大语言模型训练之前,数据集的处理步骤包含哪些?以LLaMA模型的数据处理pipeline(CCNet)为例
大语言模型的训练是一个十分复杂的技术,不仅涉及到模型的开发与部署,还涉及到数据的获取。与常规的算法模型不同的是,大语言模型通常需要大量的数据处理步骤。本文是根据英国一位自动工程师总结的大语言模型训练之前的数据处理步骤和决策过程。
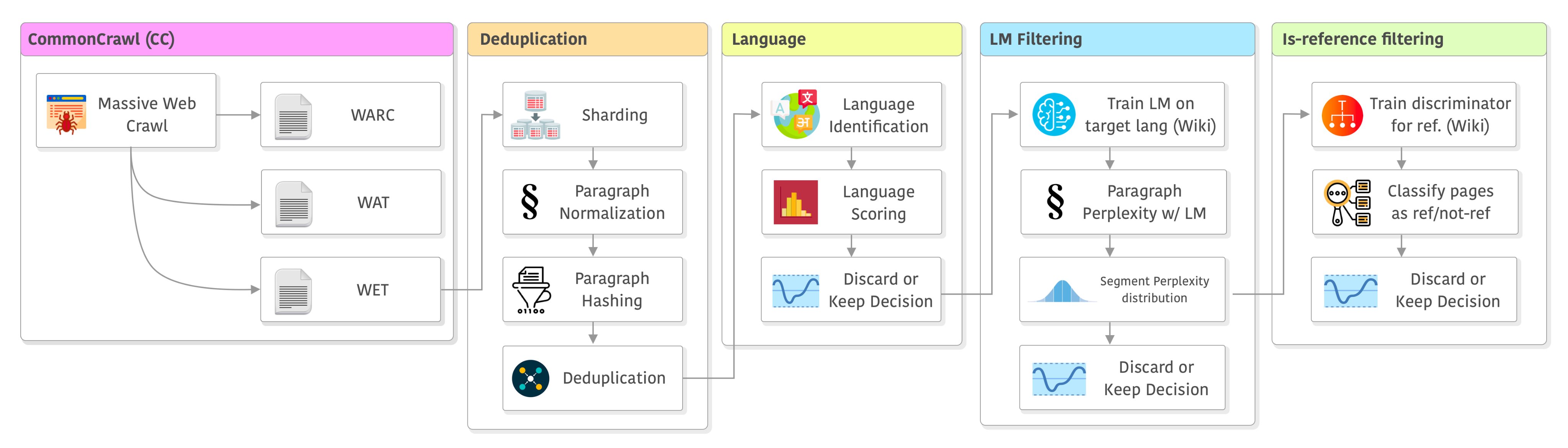
该总结主要来源MetaAI发布的LLaMA模型的论文。同时,也会增加我自己做的一些说明。LLaMA是MetaAI开源的大语言模型,也是近期发布的很多模型的基础模型。CCNet是LLaMA模型使用的数据处理pipeline。关于LLaMA模型在DataLearner官方的模型信息卡参考:https://www.datalearner.com/ai-models/pretrained-models/LLaMA
一、数据爬取和保存
大语言模型的训练需要大量的数据,为了获取更多的数据训练,当前大语言模型的训练都以无标注的数据为主。以LLaMA为例,它们获取的数据如下:
大部分数据都是从互联网上爬取的数据。但是需要注意的是,这些数据并不是纯文本存储的,通常使用WARC、WAT和WET格式的数据存储。
WARC,WAT和WET是三种与Web数据相关的文件格式:
- WARC(Web ARChive):它是一种用于存储和传输Web资源(例如HTML页面,图像和视频文件等)的文件格式。 WARC文件通常包含HTTP响应和元数据,用于记录Web爬虫收集的信息。
- WAT(Web Archive Transformation):它是一种元数据文件格式,用于描述WARC文件中记录的Web内容。 WAT文件通常包含URL,域名和其他有关记录的元数据信息。
- WET(Web Extraction Toolkit):它是一种将HTML页面转换为文本格式的文件格式。 WET文件通常包含从HTML页面中提取的文本内容,但不包括图像和其他资源。
这些文件格式通常用于Web挖掘和数据分析,以及与Web相关的研究和开发项目。LLaMA的模型使用的是WET格式的数据。
二、数据去重(Deduplication)
在前面获取的数据中,以Common Crawl为例,每个CC快照的文本大小约300T,而一个WET格式的快照大小约30T。MetaAI人员用CCNet将这些快照进行分片(sharding),将原来的数据分成5G一个分片。然后对每个数据做预处理:如小写化所有数据、数字变成占位符等,然后计算每个段落的hash,再去重。
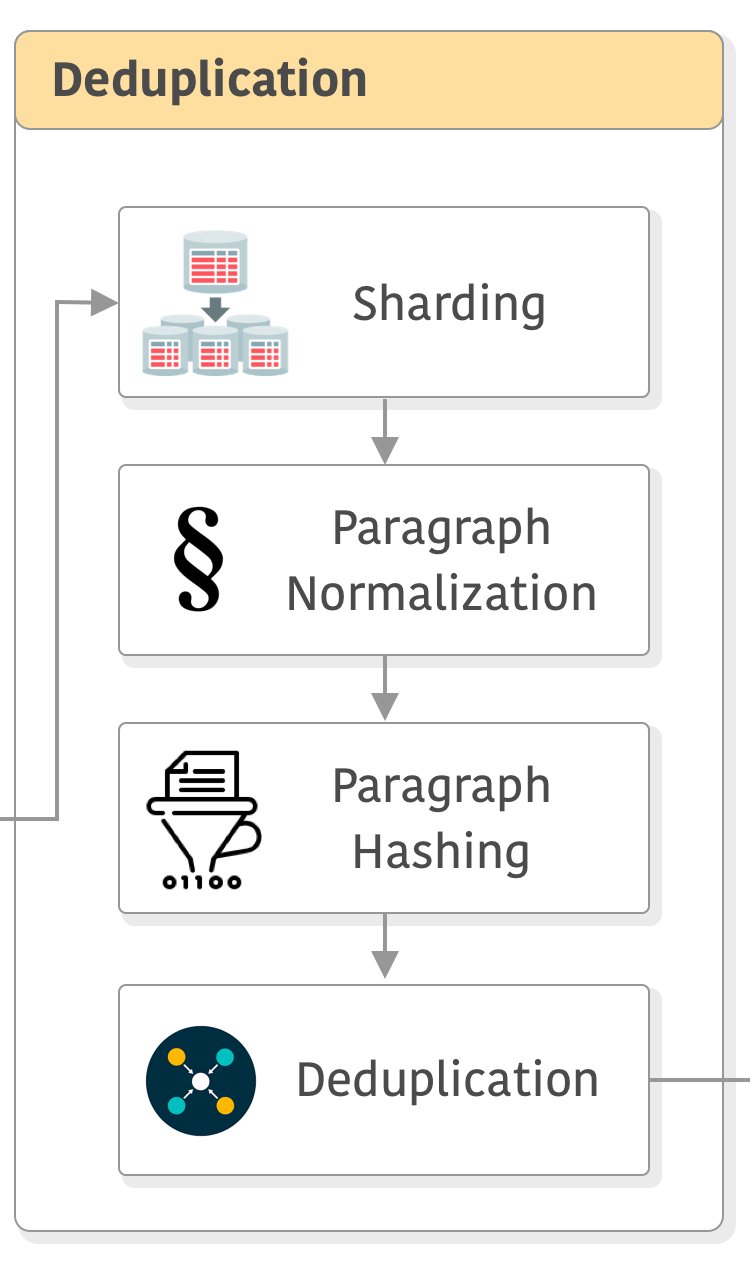
可以看到,这样操作之后,可以有效地并行处理数据,提高处理速度,也能降低数据量。
三、文本语言识别与过滤
大语言模型训练的一个很重要的方面是关于多语言的支持,很多模型因为数据质量和效果,都只保留一种语言的能力,如英语。而即使支持多语言的模型,也并不是所有的数据都同样处理。
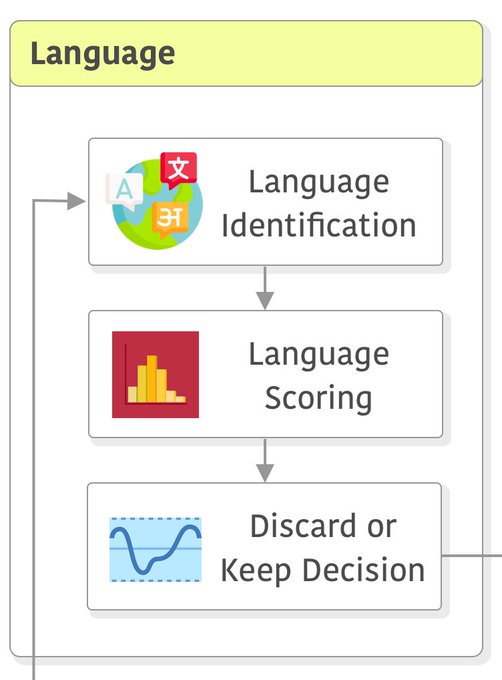
在这个步骤中,MetaAI的主要处理方式是识别语言,然后对不同语言的数据计算分数,最后根据分数确定是否保留某些语言。在pipeline中执行此操作的顺序可能会影响语言识别的质量。CCNet使用使用n-gram特征的fastText分类器。
四、质量过滤
大语言模型的训练成本很高,因此,在训练之前对数据的选择也十分重要。在前面的步骤中,CCNet已经对不同语言的数据质量做了初步的识别和过滤。但是,并不够。因此,在这里,研究人员继续使用一部分数据来训练一个小的简单的模型,测试数据质量。
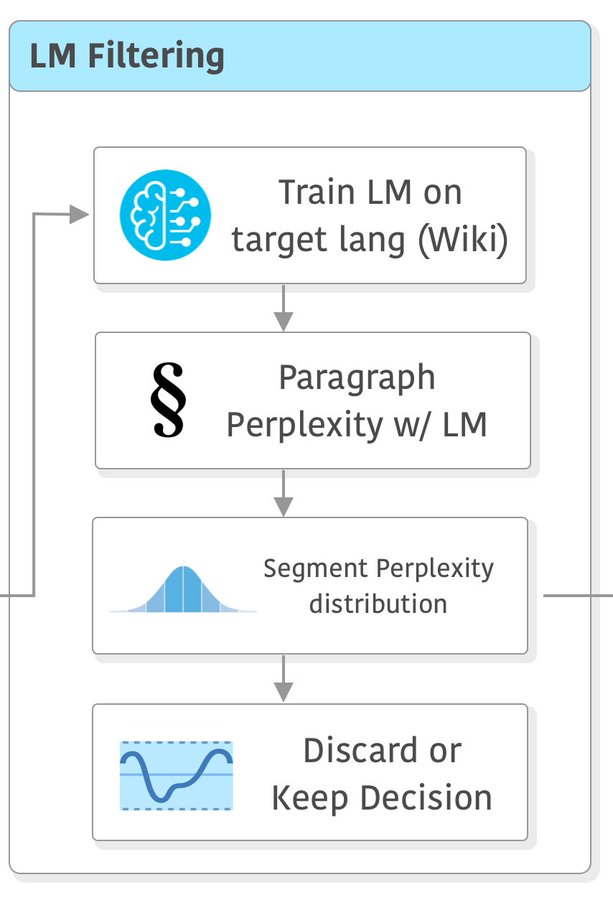
在CCNet中,他们建议使用维基百科在目标语言上训练一个简单的语言模型,然后计算每段的困惑度(perplexity),并使用困惑度分布的来对它们进行分段。
五、进一步过滤
最后一步没有包括在CCNet中,但在LLaMA论文中提到了,就是训练一个线性模型来将维基百科中用作参考的页面与随机抽样的页面进行分类,并且丢弃未被分类为参考的页面。
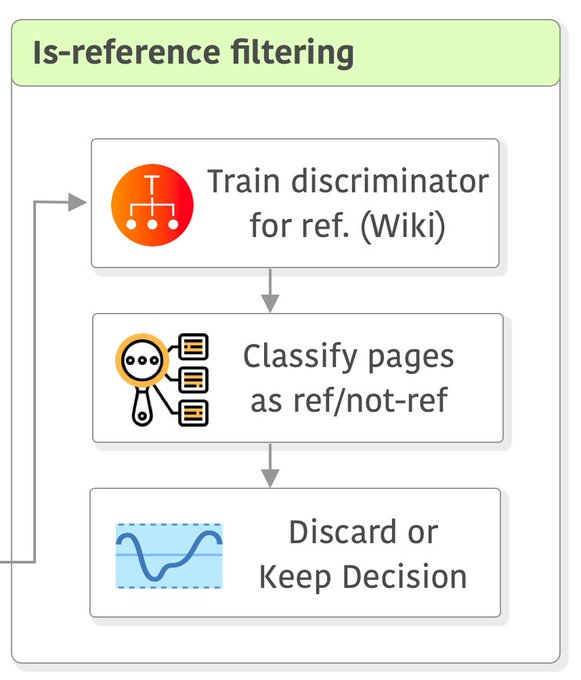
我理解这个步骤主要的目的是为了确定页面的质量。如果这个页面无法被认为是可以作为维基百科引用的,说明页面本身质量可能比较差,所以可以进一步丢弃,提高数据的质量,降低训练成本。
六、总结
以上就是Christian S. Perone从MetaAI论文中总结的大语言模型训练过程中数据的处理步骤。可以看到,大部分的工作都是为了提高数据质量进行的。因为LLM的训练依赖的是大量的无标注数据,如果数据输入问题比较多,也会影响模型的质量。因此,这些步骤应该可以给大家其实,我们本身也是可以根据这些内容思考,做更多的事情~~~
原文发表自Christian S. Perone的推特:https://twitter.com/tarantulae/status/1650170087708454913
