检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结
检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。但是,如果文档切分有问题、检索不准确,检索增强生成可能也会有很多问题。本文基于LangChain提供的一些方法给大家总结一下有哪些提高检索增强生成的方式。

检索增强生成简介及其提高效果方法概述
在此前,DataLearnerAI曾经详细介绍过关于向量检索增强生成的方法及其主要问题。
简单来说,向量检索增强生成是一种结合向量空间的检索能力和大模型生成能力的解决方法。通过将输入数据映射到高维向量空间中,系统可以快速地找到与之相似的向量完成大模型所需上下文结果。这种方法可以让大模型接入实时数据或者外部私有数据,对大模型来说具有很好的扩展性。
一个典型的向量检索增强生成系统流程如下:
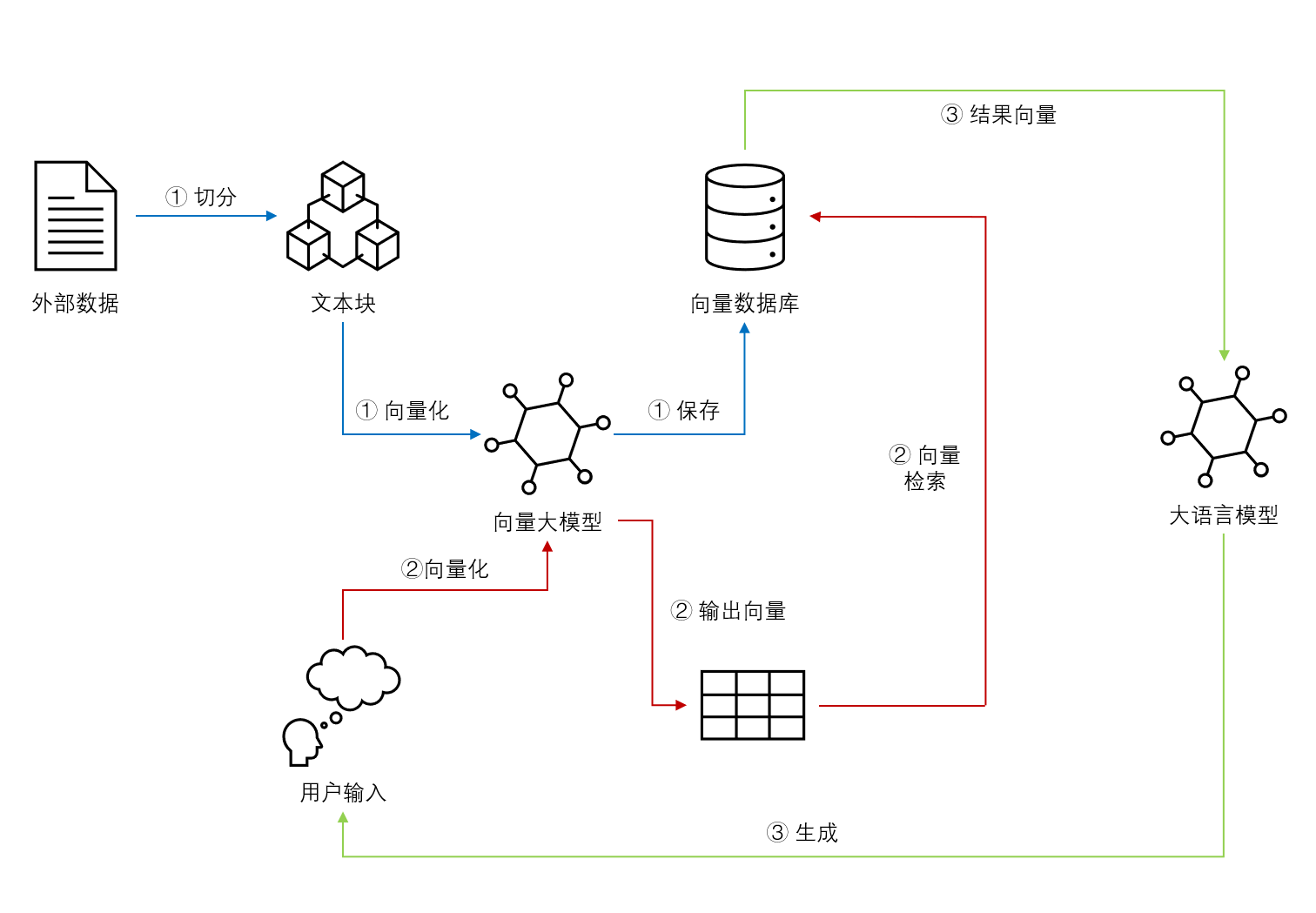
但是检索增强也有很多问题,例如向量匹配不准确、文档切分复杂等。针对这些问题也有一些解决方案。
下表是LangChain总结的当前提升RAG效果的一些方案:
下面我们就针对向量检索增强生成来介绍一下提升效果方案。 多向量检索器 (Multi-Vector Retriever) 是这篇文档中提到的一个关键工具,用于优化RAG(Retrieval Augmented Generation)的过程。以下是它的关键要点和功能:
向量检索增强生成提升方案之摘要总结:LangChain的多向量检索器
多向量检索器 (Multi-Vector Retriever) 是LangChai推出的一个关键工具,用于优化RAG(Retrieval Augmented Generation)的过程。多向量检索器的核心想法是将我们想要用于答案合成的文档与我们想要用于检索的参考文献分开。这允许系统为搜索优化文档的版本(例如,摘要)而不失去答案合成时的上下文。
下图是一个多向量检索器的示意图:
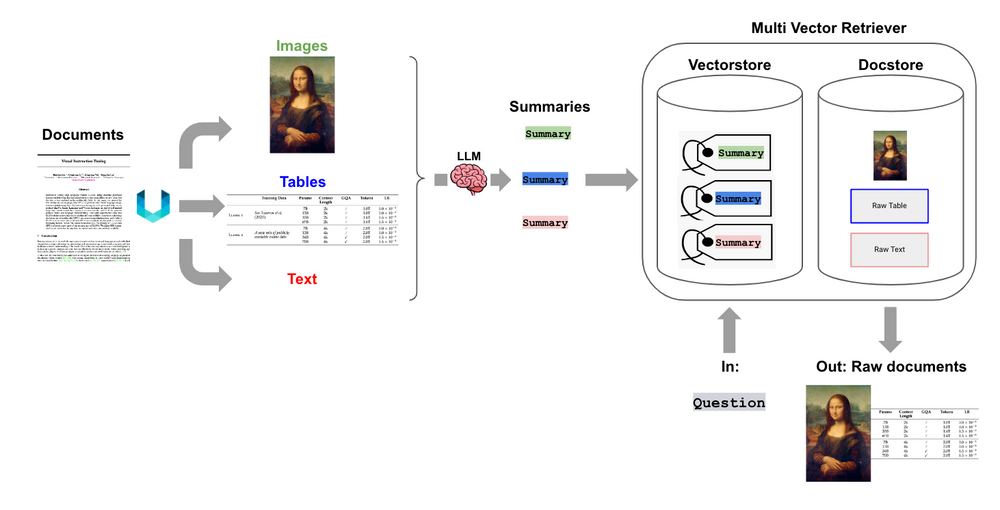
考虑一个冗长的文档。我们可以为该文档创建一个摘要,该摘要经过优化以进行基于向量的相似性搜索。但当需要生成答案时,我们仍然可以将完整的文档传递给LLM,确保在答案合成过程中不会丢失任何上下文。
简单来说就是将一个文档分解为较长的几个逻辑较为完整和独立的部分,例如包括不同的文本、表格甚至是图片都可以,然后分解后的文档使用摘要的方式进行总结,这个摘要需要可以明确覆盖相关内容。然后摘要进行向量化,检索的时候直接检索摘要,一旦匹配,即可将摘要背后的完整文档作为上下文输入给大模型。
多向量检索器的方案优点总结如下:
-
效率和速度:通过使用摘要进行向量化检索,检索过程更加迅速。摘要的数据规模相对较小,使得相似性搜索更加高效。
-
准确性提高:摘要提供了文档的核心信息,这有助于提高与查询相关的文档的检索准确性。
-
丰富的上下文:在答案合成阶段使用完整的文档可以确保LLM有足够的上下文来生成准确和全面的答案。
-
灵活性:多向量检索器的设计可以轻松适应不同类型的数据,例如文本、表格或图像,为多模态数据提供支持。
-
数据解耦:将文档(用于答案合成)与检索引用(用于检索)分开,为系统提供了更大的灵活性和可扩展性。
-
应对半结构化和多模态数据:这种方法不仅可以处理纯文本,还可以处理含有表格、图像等多种数据类型的文档,使其在处理更复杂的数据集时仍然有效。
-
保留关键信息:即使在处理大型或复杂文档时,摘要也能确保关键信息得到保留,从而提高检索的相关性。
-
降低资源需求:相对于在完整文档上进行检索,使用摘要可以减少计算和存储资源的需求。
总之,这种方法结合了摘要的高效检索能力和完整文档的上下文丰富性,为用户提供了既快速又准确的答案。
不过,仅基于摘要进行检索存在这样的风险:如果摘要没有充分捕获到文档的全部重要信息,那么在搜索过程中可能会错过关键的答案。
向量检索增强生成提升方案之查询转换:LangChain的Query Transformations
如前所述,RAG方法存在一些问题,如文档块可能包含与检索无关的内容,用户问题可能表述不佳,或可能需要从用户问题中生成结构化查询。
具体来说包括:
-
内容的不相关性:传统的检索方法可能会返回含有与问题不相关的内容的文档块。这可能会降低检索的质量,因为返回的内容可能不完全符合用户的期望。
-
用户问题的表述问题:用户提出的问题可能表述不清或用词不准确,这可能导致检索系统无法准确地理解其意图并返回相关的答案。
-
复杂的查询需求:有时,用户的问题可能需要转换为更复杂的结构化查询,例如用于带有元数据过滤的向量存储或SQL数据库的查询。
为了解决上述问题,查询转换(Query Transformations)的方案利用了大型语言模型(LLM)的强大能力,通过某种提示或方法将原始的用户问题转换或重写为更合适的、能够更准确地返回所需结果的查询。LLM的能力确保了转换后的查询更有可能从文档或数据中获取相关和准确的答案。
下图是这种方案的展示:
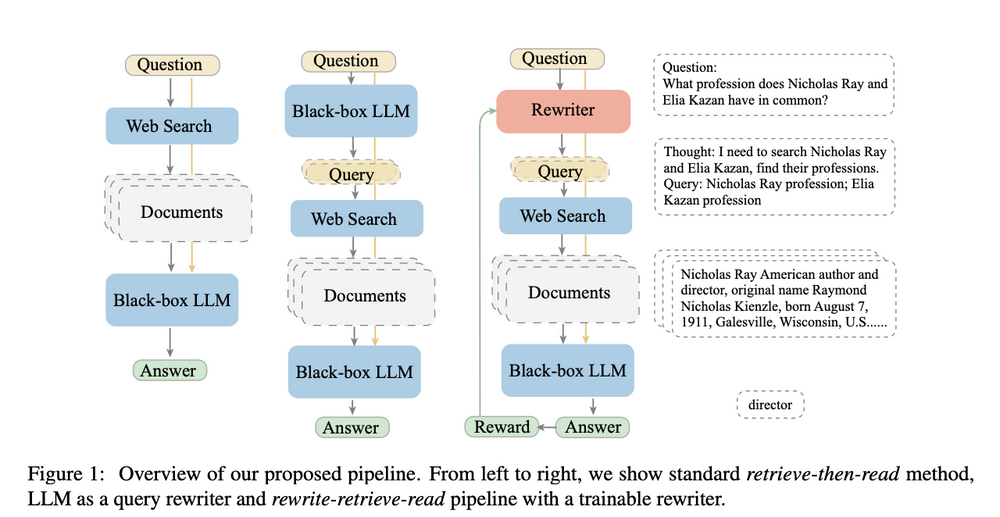
可以看到,查询转换的出发点是为了克服传统检索方法的局限性,利用LLM的能力优化和改进用户问题,从而提高检索的效果和满足用户的需求。
以下是这些方法的详细描述:
-
重写-检索-阅读(Rewrite-Retrieve-Read):
- 目的:直接使用原始的用户查询可能不总是最佳的,因此先使用LLM重写查询,然后进行检索和阅读。
- 执行方式:首先提示LLM重写查询,然后进行检索增强阅读。
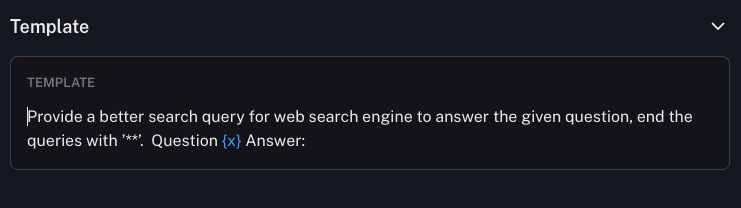
- 使用的提示:该方法使用了一个相对简单的提示。如下图所示:
-
退后提示(Step back prompting):
- 目的:生成一个“退后”的问题,在使用检索时,将同时使用“退后”问题和原始问题进行检索,然后使用这两个结果来支持语言模型的响应。后退问题是从原始问题派生出来的、抽象层次更高的问题。例如,原始问题是“Estella Leopold在特定时期去了哪所学校”,这个可能很难回答。但如果不是直接询问"Estella Leopold在特定时期去了哪所学校",我们文一个后退问题会询问她的"教育历史"。这个更高层次的问题涵盖了原始问题的所有信息。很容易得到答案。
- 执行方式:使用LLM生成一个退后的问题。
- 使用的提示如下:
You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
{normal_context}
{step_back_context}
Original Question: {question}
Answer:
- 跟进问题(Follow Up Questions):
- 目的:处理跟进问题,尤其是当它们是基于或引用先前的对话时。
- 方法:
- 只嵌入跟进问题:这意味着如果跟进问题是基于或引用先前的对话,它将失去该上下文。
- 嵌入整个对话(或最后k条消息):如果跟进问题与先前的对话完全无关,那么可能会返回完全无关的结果。
- 使用LLM进行查询转换:将整个对话(包括跟进问题)传递给LLM,并要求其生成搜索词。
- 使用的提示:需要大量的提示工程。下面是一个例子:
Given the following conversation and a follow up question, rephrase the follow up \
question to be a standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone Question:
-
多查询检索(Multi Query Retrieval):
- 目的:使用LLM生成多个搜索查询,尤其是当一个问题可能依赖多个子问题时。
- 示例:考虑以下问题:“谁最近赢得了冠军,红袜队还是爱国者队?”这实际上需要两个子问题的答案。
-
RAG-Fusion:
- 目的:建立在多查询检索的思想之上。不是传递所有文档,而是使用互惠排名融合来重新排序文档。
- 执行方式:不是将所有的文档传入,而是使用互惠排名融合来重新排序文档。
查询转换的核心思想是,用户的原始查询可能不总是最适合检索的,所以我们需要某种方式来改进或扩展它。使用LLM进行查询转换提供了一个非常有前景的方法来实现这一目标。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
