如何对向量大模型(embedding models)进行微调?几行代码实现相关原理
大语言模型是通过收集少量专门数据对模型的部分权重进行更新后得到一个比通用模型更加专业的模型。但是,当前大家讨论较多的都是语言模型的微调,对于嵌入模型(或者向量大模型)的微调讨论较少。Modal团队的工作人员发布了一个博客,详细介绍了向量大模型的微调工作,本文将其翻译之后提供给大家(原文:https://modal.com/blog/fine-tuning-embeddings )。
汇总「BGE」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
大语言模型是通过收集少量专门数据对模型的部分权重进行更新后得到一个比通用模型更加专业的模型。但是,当前大家讨论较多的都是语言模型的微调,对于嵌入模型(或者向量大模型)的微调讨论较少。Modal团队的工作人员发布了一个博客,详细介绍了向量大模型的微调工作,本文将其翻译之后提供给大家(原文:https://modal.com/blog/fine-tuning-embeddings )。
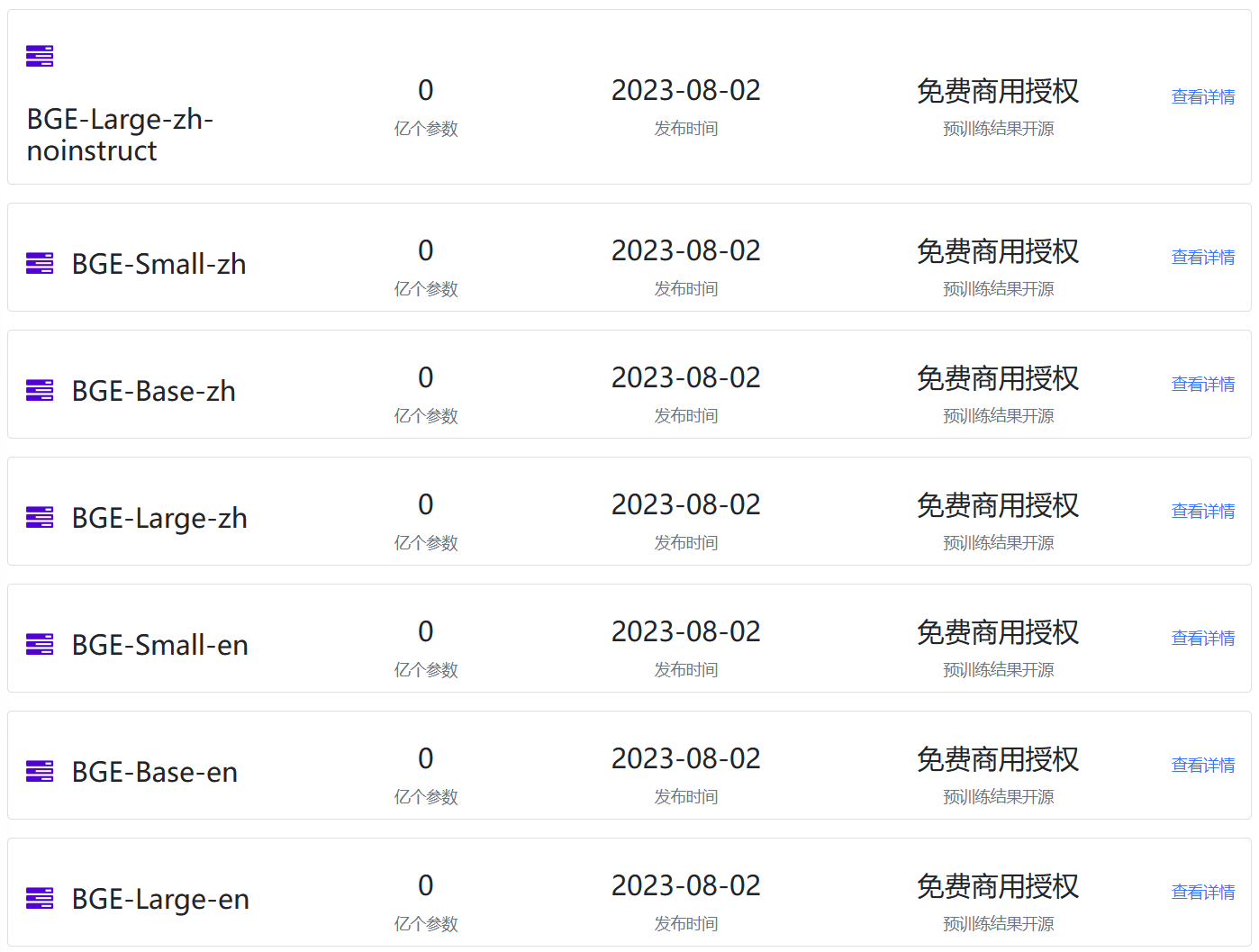
Embedding模型作为大语言模型(Large Language Model,LLM)的一个重要辅助,是很多LLM应用必不可少的部分。但是,现实中开源的Emebdding模型却很少。最近,北京智源人工智能研究院(BAAI)开源了BGE系列Embedding模型,不仅在MTEB排行榜中登顶冠军,还是免费商用授权的大模型,支持中文,应该可以满足相当多人的需要。