
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




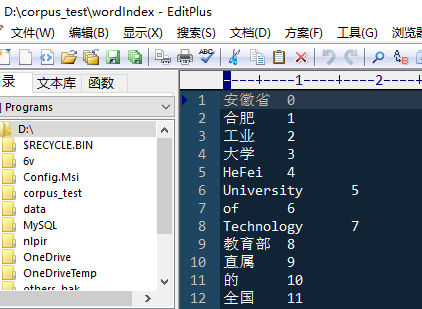
HFUTUtils是一个工具程序集合,方便我们平时处理数据。针对文本处理的内容较多。使用起来非常简单。是本人平时使用Java处理数据时候写的工具,方便数据预处理的。

随着近年来GPT-3、ChatGPT等大模型的兴起,高质量的数据集在模型训练中扮演着越来越重要的角色。但是当前领先的预训练模型使用的数据集细节往往不公开,开源数据的匮乏制约着研究社区的进一步发展。特别是大规模中文数据集十分缺乏,对中文大模型以及业界模型的中文支持都有很大的影响。此次,上海人工智能实验室发布的这个数据集包含了丰富的中文,对于大模型的中文能力提升十分有价值。
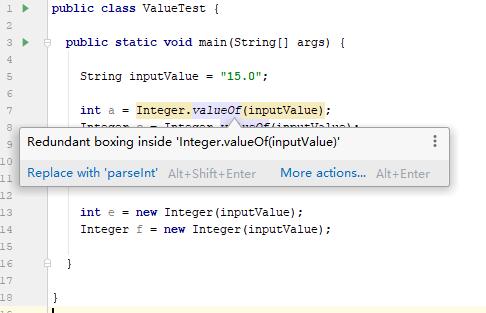
在Java的类型转换中,我们经常会使用valueOf或者parseInt(parseFloat/parseDouble等)来转换。这二者有什么区别呢?这里简要介绍一下。
本文是Steffen Rendle的文章BPR: Bayesian Personalized Ranking from Implicit Feedback的译文
在进行编程操作的时候,我们常常会遇到很多与编程无关的项目管理工作,如下载依赖、编译源码、单元测试、项目部署等操作。一般的,小型项目我们可以手动实现这些操作,然而大型项目这些工作则相对复杂。构建工具是帮助我们实现一系列项目管理、测试和部署操作的工具。本文将对Java构建工具做简单介绍。
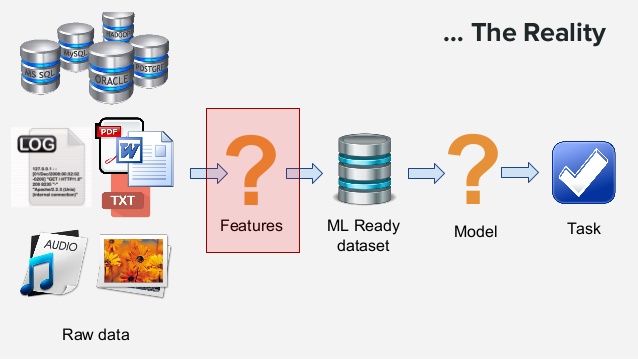
机器学习的特征工程是将原始的输入数据转换成特征,以便于更好的表示潜在的问题,并有助于提高预测模型准确性的过程。找出合适的特征是很困难且耗时的工作,它需要专家知识,而应用机器学习基本也可以理解成特征工程。
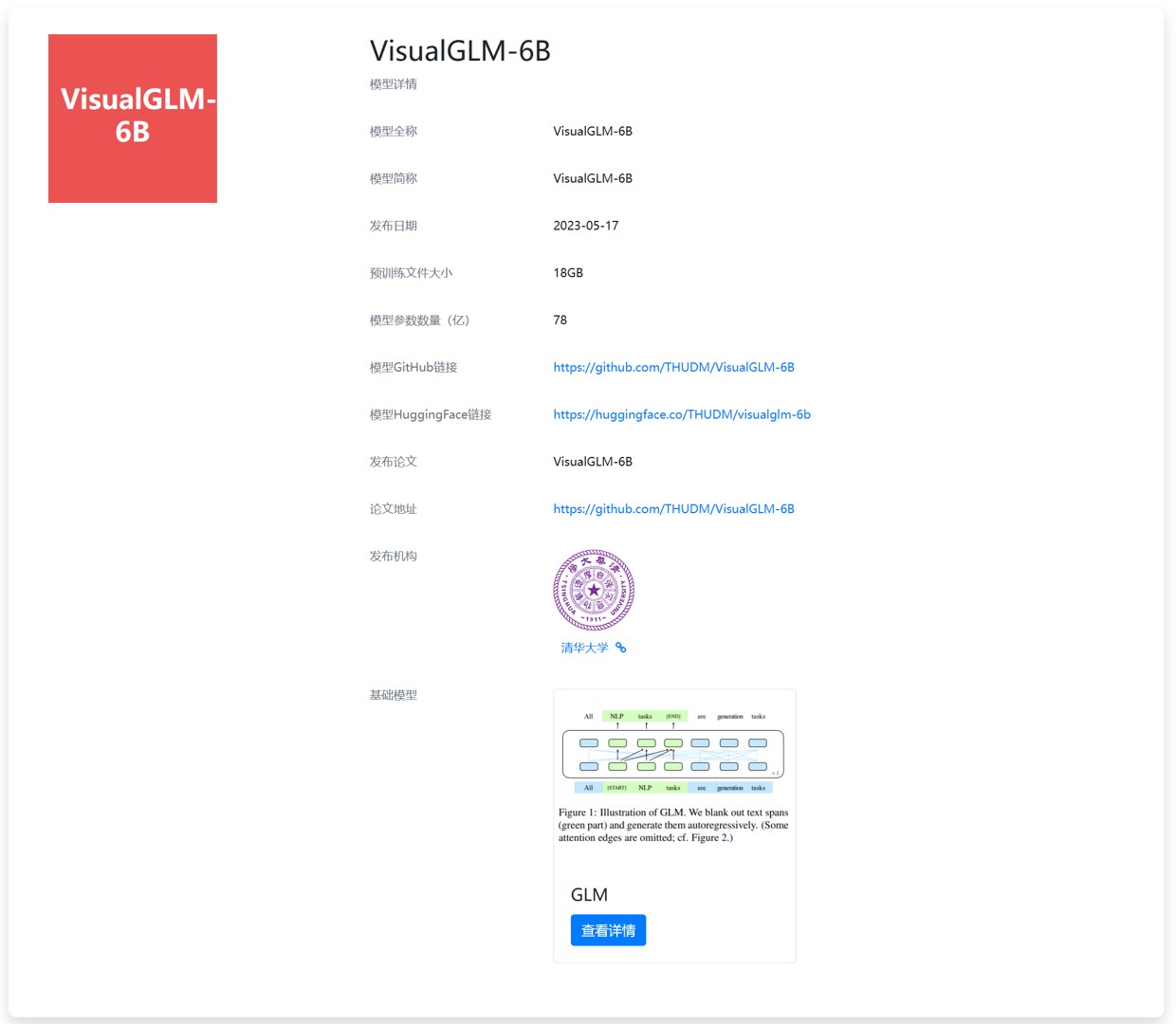
今天,THUDM开源了ChatGLM-6B的多模态升级版模型VisualGLM-6B。这是一个多模态对话语言模型,支持图像、中文和英文。VisualGLM-6B的特别之处在于它能够整合视觉和语言信息。可以用来理解图片,解析图片内容。

机器学习是这几年很热门的学习和工作的方向。但是机器学习相关算法的入门却并不容易。本文参考自MLTUT的博文,列举了2021年适合初学者的十个最佳机器学习网络课程供大家学习参考。
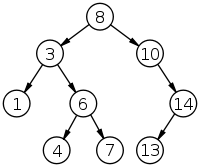
二叉查找树是一种特殊的二叉树结构,它改善了二叉树的查找效率,二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低。与一般的二叉树的主要区别就是它对子节点的键值排序有一定要求。

去年5月份的时候,Python创始人Guido van Rossum在参加Language Summit时候说他希望Python3.11能在性能上获得巨大的提升,可以实现性能翻倍。目前看,似乎已经有了很大的希望!
前几天,北京智源人工智能研究院引入了一个名为WuDaoMM的大规模多模态语料库,总共包含超过6.5亿对图像-文本。具体来说,约有6亿对数据是从图像和标题呈现弱相关的多个网页中收集的,另外5000万对强相关的图像-文本是从一些高质量的图片网站中收集的。

今日推荐
基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
如何解决大模型微调过程中的知识遗忘?香港大学提出有监督微调新范式并开源新模型LLaMA Pro
OpenAI更新新版的Assistant API接口到Assistant API v2版本,现在你可以让GPT-4同时搜索1万个文件
CentOS搭建SVN服务器及使用Eclipse连接SVN服务器
OpenAI发布GPT-5:这是一个包含实时路由的AI系统,而不仅仅是一个模型
通用人工智能(AGI)再往前一步:MetaAI发布新的能听会说的多模态AI大模型ImageBind
阿里开源推理大模型QwQ-32B-Preview:开源领域对OpenAI o1模型奋起直追,能力接近o1-mini,超过GPT-4o!