
如何构建下一代机器翻译系统——Building Machine Translation Systems for the Next Thousand Languages
本周,谷歌的研究人员在arXiv上提交了一个非常有意思的论文,其主要目的就是分享了他们建立能够翻译一千多种语言的机器翻译系统的经验和努力。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
本周,谷歌的研究人员在arXiv上提交了一个非常有意思的论文,其主要目的就是分享了他们建立能够翻译一千多种语言的机器翻译系统的经验和努力。
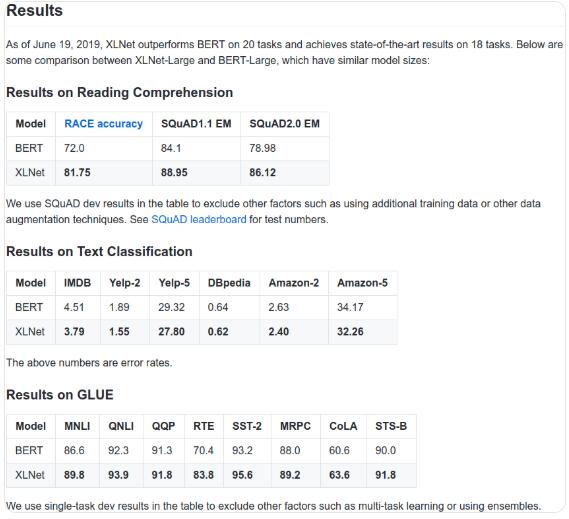
前几天刚刚发布的XLNet彻底火了,原因是它在20多项任务中超越了BERT。这是一个非常让人惊讶的结果。之前我们也说过,在斯坦福问答系统中,XLNet也取得了目前单模型第一的成绩(总排名第四,前三个模型都是集成模型)。
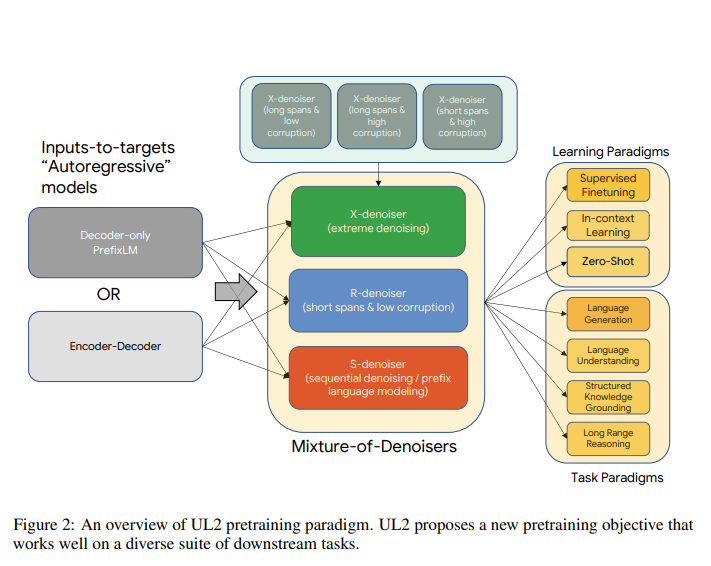
如今,自然语言处理的预训练模型被广泛运用在各个领域。各大企业和组织都在追求各种大型的预训练模型。但是当你问我们应该使用哪一个预训练模型来解决问题的时候,通常没有统一的答案,一般来说它取决于下游的任务,也就是说需要根据任务类型来选择模型。 而谷歌认为这不是一个正确的方向,因此,本周,谷歌提出了一个新的NLP预训练模型框架——Unifying Language Learning Paradigms(简称UL2)来尝试使用一个模型解决多种任务。
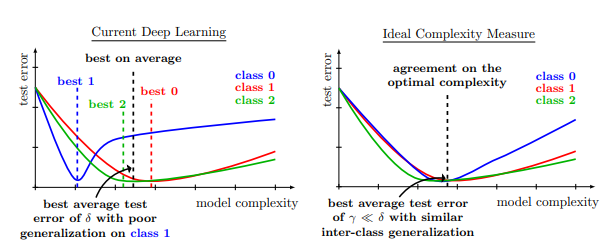
正则化是一种基本技术,通过限制模型的复杂性来防止过度拟合并提高泛化性能。目前的深度网络严重依赖正则化器,如数据增强(DA)或权重衰减,并采用结构风险最小化,即交叉验证,以选择最佳的正则化超参数。然而,正则化和数据增强对模型的影响也不一定总是好的。来自Meta AI研究人员最新的论文发现,正则化是否有效与类别高度相关。
今晚已经是本周的最后一天了,最近的一些深度学习算法方面的进展做个总结吧,感觉都是挺不错的,供大家参考。
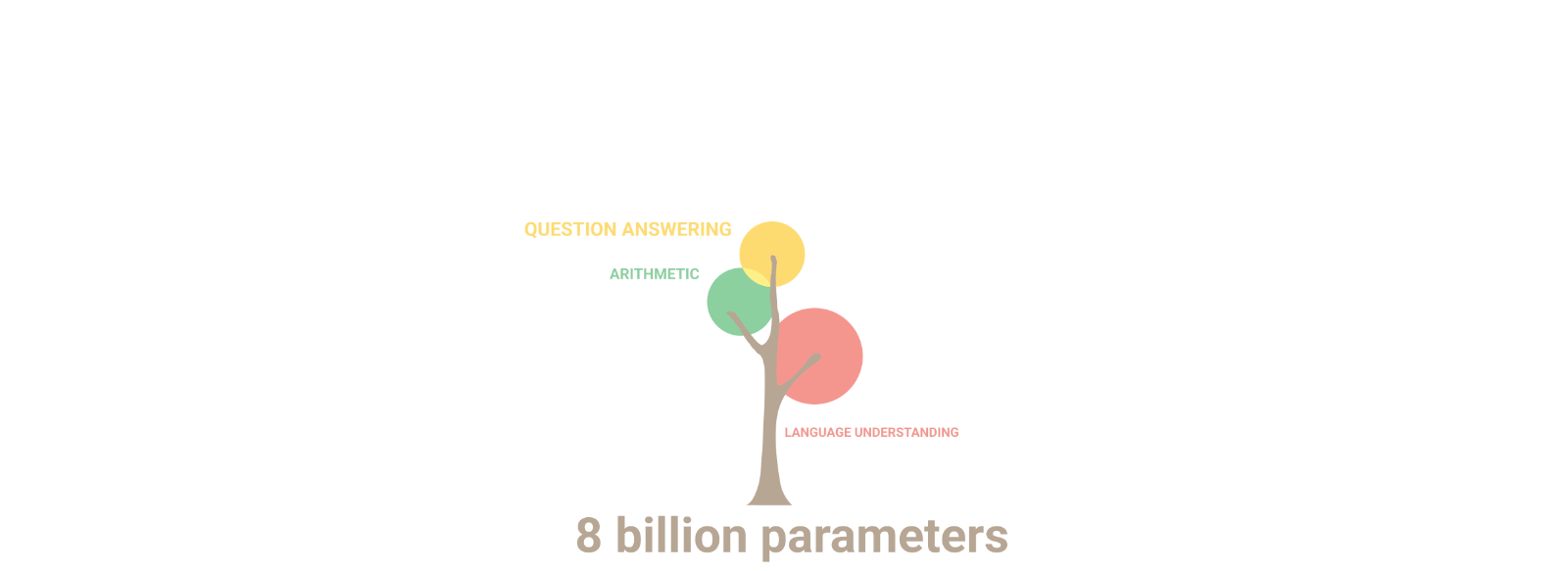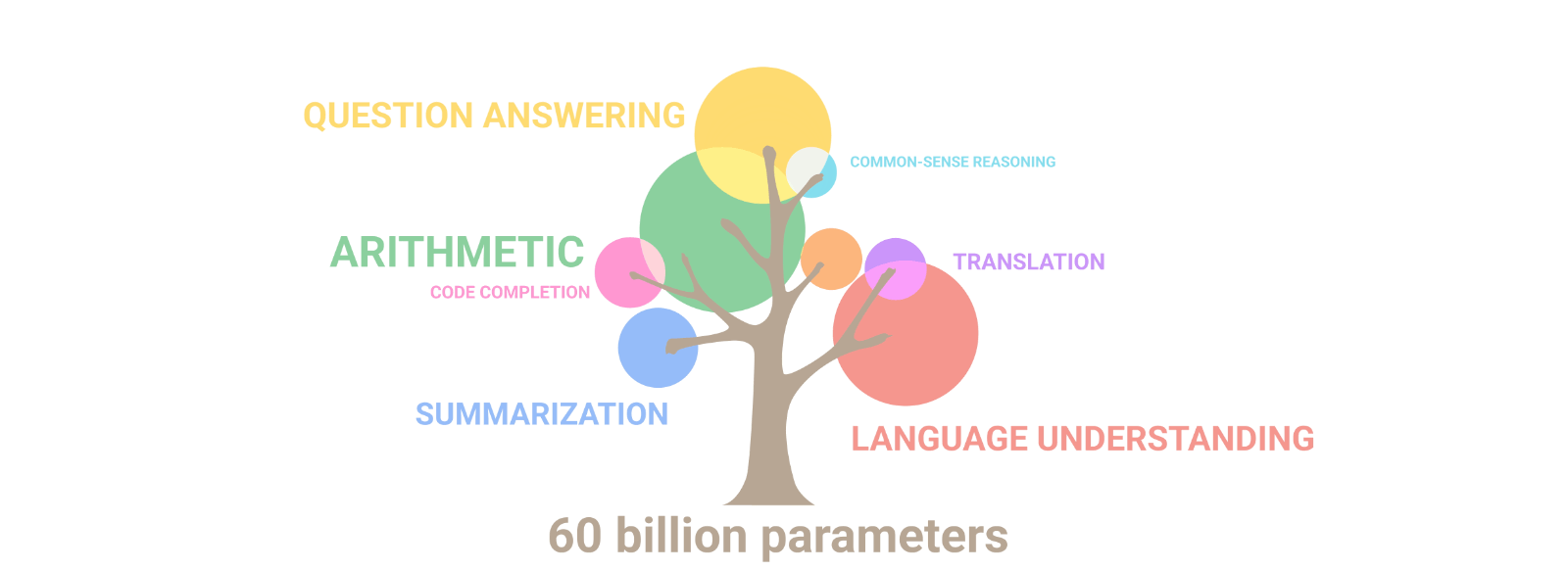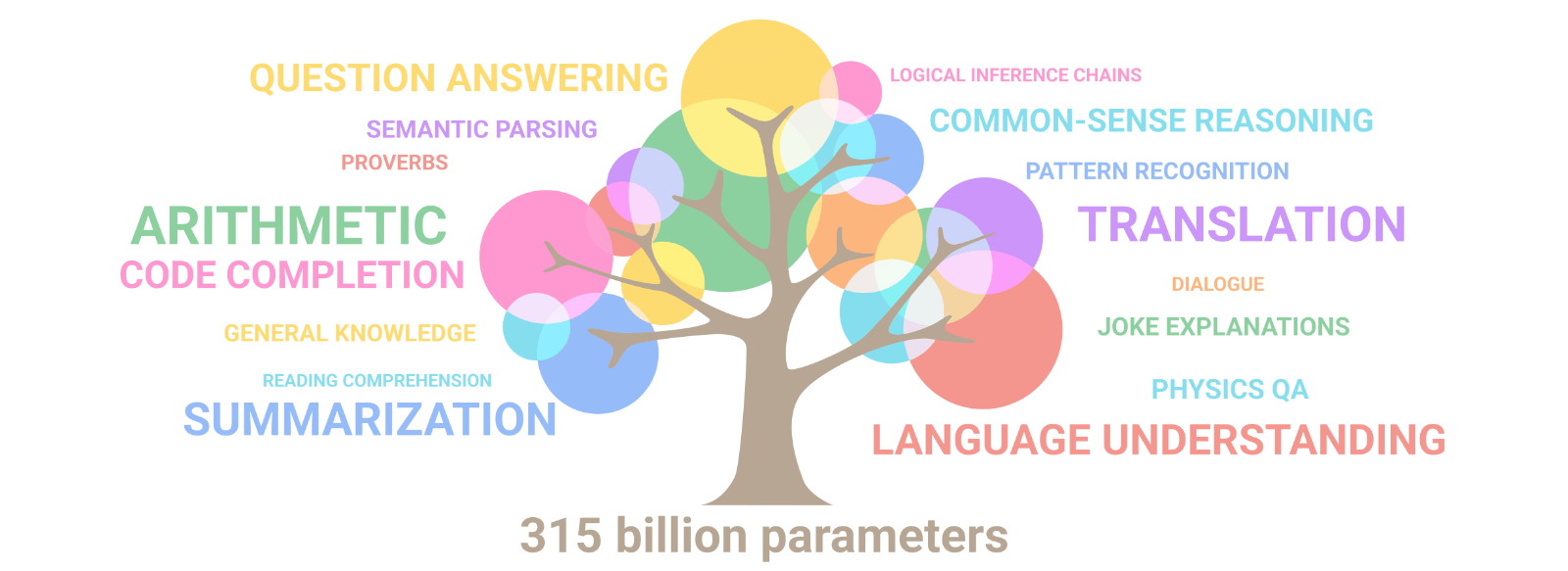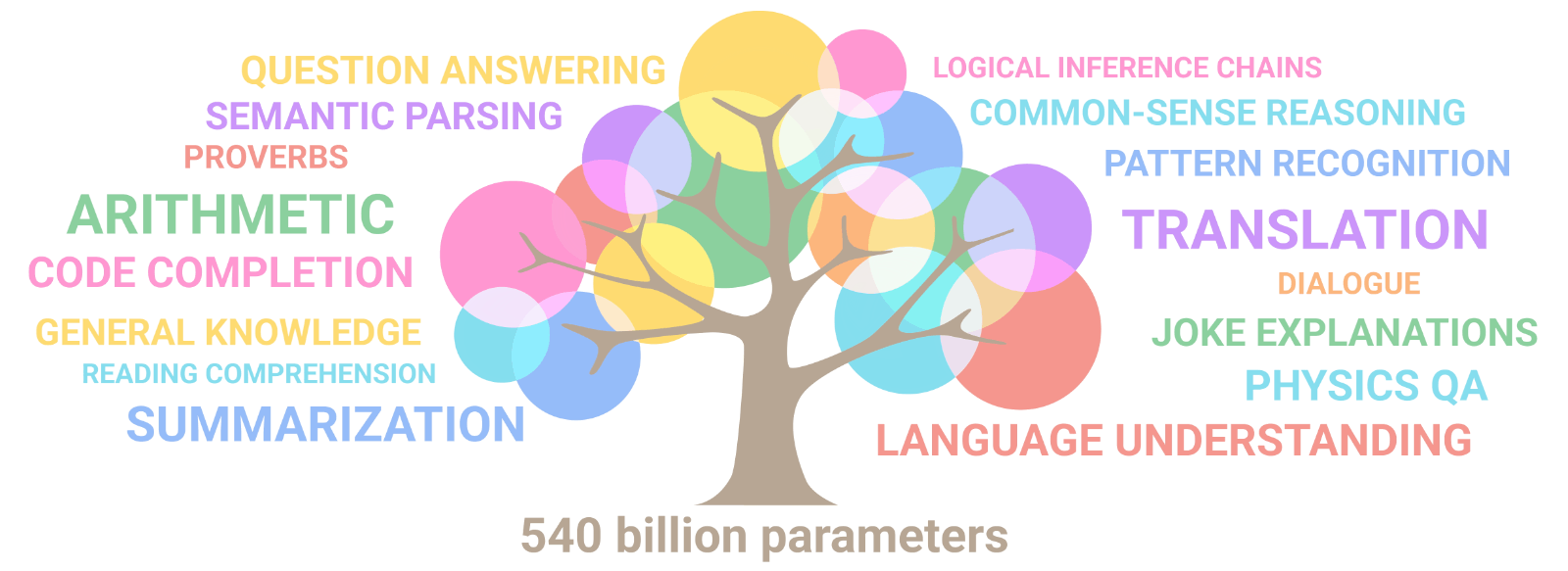
今天,Google介绍了一个新的语言模型,一个Pathways语言模型:PaLM,这是一个用Pathways系统训练的5400亿个参数、仅有dense decoder的Transformer模型,在数百个语言理解和生成任务上对PaLM进行了评估,发现它在大多数任务中实现了最先进的性能,在许多情况下都有显著的优势。
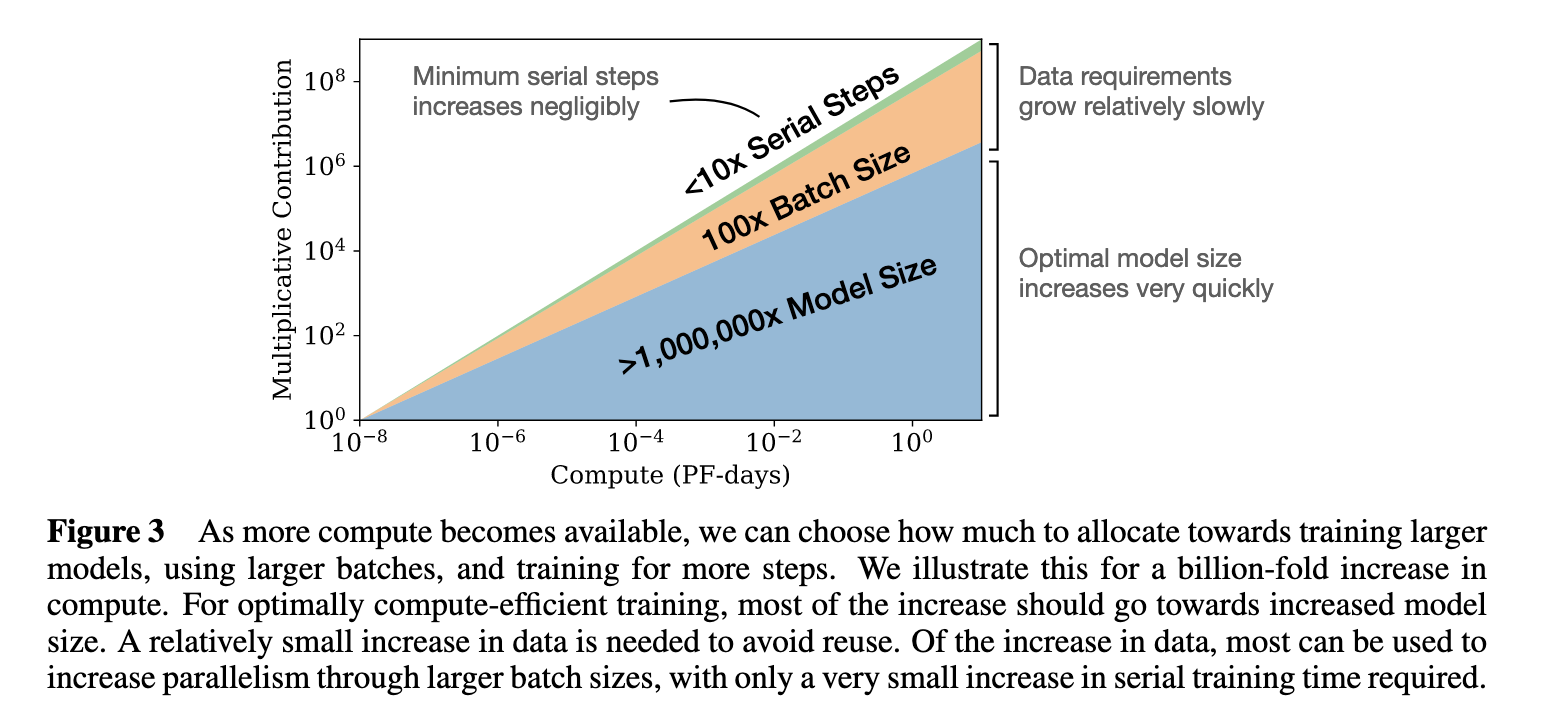
3月29日,DeepMind发表了一篇论文,"Training Compute-Optimal Large Language Models",表明基本上每个人--OpenAI、DeepMind、微软等--都在用极不理想的计算方式训练大型语言模型。论文认为这些模型对计算的使用一直处于非常不理想的状态。并提出了新的模型缩放规律。
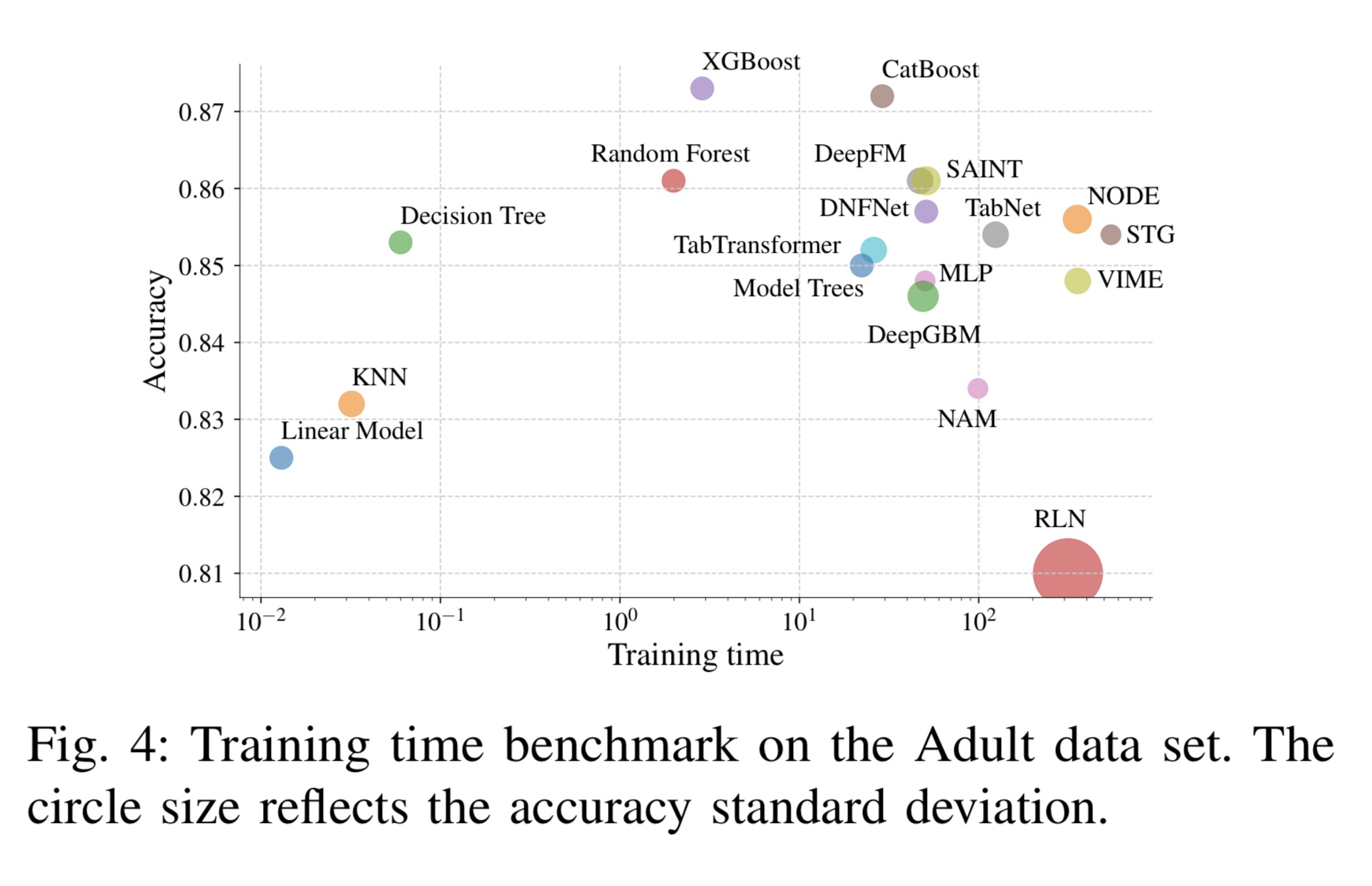
异质表格数据是最常用的数据形式,对于众多关键和计算要求高的应用来说是必不可少的。在同质数据集上,深度神经网络已多次显示出优异的性能,因此被广泛采用。然而,它们在表格数据建模(推理或生成)方面的应用仍然具有高度挑战性。

重磅新论文!北京人工智能研究员与清华大学、腾讯、华为、字节等公司一起发表了一篇关于大规模预训练模型路线图的论文。

仅仅使用来自人类数据集的机器学习,在短短9个小时内,日本研究人员让一个机器人学会了如何拿起和剥开香蕉。