大型语言模型的新扩展规律(DeepMind新论文)——Training Compute-Optimal Large Language Models
3月29日,DeepMind发表了一篇论文,"Training Compute-Optimal Large Language Models",表明基本上每个人--OpenAI、DeepMind、微软等--都在用极不理想的计算方式训练大型语言模型。论文认为这些模型对计算的使用一直处于非常不理想的状态。
为此,DeepMind提出了新的优化使用计算的新比例法则,训练了一个新的、700亿个参数的模型,其性能超过了更大的语言模型,包括1750亿个参数的GPT-3和DeepMind自己的2700亿个参数的 "Gopher"。
2020年,OpenAI提出了缩放法则(scaling laws),此后被用来(至少是隐含地)指导大型模型的训练。
这些缩放法则试图回答几个问题。其中一个问题是 "给定一定数量的计算,我应该训练多大的模型才能获得最佳性能?"
答案不是 "尽可能大的模型",因为对于一个固定数量的计算,更大的模型必须在更少的数据上训练。因此,在10本书上训练一个100万参数的模型与在一本书上训练一个1000万参数的模型所需要的浮点运算(FLOPs)是一样多的。
对于像GPT-3这样的大型语言模型,这些替代方案看起来更像是在40%的互联网档案上训练一个200亿个参数的模型,或者在4%的互联网档案上训练一个2000亿个参数的模型,或者沿着同一边界的任何一个无限的点。
这种规模的计算并不便宜--因此,如果你要在一个比你的玩具版模型大100倍的模型上每次训练花费1000万美元,你就需要比直觉更好的原则来指导你如何在 "模型看到的数据量 "和 "模型应该有多大 "之间分配这些计算。
所以,如果你得到10倍的计算量,你要把你的模型做得多大?那100倍的计算量呢?还是1000倍的计算量?
嗯,OpenAI的论文回答了这个问题。如果你得到10倍的计算量,你的模型大小就会增加大约5倍,数据大小增加大约2倍。计算量再增加10倍,模型大小就会增加25倍,数据大小只增加4倍。
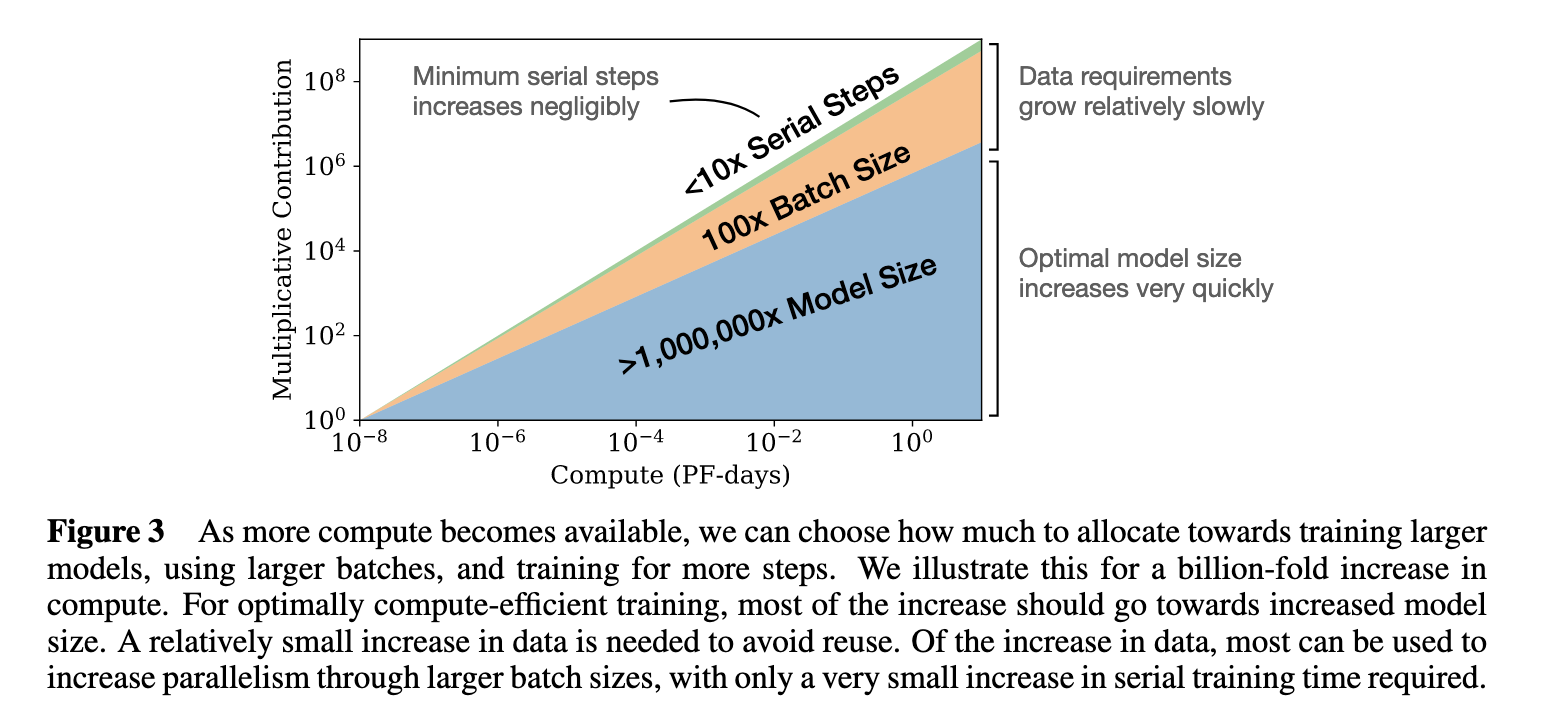
后来的研究人员和机构将这一理念铭记于心,并主要关注如何设计越来越大的模型,而不是在更多的数据上训练相对较小的模型。因此,我们看到许多关于来自ML研究机构和AI加速器创业公司的越来越大的模型的头条新闻。
DeepMind的论文重新讨论了缩放法则的问题。
它使用了三种不同的方法来试图找到正确的缩放规律,这里主要描述第二种方法,因为这可能是最容易理解的。
这个方法很简单。他们选择了9个不同的计算量,范围从大约 $10^{18}$FLOPs到$10^{21}$FLOPs。
对于每个计算量,他们训练许多不同大小的模型。因为每个级别的计算量是恒定的,较小的模型训练时间较长,较大的模型训练时间较短。
论文中的以下图表说明了这一点。每条线连接着使用相同计算量训练的模型(不同大小)。纵轴是损失,越低越好。
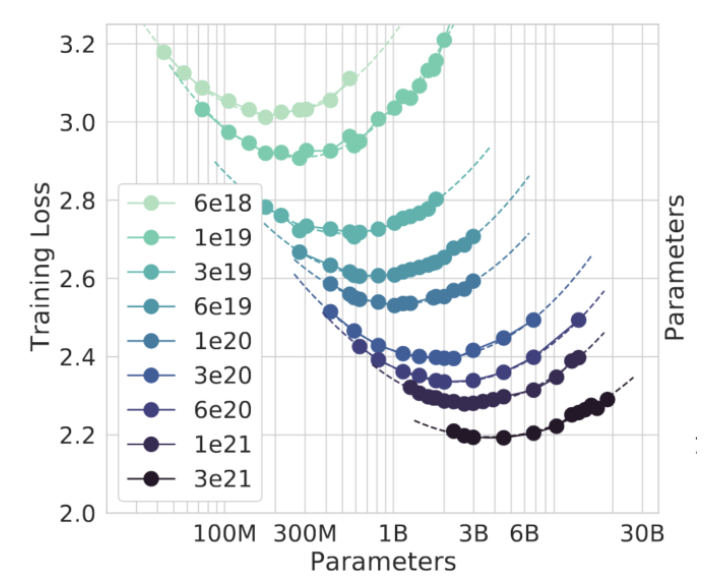
这些曲线中的每一条都有明确的解释。在每条曲线的最小值左边,模型太小了--在更少的数据上训练一个更大的模型将是一种改进。在每条曲线上最小值的右边,模型太大--在更多的数据上训练出的较小的模型将是一种改进。最好的模型是在最小值处。
如果你把每条曲线上的最小值连接起来,并把线向外延伸,你会得到一个新的规律 具体来说,看起来计算量每增加一个,你就应该增加数据大小和模型大小大约相同的数量。
如果你的计算量增加了10倍,你应该让你的模型大3.1倍,你训练的数据大3.1倍;如果你的计算量增加了100倍,你应该让你的模型大10倍,你的数据大10倍。
现在,上述所有的实验运行图都是在相对较小的模型上,用非疯狂的计算量进行训练。所以你可以说,这个规则对更大的数字不起作用。
但为了验证这一规律的正确性,DeepMind使用与280亿个参数的Gopher相同的计算方法,训练了一个700亿个参数的模型("Chinchilla")。也就是说,他们用1.4万亿个tokens训练了较小的Chinchilla,而较大的Gopher只训练了3000亿个token。
而且,正如新的缩放法则所预测的那样,Chinchilla在几乎所有方面都比Gopher好很多。它在标准的每字较少的复杂度(less-perplexity-per-word)方面更胜一筹,在更有趣的下游任务有用度方面也是如此。
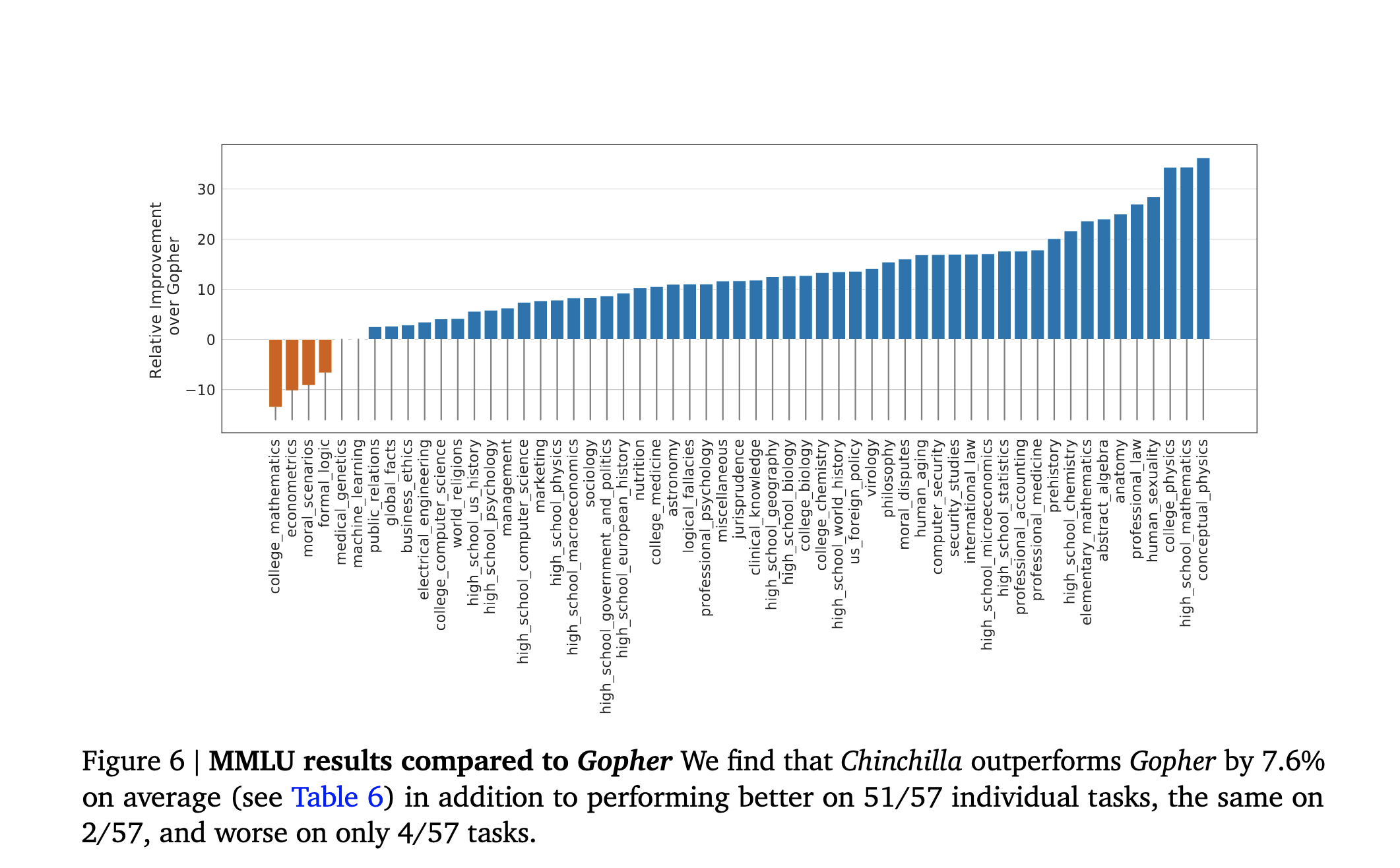
鉴于Chinchilla的证据,OpenAI似乎很确定地把缩放法则弄错了。因此,一个自然的问题是:"发生了什么事让他们弄错了?"
深度神经网络的学习率决定了一个网络的参数在每一个训练数据中的更新程度。大规模训练的学习率通常会根据时间表下降,因此,训练结束时的数据对神经网络参数的调整要比训练开始时的数据少。你可以把这看作是反映了不 "忘记 "在训练运行早期所学到的东西的需要。
看起来OpenAI对他们所有的运行都使用了单一的annealing schedule,即使是那些不同长度的运行。这使得非理想annealing schedule上的网络的明显的最佳可能的性能向下移动。而这导致错误的缩放法则。
感兴趣的同学可以去阅读原文。 论文解读:https://www.lesswrong.com/posts/midXmMb2Xg37F2Kgn/new-scaling-laws-for-large-language-models arXiv地址:https://arxiv.org/abs/2203.15556
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
