智谱AI发布第二代CodeGeeX编程大模型:CodeGeeX2-6B,最低6GB显存可运行,基于ChatGLM2-6B微调
编程大模型是大语言模型的一个非常重要的应用。刚刚,清华大学系创业企业智谱AI开源了最新的一个编程大模型,CodeGeeX2-6B。这是基于ChatGLM2-6B微调的针对编程领域的大模型。
不过,需要注意的是,官方说CodeGeeX2-6B对学术研究完全开放,商用需要申请,可能是收费商用授权!
昨天,北京智源人工智能研究院才开源AquilaCode-7B模型,今天智谱AI就开源了CodeGeeX2-6B,不得不说国产大模型进展神速啊:
至此,编程大模型再度扩张版图~
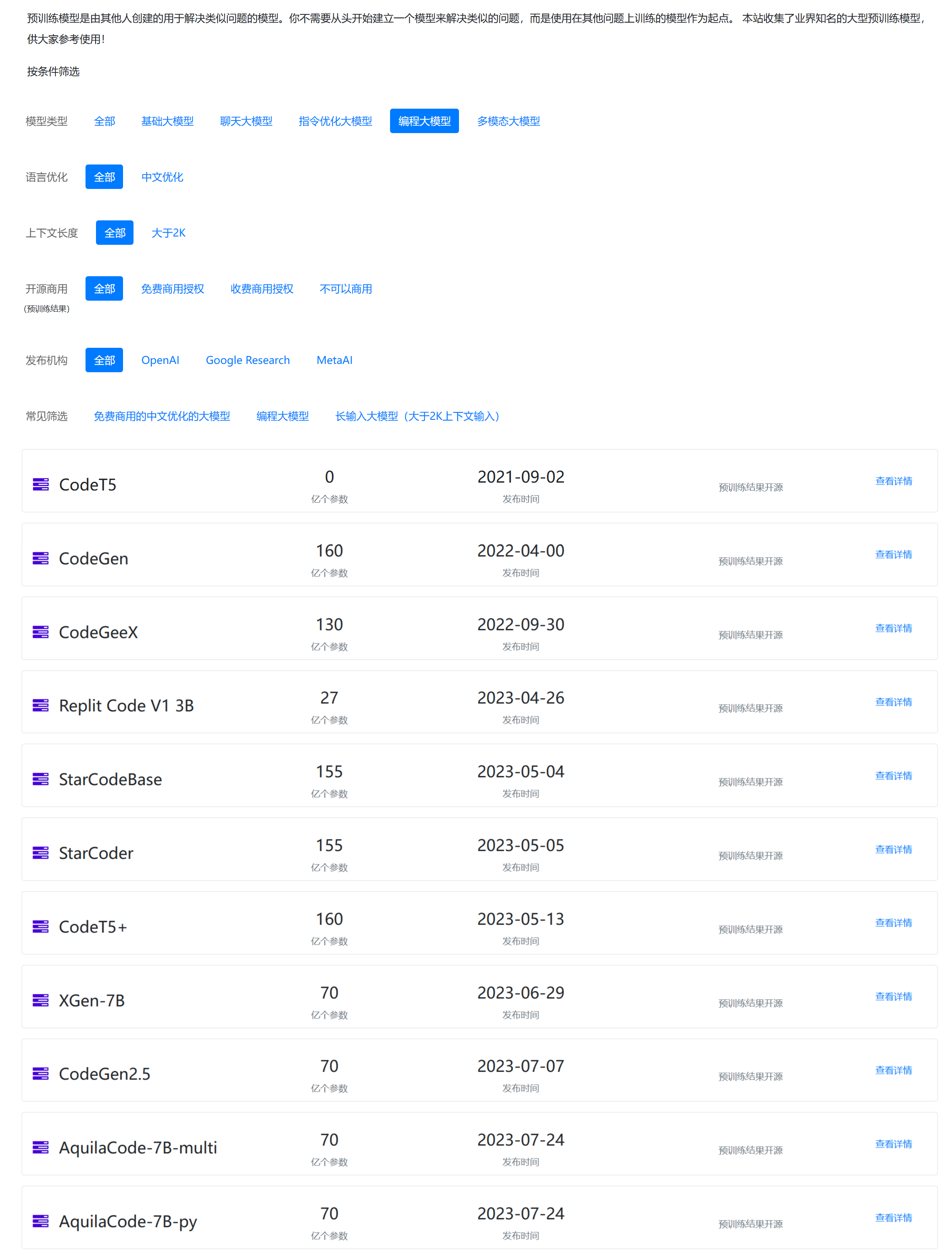
上面的筛选来源DataLearner大模型列表:https://www.datalearner.com/ai-models/pretrained-models?&aiArea=1002&language=-1&contextLength=-1&openSource=-1&publisher=-1
CodeGeeX2简介
CodeGeeX是2022年9月份智谱AI发布的一个编程大模型,是基于第一代GLM模型微调得到(CodeGeeX模型信息:https://www.datalearner.com/ai-models/pretrained-models/CodeGeeX )。本次发布的是第二代CodeGeeX模型,是6B版本。第一代模型20万一年的授权费。该模型授权费用尚未公布!但已经有申请地址:https://open.bigmodel.cn/mla/form
根据官方的描述,CodeGeeX2的主要特点和升级结果包括:
- 更强大的代码能力:CodeGeeX2是基于ChatGLM2模型微调得到,在原有模型基础上继续基于6000亿代码数据训练。相比第一代的版本在各个语言的表现上提升都很高。
- 更优秀的模型特性:支持中英文输入,最高8K上下文,推理速度提升很高,最低量化版本的模型只需要5.5GB显存即可运行
- 更好地生态和插件:官方提供了VSCode和Jetbrains两个平台的插件,支持超过100多种编程语言,生态更加完善
- 更开发的开源协议:CodeGeeX2-6B是完全开源的,代码开源协议Apache2.0,模型预训练结果学术研究免费,商用需要申请。
CodeGeeX2-6B评测结果
CodeGeeX2模型在编程效果上有很大的提升。根据官方的说明,即使是6B版本的CodeGeeX2-6B也有很强大的性能,评测结果甚至超过150亿参数规模的starcode(StarCode是BigCode开源的编程大模型:https://www.datalearner.com/ai-models/pretrained-models/StarCoder )。
下图是在HumanEval上的评测结果:
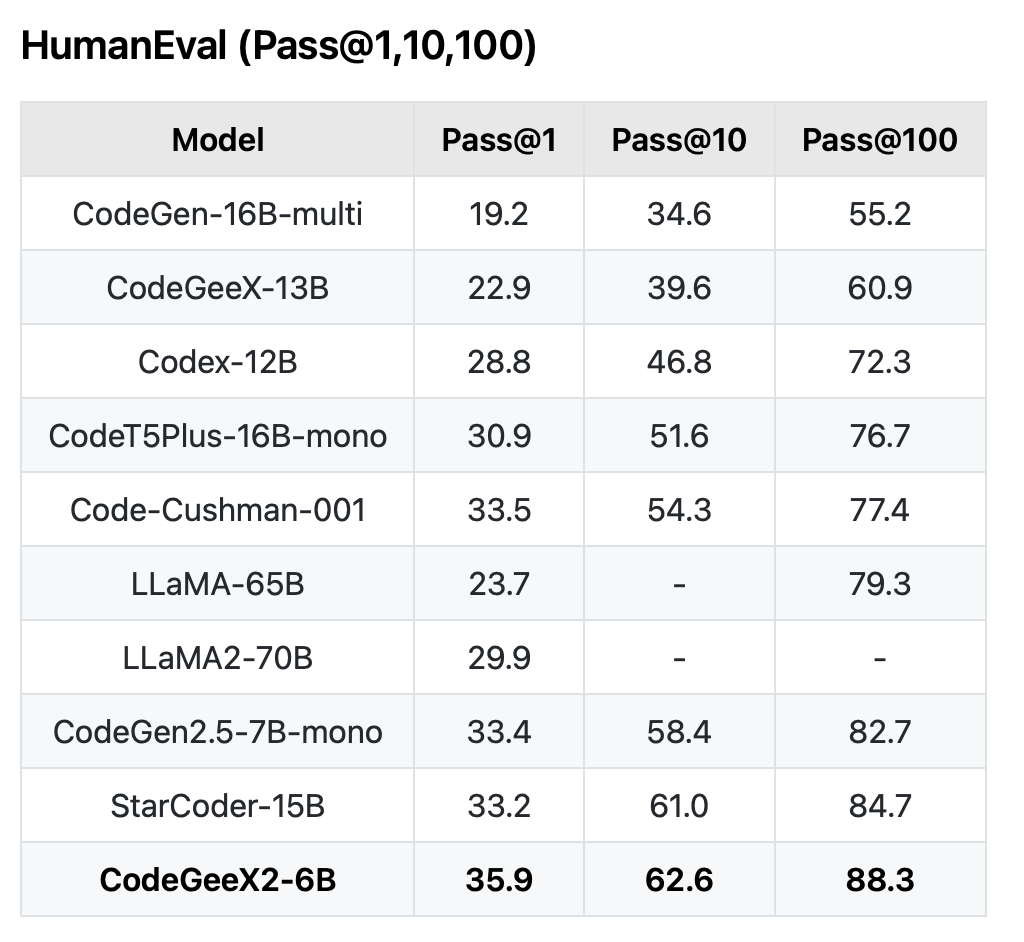
可以看到,其中CodeGeeX2-6B比第一代CodeGeeX-13B提升了13分(22.9到35.9分),排名第一,甚至超过了LLaMA2-70B的效果。
CodeGeeX2-6B与智源人工智能研究院AquilaCode-7B对比
这里提一下昨天智源人工智能研究院刚发布的AquilaCode-multi-7B模型,它的测试结果与CodeGeeX2对比如下:
| 模型 | Pass@ 1 | | ------------ | ------------ | ------------ | ------------ | | AquilaCode-7B-multi | 22.0 | | CodeGeeX2-6B | 28.1 |
可以看到,尽管昨天的AquilaCode表现也不错,但是依然不如清华大学这个CodeGeeX。而昨天发布的还有一个AquilaCode-py是智源人工智能研究院开源的针对Python优化的,对比结果如下:
| 模型 | Pass@ 1 | | ------------ | ------------ | ------------ | ------------ | | AquilaCode-7B-py | 28.8 | | CodeGeeX2-6B | 35.9 |
CodeGeeX0-6B也是要比AquilaCode稍微好点。
CodeGeeX2-6B的性能和资源需求
与ChatGLM2一样优秀的是CodeGeeX2-6B的效果很好的同时,也对资源的要求很低。目前最低的INT4量化仅需5.5GB显存即可运行,推理速度则是94个字符/秒。
推理速度如下:
| 模型 | 推理速度(字符/秒 )| | ------------ | ------------ | ------------ | ------------ | | CodeGeeX-13B | 32 | | CodeGeeX2-6B | 94 |
这么看,相比较第一代的CodeGeeX013B,第二代的CodeGeeX2-6B的参数规模降低了一般多,资源消耗也只有一半,但是性能却增加很多!
CodeGeeX2-6B的开源地址、预训练权重地址参考模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/CodeGeeX2-6B
