
OpenAI Harmony 消息格式技术详解:一种为高级 Agent 设计的精细化消息格式
近日,OpenAI在发布其开源模型gpt-oss-120b和gpt-oss-20b的同时,也推出了一种专为这些模型设计的全新消息格式——Harmony。对于希望在自有解决方案中充分利用这些开源模型的开发者而言,理解Harmony至关重要。本文将以客观的第三方视角,详细解析Harmony格式的设计理念与技术细节。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
近日,OpenAI在发布其开源模型gpt-oss-120b和gpt-oss-20b的同时,也推出了一种专为这些模型设计的全新消息格式——Harmony。对于希望在自有解决方案中充分利用这些开源模型的开发者而言,理解Harmony至关重要。本文将以客观的第三方视角,详细解析Harmony格式的设计理念与技术细节。
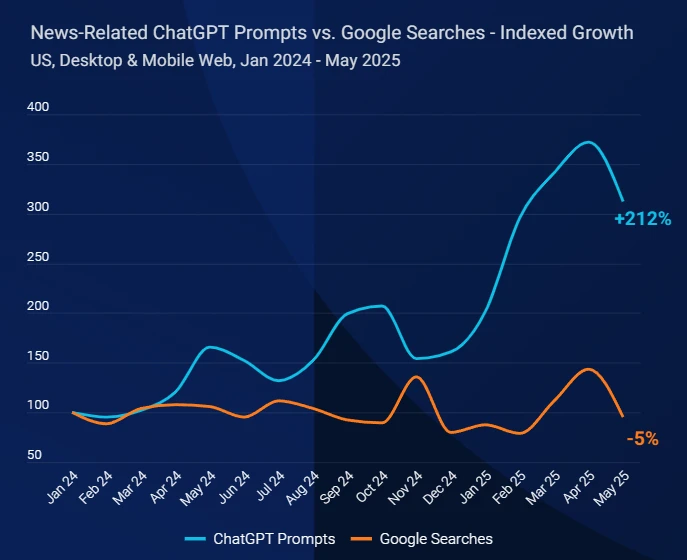
今天,SimilarWeb发布了一个全新的报告,描述了自从ChatGPT这种大模型产品发布之后,新闻出版网站的流量下滑严重,并提供了相关的分析。尽管这是针对新闻网站的报告,但是实际上所有的内容网站或者是内容生产者可能都是有影响的。我们基于这份报告进行解读,为大家提供一个参考。
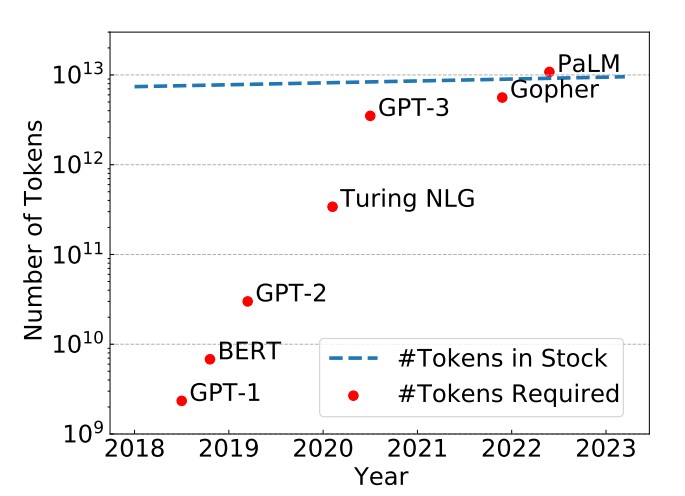
epoch是一个重要的深度学习概念,它指的是模型训练过程中完成的一次全体训练样本的全部训练迭代。然而,在LLM时代,很多模型的epoch只有1次或者几次。这似乎与我们之前理解的模型训练充分有不一致。那么,为什么这些大语言模型的epoch次数都很少。如果我们自己训练大语言模型,那么epoch次数设置为1是否足够,我们是否需要更多的训练?
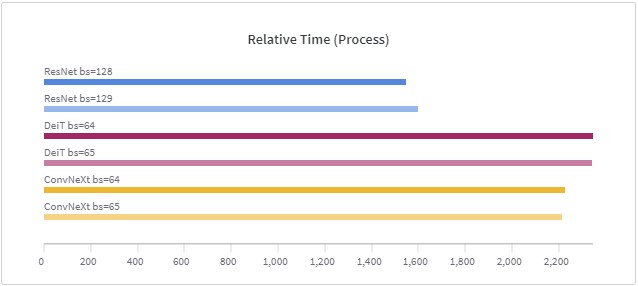
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。
学爬虫先学思想,思想掌握了,对应代码学习技术就so easy了~