Unifying Language Learning Paradigms——谷歌的一个模型打天下
如今,自然语言处理的预训练模型被广泛运用在各个领域。各大企业和组织都在追求各种大型的预训练模型。但是当你问我们应该使用哪一个预训练模型来解决问题的时候,通常没有统一的答案,一般来说它取决于下游的任务,也就是说需要根据任务类型来选择模型。
而谷歌认为这不是一个正确的方向,因此,本周,谷歌提出了一个新的NLP预训练模型框架——Unifying Language Learning Paradigms(简称UL2)来尝试使用一个模型解决多种任务。
通用模型的吸引力是显而易见的。首先,我们可以专注一个模型来提升模型的水平,不需要关注多个分散的模型。此外,在资源有限的情况下,只有少数模型可以提供服务(例如,在设备上),最好是有一个单一的预训练模型,可以在许多类型的任务上表现良好。
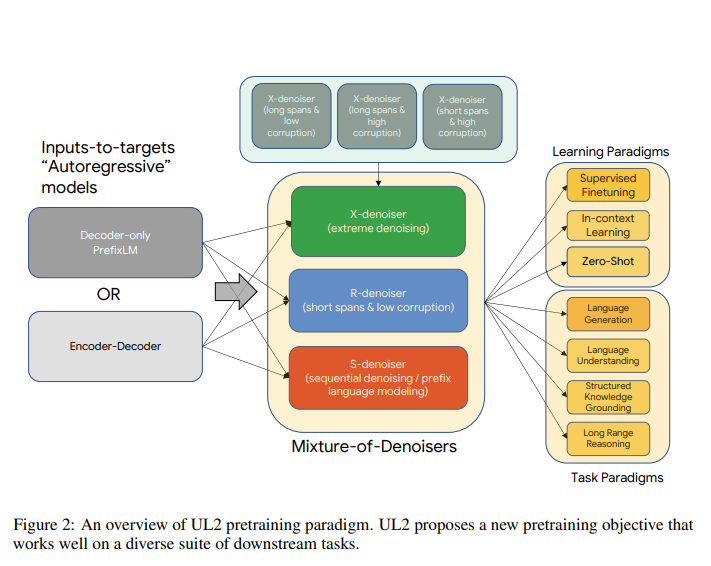
上图就是这个UL2模型的框架。谷歌的研究人员猜想,一个强大的通用模型必须在预训练期间接触到解决不同的问题集。鉴于预训练是通过self-supervision完成的,这种多样性应该被注入到模型的目标中,否则模型可能会缺乏某种能力,比如长连贯的文本生成。受此启发,以及当前的目标函数类别,作者定义了在预训练中使用的三个主要范式:
R-Denoiser--常规去噪是Raffel等人(2019)介绍的标准span corruption,它使用2到5个标记的范围作为跨度长度,这掩盖了大约15%的输入标记。这些跨度很短,对获取知识而不是学习生成流畅的文本有潜在的作用。
S-Denoiser--去噪的一个特定案例,在构建输入到目标的任务时,我们遵守严格的顺序,即前缀语言建模。为此,我们简单地将输入序列划分为两个子序列的标记作为上下文和目标,使目标不依赖于未来的信息。这与标准的span corruption不同,在这种情况下,可能有一个目标标记的位置比上下文标记早。请注意,与前缀-LM设置类似,上下文(前缀)保留了一个双向的接受域。我们注意到,具有非常短的记忆或没有记忆的S-Denoising与标准因果语言建模的精神相似。
X-Denoiser--一个极端的去噪版本,在这个版本中,模型必须恢复输入的很大一部分,给定一个小到中等的部分。这模拟了一种情况,即模型需要从信息相对有限的存储器中生成长的目标。为此,我们选择包括具有积极去噪的例子,其中大约50%的输入序列被屏蔽。这是通过增加跨度长度和/或corruption rate。如果一个预训练任务具有较长的跨度(例如,≥12个标记)或具有较大的损坏率(例如,≥30%),我们认为它是极端的。X-enoising的动机是作为常规span corruption和语言模型之间的插值。
作者通过模式转换来引入范式转换的概念。在预训练期间,给模型提供一个额外的范式标记,即{[R], [S], [X]},帮助模型切换,在更适合给定任务的模式上运行。对于微调和下游的少量学习,为了触发模型学习更好的解决方案,作者还添加了一个与下游任务的设置和要求有关的范式标记。模式切换实际上是将下游行为与我们在上游训练中使用的模式之一结合起来。
简单来说,UL2是一个新的通用预训练模型框架,其主要就是通过降噪器混合( Mixture of Denoisers (MoD))做预训练,再引入模式切换获取高性能的结果。
根据作者的实验,这个200亿的模型再SuperGULE上的性能(zero-shot)超过了1750亿参数的GPT-3,而one-shot方面的性能则是T5-XXL的三倍。最后,作者也发布了基于Flax的T5X模型checkpoint文件。
论文地址:https://arxiv.org/abs/2205.05131 Github地址:https://github.com/google-research/google-research/tree/master/ul2
