Embedding开源模型重磅玩家:北京智源人工智能研究院最新Embedding模型发布!登顶MTEB,免费商用授权!
3,904 views
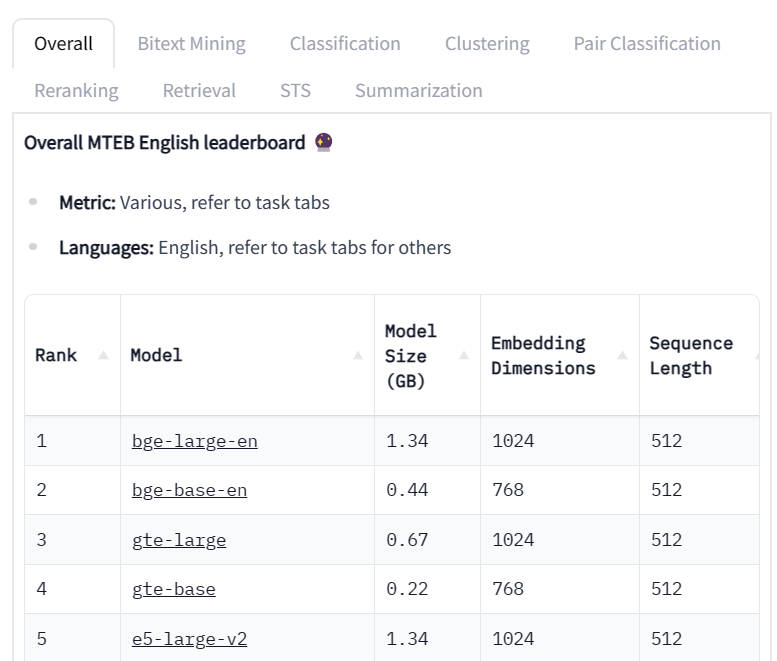
Embedding模型作为大语言模型(Large Language Model,LLM)的一个重要辅助,是很多LLM应用必不可少的部分。但是,现实中开源的Emebdding模型却很少。最近,北京智源人工智能研究院(BAAI)开源了BGE系列Embedding模型,不仅在MTEB排行榜中登顶冠军,还是免费商用授权的大模型,支持中文,应该可以满足相当多人的需要。