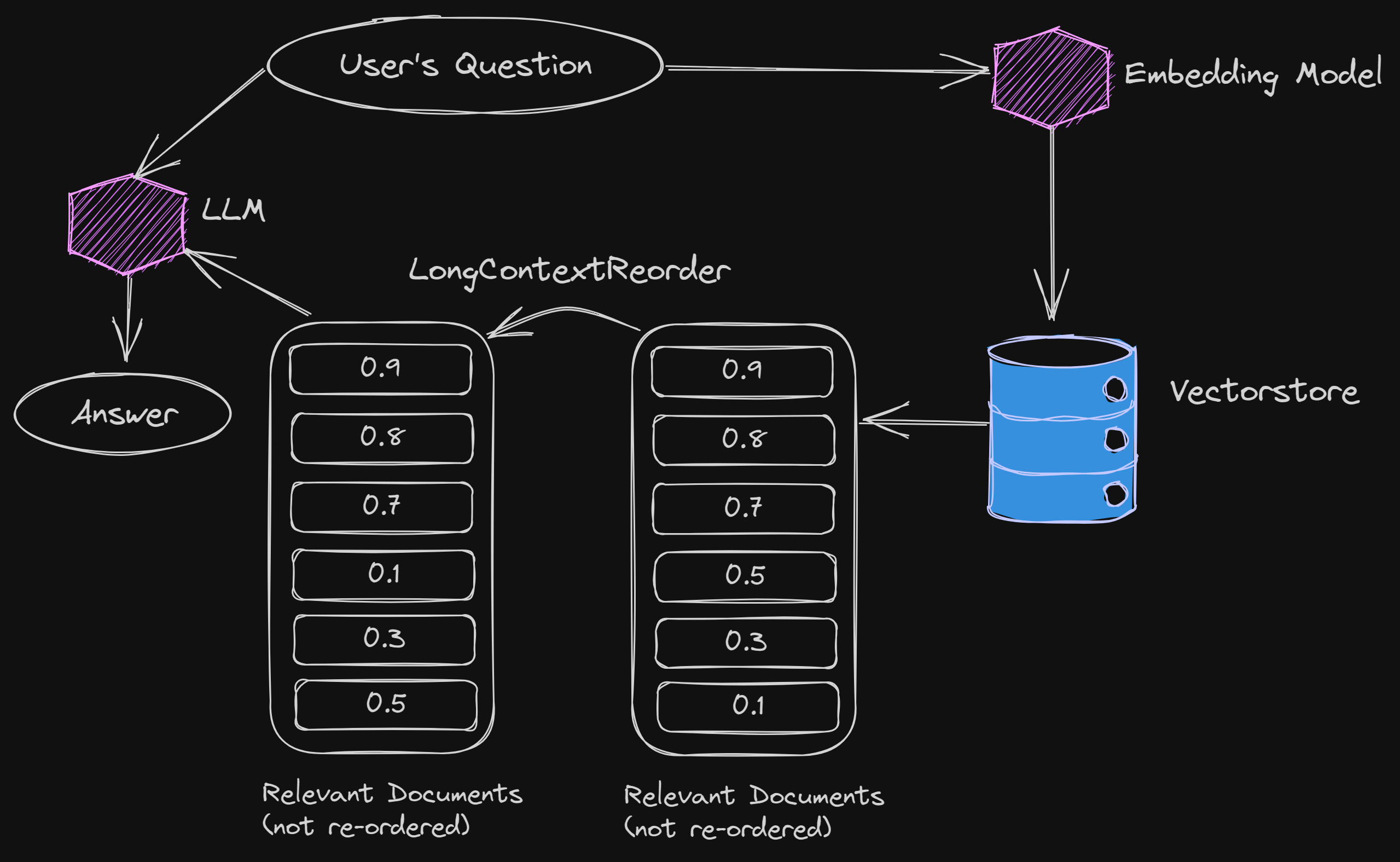
而这种方式只需要在原有的代码里面加入一行文档重排序即可,这意味着在实践中可以通过很多简单的方式直接测试这种排序的效果。
如何使用LangChain LongContextReorder
使用LangChain LongContextReorder非常简单。首先,您需要创建一个检索器,然后使用该检索器的"get_relevant_documents()"方法获取相关文档,这些文档会按照它们的相似度得分降序排列。接下来,将这些文档传递给LongContextReorder的实例,并获取重新排序后的文档,其中最不相关的文档位于中间。下面是一个示例代码:
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
上面的docs就是之前检索返回的文档集合,这里只需要做一次重排序即可。
LangChain LongContextReorder重排序实例
官方也给出了一个重排序的实例,例如原始的文档集合如下:
texts = [
"Basquetball is a great sport.",
"Fly me to the moon is one of my favourite songs.",
"The Celtics are my favourite team.",
"This is a document about the Boston Celtics",
"I simply love going to the movies",
"The Boston Celtics won the game by 20 points",
"This is just a random text.",
"Elden Ring is one of the best games in the last 15 years.",
"L. Kornet is one of the best Celtics players.",
"Larry Bird was an iconic NBA player.",
]
用户提问如下:
query = "What can you tell me about the Celtics?"
那么按照相似检索结果排序如下:
[Document(page_content='This is a document about the Boston Celtics', metadata={}),
Document(page_content='The Celtics are my favourite team.', metadata={}),
Document(page_content='L. Kornet is one of the best Celtics players.', metadata={}),
Document(page_content='The Boston Celtics won the game by 20 points', metadata={}),
Document(page_content='Larry Bird was an iconic NBA player.', metadata={}),
Document(page_content='Elden Ring is one of the best games in the last 15 years.', metadata={}),
Document(page_content='Basquetball is a great sport.', metadata={}),
Document(page_content='I simply love going to the movies', metadata={}),
Document(page_content='Fly me to the moon is one of my favourite songs.', metadata={}),
Document(page_content='This is just a random text.', metadata={})]
再经过重排序之后的结果:
[Document(page_content='The Celtics are my favourite team.', metadata={}),
Document(page_content='The Boston Celtics won the game by 20 points', metadata={}),
Document(page_content='Elden Ring is one of the best games in the last 15 years.', metadata={}),
Document(page_content='I simply love going to the movies', metadata={}),
Document(page_content='This is just a random text.', metadata={}),
Document(page_content='Fly me to the moon is one of my favourite songs.', metadata={}),
Document(page_content='Basquetball is a great sport.', metadata={}),
Document(page_content='Larry Bird was an iconic NBA player.', metadata={}),
Document(page_content='L. Kornet is one of the best Celtics players.', metadata={}),
Document(page_content='This is a document about the Boston Celtics', metadata={})]
可以看到,此前的This is just a random text.这种无关的文本已经被调整到中间位置了。新的问答将基于这种问答排序结果问答。
LongContextReorder重排序效果
目前,官方没有实测案例,不过官方博客说明再超过10个以上的检索结果中做这种重排序可以改善模型的输出效果。而此前论文中,测试的结果也是超过10个文档之后,文档越多,首尾内容对模型的理解能力影响越大。
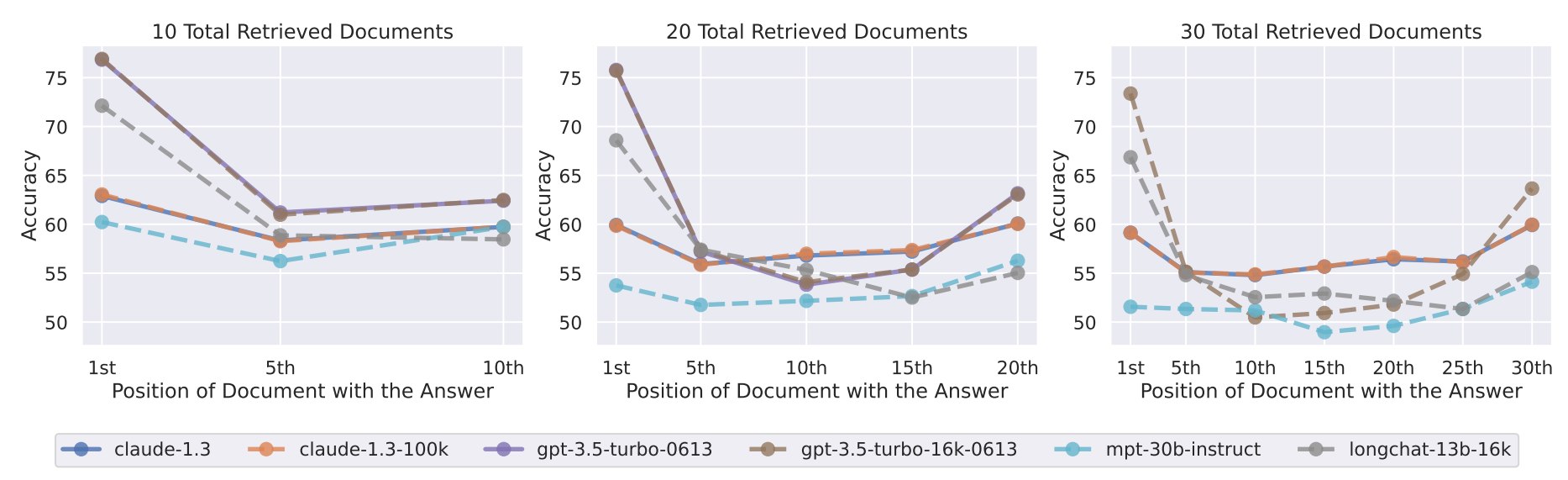
而且几乎所有的模型,包括GPT-3.5也有类似的情况。那么,根据这个结论,当返回的知识检索结果超过10个之后,这种重排序应该会很好建议大家可以跟进了
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
