微软开源DeepSpeed Chat——一个端到端的RLHF的pipeline,可以用来训练类ChatGPT模型。
1,162 views
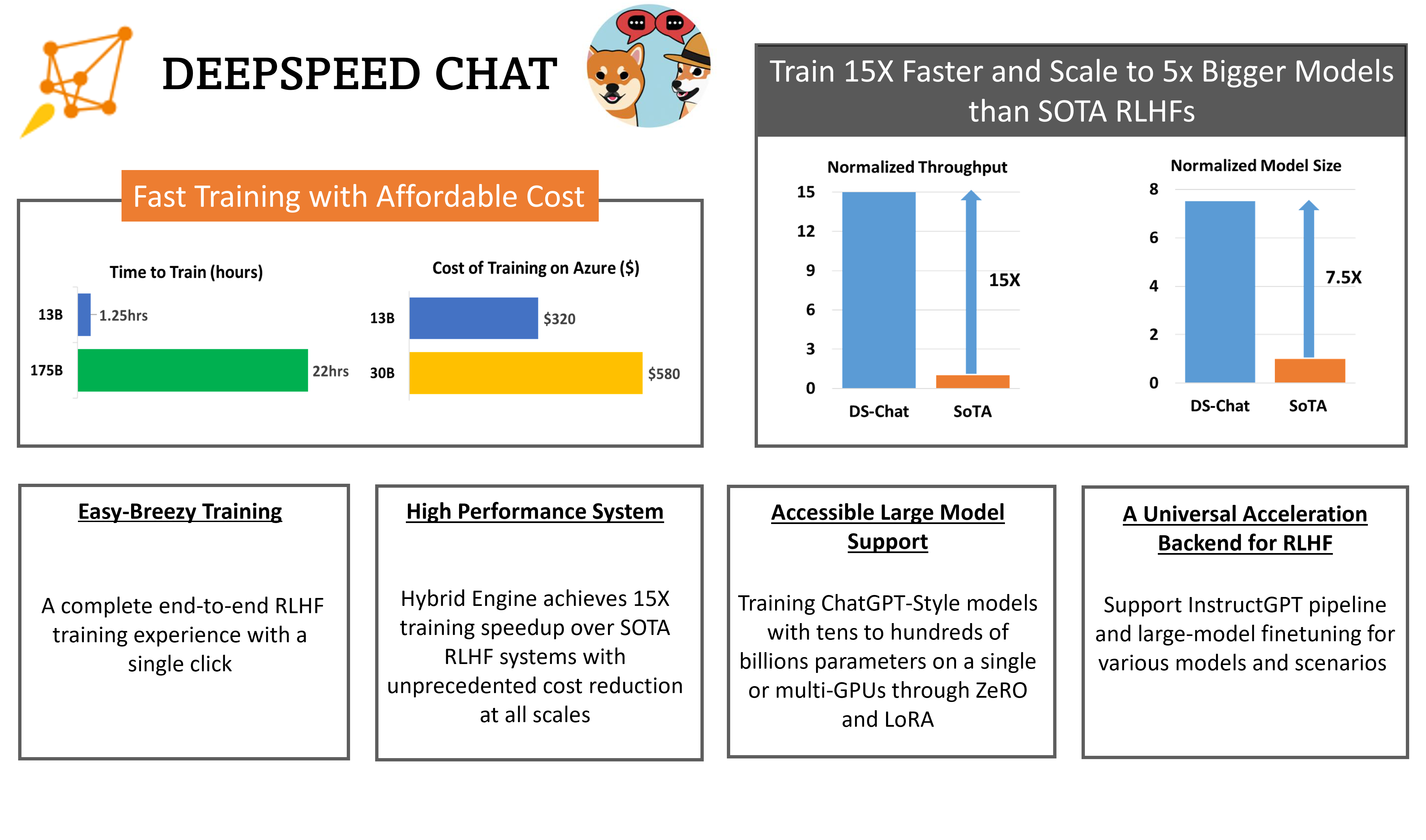
RLHF全称Reinforcement Learning from Human Feedback,是随着ChatGPT火爆之后而被大家所关注的技术。昨天,微软开源了业界第一个RLHF的pipeline框架,可以用来训练类似ChatGPT的模型。
RLHF是什么?为什么RLHF很重要
强化学习(RL)是一种机器学习类型,允许代理通过试错学习如何在环境中行为。代理被赋予一个目标和奖励函数,并且必须学习采取最大化其预期奖励的行动。
RL在学习复杂任务方面非常有效,但也可能非常具有挑战性。其中一个挑战是很难设计一个准确反映代理目标的奖励函数。如果奖励函数不准确,代理可能会学会以不理想的方式行为。
从人类反馈中进行强化学习(RLHF)是一种可以解决这个问题的技术。在RLHF中,代理被赋予一个初始非常简单的奖励函数。然后代理与环境进行交互,并从人类接收反馈。人类反馈被用于更新奖励函数,这进而有助于代理学会更理想的行为方式。
已经证明,RLHF可以有效地学习各种任务,包括玩游戏、控制机器人和编写文本。这是一种有前途的技术,可以用于训练代理在复杂和具有挑战性的环境中的行为方式。
