
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



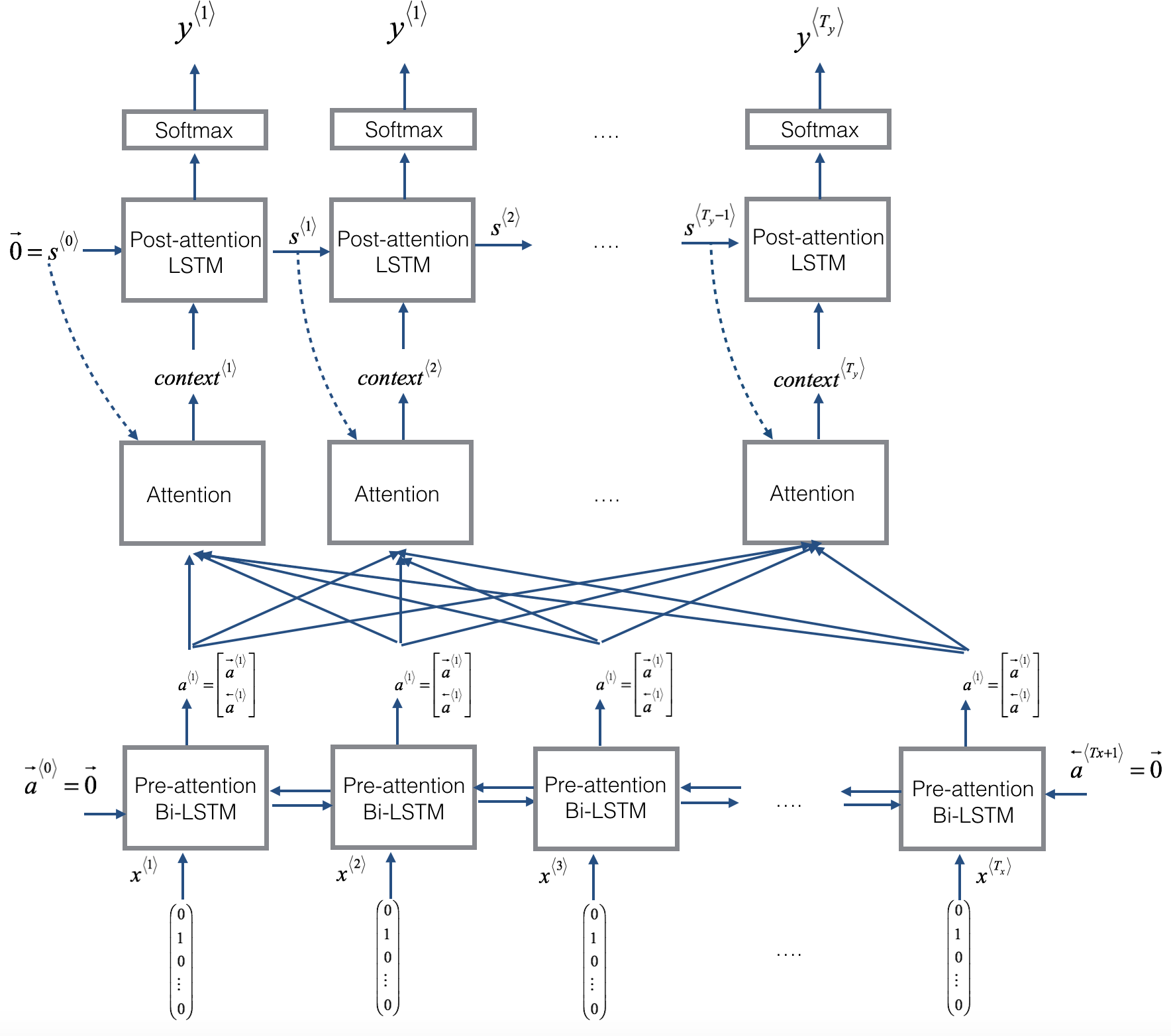
Encoder-Decoder的深度学习架构是目前非常流行的神经网络架构,在许多的任务上都取得了很好的成绩。在之前的博客中,我们也详细介绍了该架构(参见深度学习之Encoder-Decoder架构)。本篇博客将详细讲述Attention机制。

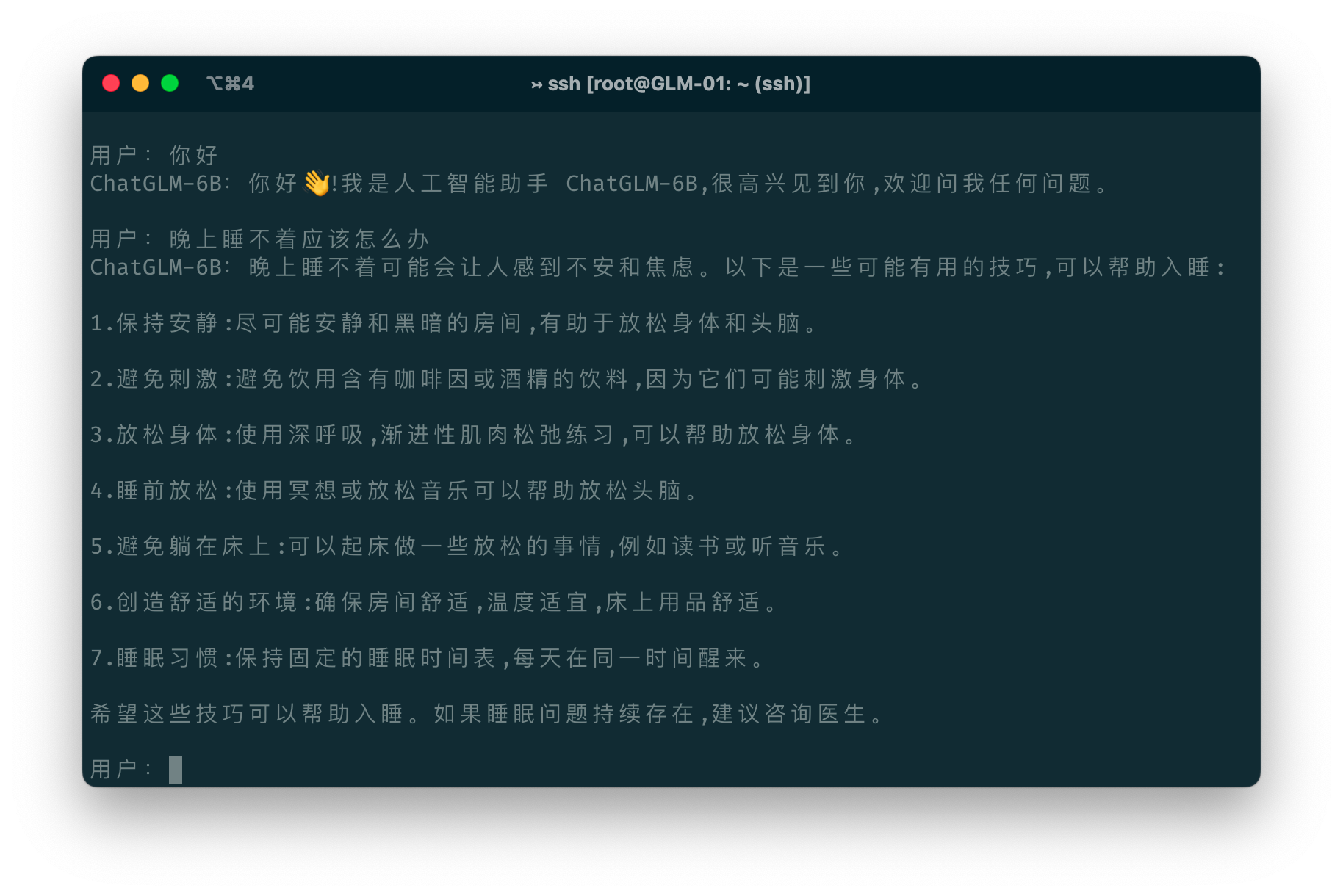
ChatGLM-6B是国产开源大模型领域最强大的的大语言模型。因其优秀的效果和较低的资源占用在国内引起了很多的关注。2023年6月25日,清华大学KEG和数据挖掘小组(THUDM)发布了第二代ChatGLM2-6B。

预测问题一直是机器学习领域最重要的问题之一。很多算法包括回归、决策树等都是用来解决预测的常用算法。预测问题的核心是基于已有的有标签的数据来判断新数据的标签。一般来说,根据预测标签是离散的还是连续的可以分成分类问题和回归问题。注意,本篇博客主要是快速回顾描述各个模型的优缺点,因此不会对模型有很深的介绍。
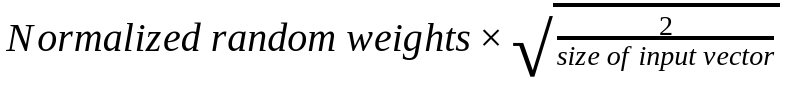
深度学习的初始化非常重要,这篇博客主要描述两种初始化方法:一个是Kaiming初始化,一个是LSUV方法。文中对比了不同初始化的效果,并将每一种初始化得到的激活函数的输出都展示出来以查看每种初始化对层的输出的影响。当然,作者最后也发现如果使用了BatchNorm的话,不同的初始化方法结果差不多。说明使用BN可以使得初始化不那么敏感了。
抽取样本方差的分布可以帮助我们生成很多其他分布的样本,例如生成一元高斯分布的样本就是可以通过方差分布来产生。这篇博客将描述如何抽取样本方差的分布。

仿真抽样是给予贝叶斯方法第二春的重要角色。由于很多时候实际问题很复杂,我们无法精确求出后验密度,使用仿真抽样的方法我们可以获得近似的结果。这篇博客主要介绍了几种仿真抽样的方法。
多项式分布是非常常见的分布,他是二项分布在多维上的推广。例如掷骰子结果中,1-6点出现的次数就是一个多项式分布。多项式分布在如主题建模中非常常见,本文将讲述多项式分布的贝叶斯推导过程。

使用配置文件控制程序的运行是一种非常常见的编程技巧,因此配置文件的解析是所有编程语言中都不可缺少的模块。在Python中,通常使用configparser模块进行配置文件解析。但是configparser解析配置文件有几个常见问题:读取当前项目下某个位置的配置文件、重复配置项的处理以及大小写配置项的读取。本文将描述如何解决这三个问题。