
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



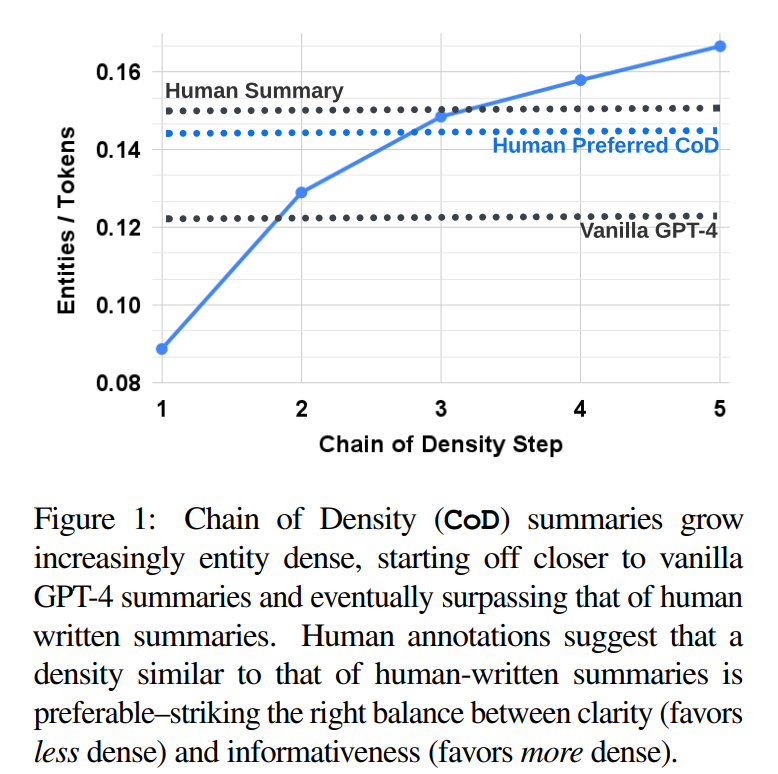
基于文本做文本摘要的时候,摘要所包含的信息密度是一个非常重要的问题。正常情况下我们希望文本摘要既能覆盖更多的重要信息,又要保持简洁和连贯。SalesforceAI与MIT等机构的研究人员联合发布了一个最新的Prompt技巧,称为密度链提示方法(Chain of Density Prompting),可以提取有信息含量的简洁摘要。
今日推荐
微软发布第四代Phi系列大模型,140亿参数的Phi-4 14B模型数学推理方面评测结果超过GPT 4o,复杂推理能力大幅增强
CentOS搭建SVN服务器及使用Eclipse连接SVN服务器
数据科学的Python——keras备忘录发布,含Keras的各种使用样例
正则化和数据增强对模型的影响并不总是好的:The Effects of Regularization and Data Augmentation are Class Dependent
CNN经典算法之Inception V1(GoogLeNet)
截止目前中文领域最大参数量的大模型开源:上海人工智能实验室开源200亿参数的书生·浦语大模型(InternLM 20B系列),性能提升非常明显!
Llama3相比较前两代的模型(Llama1和Llama2)有哪些升级?几张图简单总结Llama3的训练成本、训练时间、模型架构升级等情况