谷歌发布视频大模型Veo 3.1:电影级别的视频生成,声音合成和同步能力大幅提升,但相比较Sora2依然有明显差距!
就在今日,Google 正式推出 Veo 3.1 和 Veo 3.1 Fast,这两款升级版视频生成模型以付费预览形式登陆 Gemini API。Veo 3.1的核心亮点是:更丰富的原生音频(从自然对话到同步音效)、更强的电影风格理解与叙事控制、以及**显著增强的图生视频(Image-to-Video)**质量与一致性。

Google的Veo系列视频生成大模型简介以及问题
Veo 是 Google 的生成式视频模型系列,专注于从文本、图像或其他输入生成高品质视频内容。2024年5月份谷歌首次发布了Veo 1模型,用于挑战OpenAI的Sora系列。7个月后的2024年12月份,谷歌发布了Veo 2,提升状态艺术级的视频和图像生成,可以和Imagen3结合,同时在物理模拟和风格一致性上有了不小的改进。
2025年5月份,谷歌推出了Veo 3,定位为电影级文本到视频与图像到视频的创作引擎:它强调镜头语言理解(景别、机位、运动、光影)、原生音频合成(对白与声效同步)、以及角色/风格一致性控制等能力。支持多人物互动和复杂场景。同时推出了Flow工具,也就是Google 的 AI 电影制作工具,半年后的今天,全球用户已经在Flow中生成了2.75亿个视频。
2025年,10月15日,谷歌发布了Veo 3.1,用以改进前代模型的问题。
Veo的关键里程碑总结如下:
Google Veo 3.1的核心特点
尽管Veo 3的用户很多,但是该版本仍面临一些痛点:音频生成往往局限于简单背景音,缺乏真实对话的自然流畅;叙事控制也难以精准捕捉导演意图,导致角色在多场景切换时出现不一致。更别提从图像起步的视频创作,经常因提示词偏差而产生视觉 artifact,浪费宝贵计算资源。这些不足在高强度生产环境中尤为突出,尤其当开发者需要快速迭代长篇故事时,Veo 3 的 8 秒上限和有限的风格适应性常常成为瓶颈。
本次谷歌发布的Veo 3.1是Veo 3的小幅改进版本,进一步加强了叙事控制与图生视频贴合度,并新增参考图引导、镜头延展、首末帧过桥三大控件,用于把“灵感片段”拼接成更可交付的成片。
Veo 3.1继承了 Veo 3 的核心架构,但在模型训练数据上进行了大规模优化,融入了更多高质量的电影级视频样本——据估算,训练数据集规模较前代扩展了 至少 50%,这直接提升了模型对复杂提示的理解深度。
Veo 3.1最大的特点是无缝构建连贯的叙事链条。举个例子,过去生成一个科幻短片的音频可能听起来像机器人朗读,而现在,Veo 3.1 能模拟出紧张的背景配乐与人物低语交织,宛如专业后期制作。这不仅仅是技术迭代,更是向全景视听创作的跃进,帮助无数创作者从“技术障碍”中解放出来,专注于故事本身。具体特点总结如下:
- 丰富的原生音频生成:首次在“Ingredients to Video”、“Frames to Video”和“Extend”等功能中集成音频,支持自然对话(多人物互动)、音效(e.g., 轮胎尖叫)和环境噪音(e.g., 远处雷鸣)。音频与视频同步,无需后期处理。改进后,音频质量更逼真,尤其在对话和 SFX 上,但不支持自定义语音选择。
- 增强的叙事控制:模型对故事结构、电影风格和角色互动有更深理解。支持多参考图像(最多 3 张)保持角色/物体一致性(如人物从不同角度保持面部特征)。提示遵守更强,减少无效生成。
- 真实主义提升:捕捉真实纹理(如皮肤、布料)、物理模拟(如影子、光照)和复杂场景(如雾气峡谷)。图像到视频转换的视听质量大幅提升。
- 编辑工具集成:
- Insert:在任意场景添加元素(如奇幻生物),自动调整影子和光照。
- Remove:无缝移除物体/人物,重构背景(即将上线)。
- Ingredients to Video:结合多图像生成一致场景。
- First and Last Frame:从起始/结束图像生成平滑过渡,支持 180 度弧形镜头。
- Scene Extension:基于前一剪辑的最后一秒扩展视频,实现 1 分钟+ 长片。
- 其他:支持电影术语(如“dolly shot”、“shallow depth of field”)和情绪氛围(如“忧郁蓝调”)。生成过程异步,延迟 11 秒至 6 分钟。
与 Veo 3 相比,Veo 3.1 在提示遵守(减少计算浪费)、视听质量(尤其是图像动画)和音频支持上提升 20-30%(基于用户反馈)。但早期测试显示,它更“电影化”和“人工感”。
本次Veo 3.1还有一个Fast版本,即Veo 3.1 Fast,它的视频生成速度很快,适合快速原型,但输出质量略低于标准版。
Veo 3.1实测:与Sora2依然有明显差距
虽然Veo 3.1在视频生成的质量、连贯性、物理世界理解、配音等方面有明显提升,但根据当前大家的测试,OpenAI的Sora 2在多个方面依然明显优于Veo 3.1。
Sora 2 在微观写实、光影与物理细节上更常被认可,Veo 3.1则经常出现与物理世界不符的情况,此外,配音方面也有许多测试显示Sora 2的音频更加自然。
例如,kongmindset做了一个大猩猩和猴子合唱的视频,Veo 3.1输出的视频动物表情丰富,合唱节奏感强,背景丛林细节出色,但动作略显卡顿。但是Sora2视频包含更狂野的互动,猴子跳跃物理真实,但声音同步稍弱。


另一个用户Matt测试了一群人在沙滩上打排球,Veo 3.1输出(左):球员动作一致,沙滩纹理细腻,但跳跃高度不准,球轨迹略假。Sora 2输出(右):物理碰撞真实,汗水和沙尘效果出色,整体更活力四射。
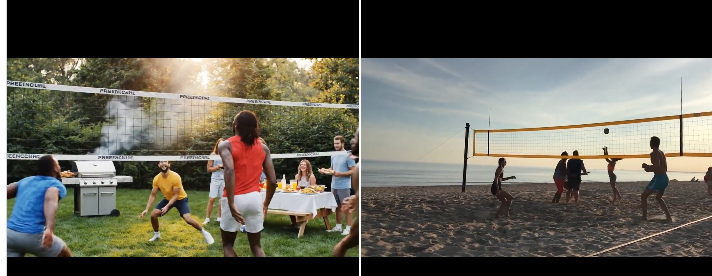
其它还有很多案例,都是类似。总之,Veo 3.1最大的问题还是物理世界的理解比较差,不太真实。
我们也总结一下Veo 3.1和Sora2的对比:
Veo 3.1总结
目前,大家已经可以在Gemini API / Vertex AI / Gemini 应用 / Flow上面使用Veo 3.1了,都是付费才可以使用。
接口价格方面,Veo 3.1 标准版是0.4美元/秒,而对比一下Sora2是0.1美元/秒,Sora2-pro是0.3美元/秒,似乎吸引力也是一般般。
关于Veo 3.1更多信息参考DataLearnerAI模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/veo-3-1-generate-preview
