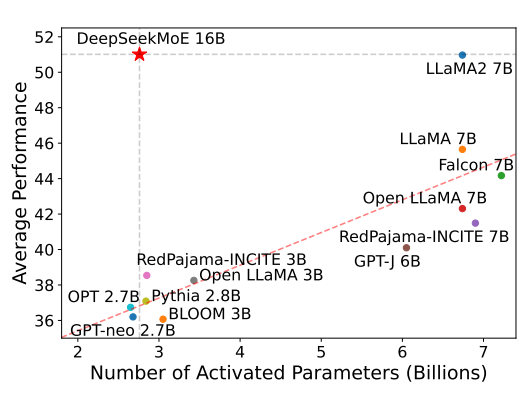
DeepSeekAI开源国产第一个基于混合专家技术的大模型:DeepSeekMoE-16B,未来还有1450亿参数的MoE大模型
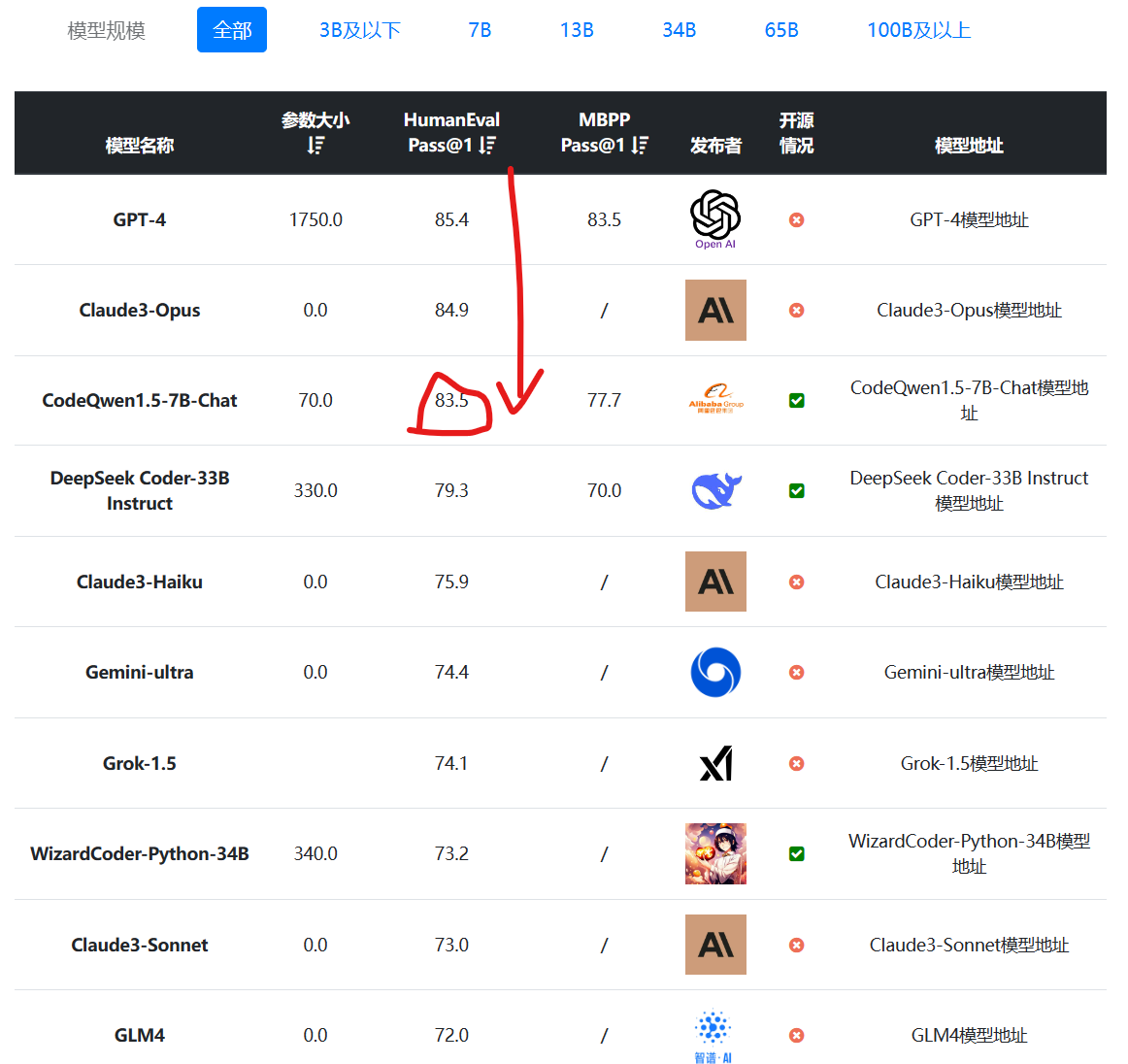
混合专家(Mixture of Experts)是大模型一种技术,这个技术将大模型划分为不同的子专家模型,每次推理只选择部分专家网络进行推理,在降低成本的同时保证模型的效果。此前Mistral开源的Mixtral-8×7B-MoE大模型被证明效果很好,推理速度很棒。而幻方量化旗下的DeepSeek刚刚开源了可能是国产第一个MoE技术的大模型,DeepSeek-MoE 16B。