ToolTalk:微软发布的一个用以评测大语言模型工具使用能力的评测工具和评测数据集
随着大语言模型能力的提升,大语言模型已经不再被认为是一个纯粹的文本输出模型了。在很多的生产应用领域,如客服机器人、项目管理、编程辅助等都有很多的应用。这些应用领域强调的是大语言模型对于工具的选择和使用。这意味着要求模型可以识别常见的工具,如API接口、脚本语言等,也需要大语言模型有更好的推理和任务的分解能力。这些对于大语言模型能力的评测也提出的新的要求。
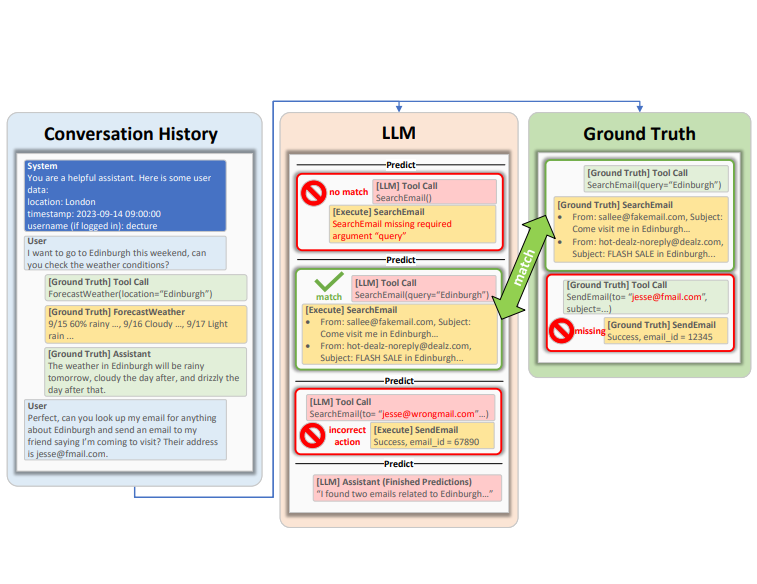
为了更好地评估大语言模型的工具使用能力,微软的研究人员提出了ToolTalk Benchmark基准测试工具,可以帮助我们更加简单地理解大语言模型在工具使用方面的水准。ToolTalk是微软在2023年11月发布的,来自于论文《ToolTalk: Evaluating Tool-Usage in a Conversational Setting》
ToolTalk评测基准简介
简单来说,ToolTalk旨在评估大型语言模型(LLMs)在对话环境中使用工具的能力。这些工具可以是搜索引擎、计算器或Web API等,它们能够帮助LLMs访问私有或最新的信息,并代表用户执行操作。
ToolTalk会提示 LLM 进行工具调用预测并模拟执行。这将被添加到对话历史记录中,并提示 LLM 进行另一次预测。这种情况一直持续到 LLM 预测出助理响应为止。然后,LLM 的预测将被遗忘,并在下一个助手回合中重复这一过程。然后将预测的工具调用与地面实况工具调用进行比较。
ToolTalk基准测试包含28种工具,分为7个插件,涵盖了从账户管理到日历事件管理等多种功能。这些工具通过对话指定,需要多步骤使用,并且包括了完整的模拟实现,允许对依赖执行反馈的助手进行完全自动化的评估。ToolTalk特别强调那些能够对外部世界产生影响的工具,而不仅仅是用于查询或搜索信息的工具。
ToolTalk的评测结果
ToolTalk分为2个版本,简单的和困难的。在最开始的论文中,ToolTalk测试了GPT-3.5和GPT-4,结果如下:
可以看到,即使是最先进的模型,在对话环境中使用工具仍然是一个挑战。
大语言模型使用工具时最常见的错误
根据论文中的分析,作者提出了三个主要的工具使用错误类别,这三类错误可以帮助我们理解当前大模型在调用工具时候有的问题:
-
过早的工具调用(Premature tool calls):这种错误通常发生在用户有一个明确的意图,例如“我想创建一个事件”,但尚未提供足够的信息作为参数。在这种情况下,模型可能会幻想出合理的值来作为参数,这在预测参考工具时是无害的,但在预测动作工具时会直接导致失败。即使幻想出的参数会导致执行错误,模型仍然会坚持幻想更多的参数。
-
错误的推理(Faulty planning):最终,过早的工具调用可以主要归因于错误的推理,即LLM未能反映它没有所有必要的信息来完成任务,并且需要请求用户提供更多的澄清。同样,遗漏或使用错误的工具也可以归因于错误的推理技能;而不是反思并意识到它需要请求用户提供更多的澄清,LLM未能意识到它需要调用额外的工具来完成任务。
-
正确工具的错误调用(Incorrect tool invocations):即使模型选择了正确的工具,它也可能以不正确的参数调用工具,例如遗漏值或提供错误的值。这可能是由于未能理解文档、未能理解先前工具调用的输出或数学技能不足等原因造成的。例如,提供下午2点作为“2:00”而不是“14:00”;计算一个10小时的事件结束时间为下午6点到凌晨12点;错误地提供刚刚创建的提醒到DeleteReminder工具中。
ToolTalk开源地址和完整的工具类别
微软开源了ToolTalk工具,它的GitHub地址:https://github.com/microsoft/ToolTalk
微软也给出了ToolTalk完整的工具类别,统计如下:
