如何对向量大模型(embedding models)进行微调?几行代码实现相关原理
大语言模型可以通过收集少量专门数据对模型的部分权重进行更新后得到一个比通用模型更加专业的模型,这就是微调。但是,当前大家讨论较多的都是大语言模型的微调,对于嵌入模型(或者向量大模型)的微调讨论较少。Modal团队的工作人员发布了一个博客,详细介绍了向量大模型的微调工作,本文将其翻译之后提供给大家(原文:https://modal.com/blog/fine-tuning-embeddings )。
本文原文有些啰嗦,但是是很好的入门教程,可以帮助我们理解一些基本向量大模型基本知识,也有代码实例。代码参考:https://github.com/567-labs/fastllm/blob/main/applications/finetune-quora-embeddings/Readme.md
使用少量示例,经过微调的开源向量大模型可以在较低成本下提供比专有模型(如OpenAI的text-embedding-3-small)更高的准确性。在本文中,我们将解释如何使用Modal平台创建一个这样的模型。首先,我们将介绍微调的基础知识。然后,我们将讨论一个实验,以确定简单问答用例所需的微调数据量。
微调的意义
开源模型让你起步
定制模型至关重要。这就是为什么Netflix能不断推荐更好电影、Spotify能找到新的歌曲推荐列表。通过跟踪用户何时看完所选电影或是否跳过某首歌,这些公司积累了大量数据,并利用这些数据改进内部嵌入模型和推荐系统,从而提供更好的建议和用户体验。这甚至会带来更多用户的参与,形成数据-模型-用户的良性循环,这被称为“数据飞轮”。

像Netflix和Spotify这样的机器学习领先企业,已经利用数据飞轮从零开始创建了自己的模型,并且积累了大量数据。然而,当你刚开始一个新公司或项目时,并不总是拥有所需的数据。2010年代,启动数据飞轮需要相当的创造力或资源投入。
但是在2020年代,具有高性能的通用预训练模型及其宽松的许可证大大简化了这个启动步骤。你可以从一个训练来识别大型多样化数据集模式的模型开始,并期待它们在你的任务中表现良好。
在之前的一篇博客文章中,我们通过Modal的自动扩展基础设施展示了如何在数百个GPU上部署一个现成模型,在不到15分钟内嵌入整个英文维基百科。
大模型微调技术可以快速启动数据飞轮
这些(通用预训练)模型和运行它们的基础设施的可用性对于刚起步且没有用户数据的组织来说是个好消息。但关键是如何尽快转向一个定制模型,以提供比现成模型更好的性能。幸运的是,数据积累非常迅速:仅需几十个用户每天与服务互动3-4次,就能在几天内创建数百个数据点。
这就是我们所需的全部数据,用来训练一个模型,该模型在识别文本相似性上优于OpenAI的text-embedding-3-small。
我们用于创建嵌入的同样可扩展的无服务器基础设施也可用于自定义模型,这一过程称为微调。最终结果是一个具有优越性能且运营成本显著降低的机器学习应用:这是启动你自己数据飞轮的第一步。
注意:简单来说,本段的含义就是使用大模型微调技术可以快速用收集的数据提升模型的水平,原文写的有点啰嗦。
微调的方法:数据集、模型和基础设施
在微调模型时,需要做出许多设计决策。我们在此回顾一些。
注意:本段主要描述微调工作之前的一些技术选型工作。
寻找或创建数据集
尽管机器学习中的大部分讨论和研究都是围绕模型展开的,但任何有经验的机器学习工程师都会告诉你,数据集是最关键的组成部分。
向量大模型通常训练于由成对项目组成的数据集,其中一些对被标记为“相似”(如来自同一段落的句子),而一些被标记为“不同”(如随机选择的两个句子)。这一原则可以应用于比句子更长的文本,如段落、页面、文档等。也可以是其他类型的项目:如图像、歌曲、用户点击流。甚至是多种模态的组合:如图像及其说明、歌曲及其歌词、用户点击流和购买的产品。
注意:简单来说,向量大模型的微调的主要目标是让模型能区分不同文本的相似性,所以这些数据一般都是成对的数据,其中会有标签标注成对的数据之间是否是相似的。
我们将使用Quora数据集,其中包含来自Quora帖子的问题对,一些对被标记为重复(也就是前面说的这些问题是相似的)。(数据地址:https://huggingface.co/datasets/quora )
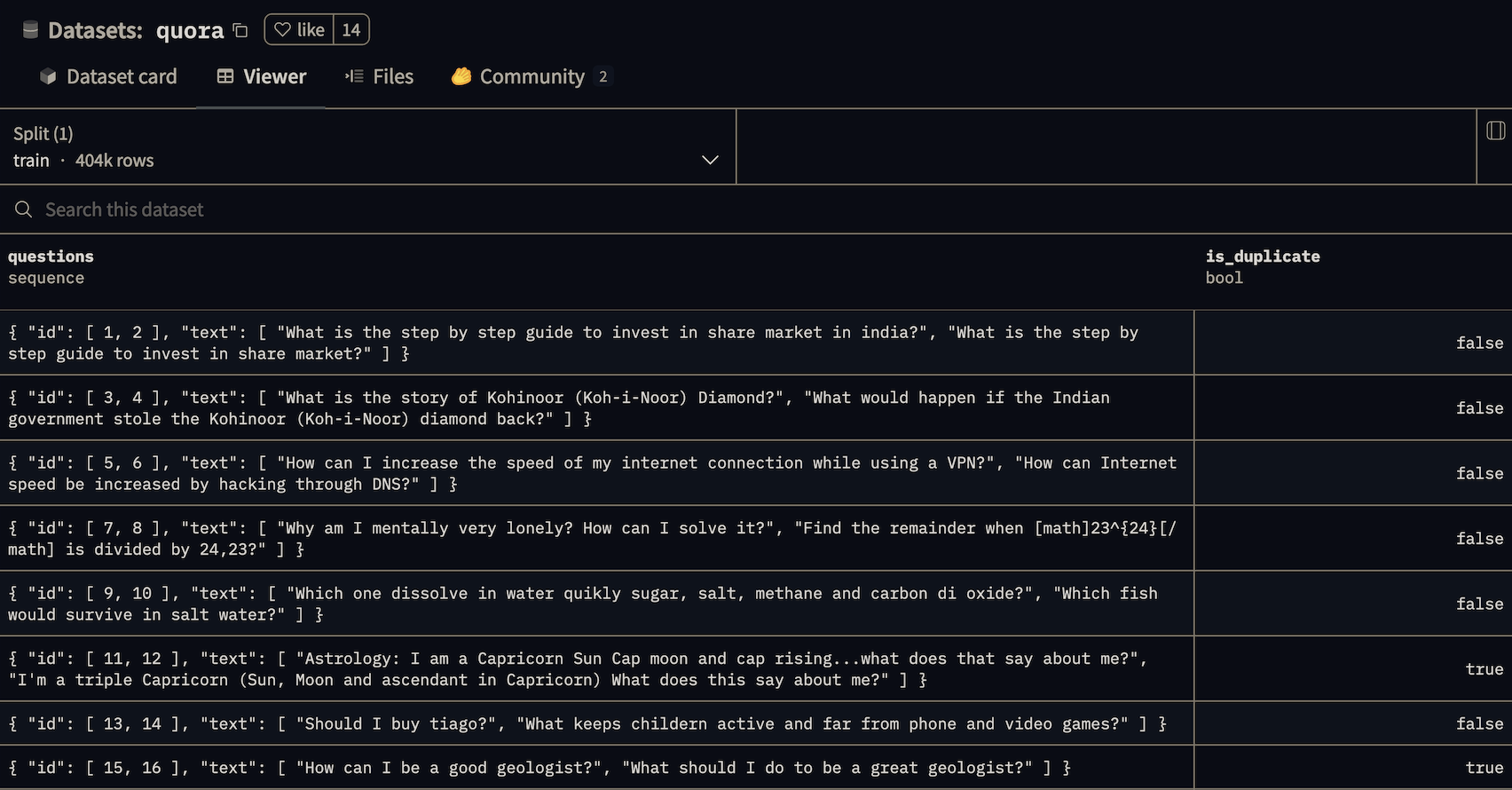
你可以在Hugging Face数据集查看器中查看Quora重复数据集的示例行(地址:https://huggingface.co/datasets/quora/viewer/default/train )。一些问题对,如“我可以破解我的Charter Motorolla DCX3400吗?”和“如何破解Motorola DCX3400以获得免费互联网?”非常相似,但不是重复的,即所谓的“困难负样本”。
这使得我们训练的模型在检索增强生成(RAG)聊天机器人中可能有用。在基于向量检索的RAG中,必须在大量文本中搜索少量与用户查询“匹配”的段落,即可能包含答案的段落。这个数据集将训练模型对问题主题的微小差异敏感。在检索之前或训练其他模型之前,近重复项也可以删除,这一技术称为“语义去重”。
选择基础模型
我们将主要关注具有宽松许可证的可用权重模型。这些模型具有你可以下载和修改的权重,就像下载和修改开源代码一样。因此,我们在这里称它们为“开源”模型,尽管没有适用于模型的开源倡议认可的“开源”定义。这些模型通常通过Hugging Face的git LFS模型存储库发布,我们将在那里获取我们的模型。
或者,我们可以使用API来微调专有模型,正如一些嵌入API服务所提供的那样。除了成本问题,我们发现微调模型足够复杂且特定于用例,因此控制训练过程是必要的。
如何在现有模型之间选择?每个模型的训练方式不同,并且针对特定的用例进行训练。最关键的是,模型是在特定模态或模态组合(文本、图像、音频、视频等)和特定数据集上训练的。一旦你缩小了处理你用例中模态的模型范围,就可以比较它们在公共基准(如MTEB)上的性能。除了任务性能外,还要审查模型在资源需求和吞吐量/延迟方面的表现,同样通过公共基准数据(硬件提供商如Lambda Labs是一个很好的资源)。
例如,嵌入维度或模型输出嵌入中的条目数量是一个重要考虑因素。较大的向量可以存储更多信息,导致更好的任务性能,但随着时间的推移嵌入更多数据时,成本会显著增加(成本更像RAM而不是磁盘)。在微调时,我们可以调整这个维度。
获取训练基础设施
微调模型需要大量计算资源。即使是后来可以在CPU上满意运行的模型,甚至是客户端或边缘CPU,通常也会在GPU上训练,GPU在易于并行化的工作负载(如训练)上可以实现高吞吐量。
对于典型的微调工作,我们需要一到八个服务器级GPU。由于连接性限制,超过八个GPU通常需要在多个节点上分布训练,这显著增加了硬件成本和工程复杂性
这里解释一下,原因是之前的英伟达的服务GPU的NVLINK连接最多8个GPU,所以说不超过8个。NVLINK连接的GPU组可以当作一个来用,效率很高。
但服务器级GPU如今稀缺,这意味着它们购买或租赁都很昂贵,云提供商通常要求最小规模和持续时间的预订。但微调工作不像生产工作流程(总是有合理可预测的流量),更像是开发工作流程(间歇性、不可预测)。结合这些现象,导致了大规模的过度分配和过度支出。据ClearML和AI基础设施联盟的这项调查报告,组织报告的峰值利用率平均约为60%,离峰期甚至更低。
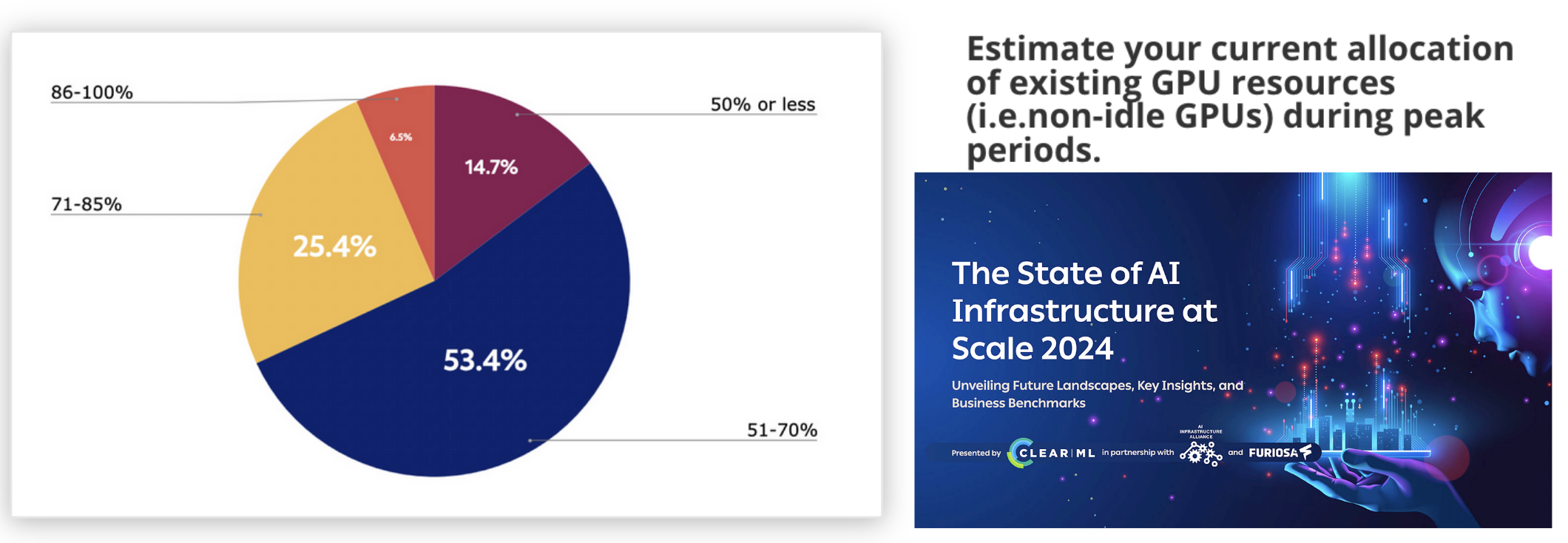
Modal解决了这个问题:它提供自动扩展基础设施,包括GPU,因此你只需为所使用的部分付费(即“无服务器”)。Modal还提供了一个Pythonic的基础设施代码接口,使数据科学家和机器学习研究人员能够拥有和控制他们的基础设施。(这段是广告)
有了这些资源,我们需要确定如何确定模型训练过程的范围。我们在训练超参数和数据调整上的时间和金钱投入越多,任务性能就会越好,但收益递减。一般来说,我们建议在某些指标上训练到满意为止(例如至少90%的准确性),或者选择一组要满足的指标并最大化一个指标(例如,召回率≥50%时的最高准确性),然后设定资源和时间的硬性限制。
在微调超参数上进行网格搜索
确定如何训练一个全新的模型架构或一个全新的任务是一个研究项目,应相应地进行范围界定。但微调比较简单——我们可以使用现有的训练配方(如果模型是开源的)。但仍然有实验的空间,包括在上述许多考虑因素上。
我们选择了三个我们认为最重要的实验参数:我们应该训练哪个预训练模型、数据量和输出维度是多少?由于这些实验参数决定了模型中的参数(权重和偏置)的值,因此它们被称为超参数。
探索超参数的最简单方法是定义每个超参数的一组可能值,然后检查所有组合——即网格搜索。这是一种蛮力方法,但正如我们下面所见,它是有效且易于并行化的。
我们在Wikipedia嵌入示例中使用的原始bge-base-en-v1.5模型中增加了两个额外的模型,并尝试了两种不同的嵌入维度。对于这些配置中的每一个,我们测试了从一百到十多万个样本的不同数据集大小:
MODELS = [
"BAAI/bge-base-en-v1.5"
"sentence-transformers/all-mpnet-base-v2"
"jinaai/jina-embeddings-v2-small-en"
]
DATASET_SIZE = [
100 200 400 800 1600 3200
6400 12800 25600 51200 102400
]
DENSE_OUT_FEATURES = [256 512]
所有其他超参数均保持不变。
接下来,我们使用标准库模块itertools提供的product函数生成所有可能的model、dataset_size和dense_out_features组合,该函数创建一个迭代器,返回每个输入列表元素的所有可能组合(即笛卡尔积)。然后,我们使用这些组合生成模型微调过程的配置对象:
def generate_configs():
for model, sample_size, dense_out_features in product(
MODELS, DATASET_SIZE, DENSE_OUT_FEATURES
):
yield grid_search_config(model, sample_size, dense_out_features)
无论我们的微调过程是什么,它都会接受配置并生成一些结果字典。我们将其包装在一个函数中,并用@app.function()装饰,使其可以在Modal的自动扩展基础设施上运行,如下伪代码所示。
@app.function(gpu="A10G") # 在此配置自动扩展和其他基础设施参数
def objective(config) -> dict:
model = Model.from_config(config)
model.setup()
results = model.train()
return results
从那里开始,扩展只需调用objective.map以并行运行实验。我们将其包装在一个函数中,并用@app.local_entrypoint()装饰,以便我们可以使用modal run从命令行启动实验。
@app.local_entrypoint():
def run():
results = []
for experiment_result in objective.map(generate_configs()):
results.append(experiment_result)
df = pd.DataFrame(results).sort_values("metric_accuracy", ascending=False)
df.to_csv("trial_results.csv", index=False)
我们的训练过程适合在单个GPU上运行,每个实验并行运行,因此我们可以将其扩展到Modal允许的最大并发GPU工作器数——截至撰写本文时为数千个。对于大型训练作业,这可能意味着结果在下周还是午餐后得到的区别。
用几百个示例击败专有模型
下图总结了我们的实验结果,显示了我们在Quora数据集上训练的模型的错误率(预测错误的比例),作为微调期间使用的数据集示例数量的函数,每个模型一个图。OpenAI的text-embedding-3-small模型的性能用于对比(虚线的错误率)。为了完整起见,我们显示了测试的两种不同嵌入维度大小,尽管我们没有观察到在其他超参数设置下它们之间的性能差异。
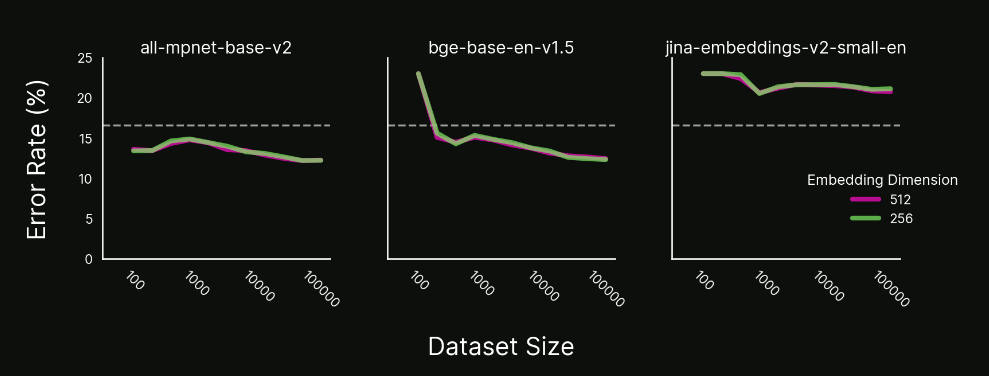
在Quora数据集上微调的三个模型的错误率作为数据集大小的函数。 在这三个案例中,我们看到了一些常见的微调模式:
- 对于jina-embeddings-v2-small-en模型,错误率高于基线,且从未下降。与往常一样,不同超参数设置可能会带来更好的性能。这种结果是你在超参数搜索中不想看到的,因为不知道下一步该做什么。(简单说这个模型怎么调都没用)
- 对于all-mpnet-base-v2模型,错误率在仅100个示例后低于基线,但即使增加到三数量级的示例,也没有观察到明显的改进。
- 对于bge-base-en-v1.5模型,错误率开始高于基线模型,但随着数据增多迅速改善,在200个示例时明显优于基线,并在100000个示例时仍在改善。
审查这些结果后,我们将继续使用微调后的bge-base-en-v1.5模型,特别是如果我们期望通过数据飞轮收集更多数据。我们可能会选择256维嵌入,因为它们比512维嵌入便宜,且我们没有观察到使用较大嵌入的准确性收益。
你可能会认为相对于基线的改进在绝对值上很小——错误率从17%下降到13%。但相对来说,这是一个很大的差异:基线模型四分之一的错误被微调模型避免了。这种现象在错误率降低时更为显著:99%可靠性的系统可以在95%可靠性不可接受的情况下使用,尽管差异的幅度似乎很小。
后续步骤
在本文中,我们展示了如何微调一个开源嵌入模型,以在简单问答任务中击败专有模型。我们还讨论了微调模型时需要考虑的因素以及如何使用Modal在超参数上进行网格搜索。我们展示了即使只有几百个示例,我们也可以比专有模型取得更好的性能。 展望未来,微调的下一步是使这一过程操作化,以便我们可以收集更多数据并迭代模型。通过完全自动化,我们甚至可以将模型转化为一个不断改进的系统,由我们收集的附加数据驱动。 远不止模型,这些将数据转化为对用户有用功能的管道和流程是机器学习团队的输出。通过开源模型和无服务器基础设施,构建它们比以往任何时候都更容易。
