Original AI Tech Blogs
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.


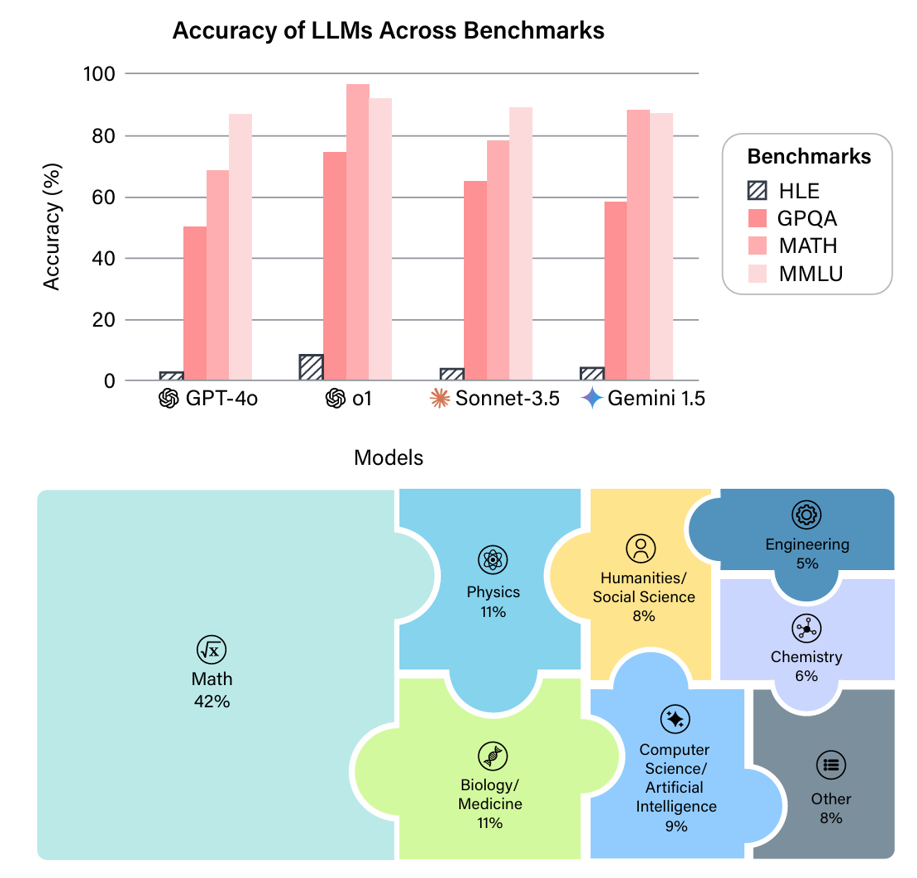
大模型评测的新标杆:超高难度的“Humanity’s Last Exam”(HLE)介绍
近年来,大语言模型(LLM)的能力飞速提升,但评测基准的发展却显得滞后。以广泛使用的MMLU(大规模多任务语言理解)为例,GPT-4、Claude等前沿模型已能在其90%以上的问题上取得高分。这种“评测饱和”现象导致研究者难以精准衡量模型在尖端知识领域的真实能力。为此,Safety for AI和Scale AI的研究人员推出了Humanity’s Last Exam大模型评测基准。这是一个全新的评测基准,旨在成为大模型“闭卷学术评测的终极考验”。
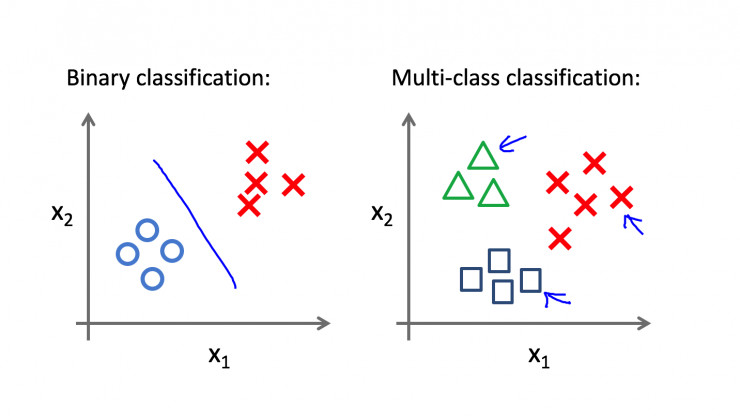
通过从零开始实现一个感知机模型,我学到了这些【转载】
本文转自雷锋网,原文《通过从零开始实现一个感知机模型,我学到了这些》,作者:恒亮,文章转载已获授权。感知器(英语:Perceptron)是Frank Rosenblatt在1957年就职于Cornell航空实验室(Cornell Aeronautical Laboratory)时所发明的一种人工神经网络。它可以被视为一种最简单形式的前馈神经网络,是一种二元线性分类器。本文介绍了搭建感知机模型的基本操作也包含了作者的一些心得。
国产开源中文大语言模型再添重磅玩家:清华大学NLP实验室发布开源可商用大语言模型CPM-Bee
5月27日,OpenBMB发布了一个最高有100亿参数规模的开源大语言模型CPM-BEE,OpenBMB是清华大学NLP实验室联合智源研究院成立的一个开源组织。该模型针对高质量中文数据集做了训练优化,支持中英文。根据官方的测试结果,其英文测试水平约等于LLaMA-13B,中文评测结果优秀。
MySQL8授权用户远程连接失败,提示ERROR 1410 (42000): You are not allowed to create a user with GRANT
原来直接用root账户授权远程访问失败,最新的MySQL8不允许直接创建并授权用户远程访问权限,必须先让自己有GRANT权限,然后创建用户,再授权。

GPT-5 模式与配额全解析:自动与手动 Thinking 的区别、不同用户的使用配额问题等
GPT-5 在 ChatGPT 中引入了“自动在普通/推理间切换”的机制,但模式命名、配额规则和速率限制让许多用户困惑。本文梳理不同模式的作用、是否计入推理配额、各订阅层的可用性与限制、旧模型的替换规则,并提供三步配额优化策略。特别提示:编码与大上下文任务应优先使用 GPT-5 Thinking(≈196k 上下文),而普通 Chat 模式上下文为 32k。
Java读取和操作上G文本数据
在处理文本时,经常遇到超过1g存储的数据,直接简单的读取,可能遇到java空间不足的问题,为解决此问题,可将大文本数据按照行进行切分为很多块,并将每一块存储为一个文本

线性数据结构之跳跃列表(Skip List)详解及其Java实现
数据结构中,自平衡二叉查找树搜索效率高,但是需要通过旋转和变色维护平衡。而列表虽然简单,但是对元素的查找需要比对列表中的每个元素,查找速度较慢。为了兼顾列表的简单易用,并提高查找效率,跳跃列表(Skip List)应运而生。

不同参数规模大语言模型在不同微调方法下所需要的显存总结
大模型的微调是当前很多人都在做的事情。微调可以让大语言模型适应特定领域的任务,识别特定的指令等。但是大模型的微调需要的显存较高,而且比较难以估计。与推理不同,微调过程微调方法的选择以及输入序列的长度、批次大小都会影响微调显存的需求。本文根据LLaMA Factory的数据总结一下大模型微调的显存要求。

CentOS搭建SVN服务器及使用Eclipse连接SVN服务器
SVN是Subversion的简称,是一个开放源代码的版本控制系统,相较于RCS、CVS,它采用了分支管理系统,它的设计目标就是取代CVS。互联网上很多版本控制服务已从CVS迁移到Subversion。说得简单一点SVN就是用于多个人共同开发同一个项目,共用资源的目的。
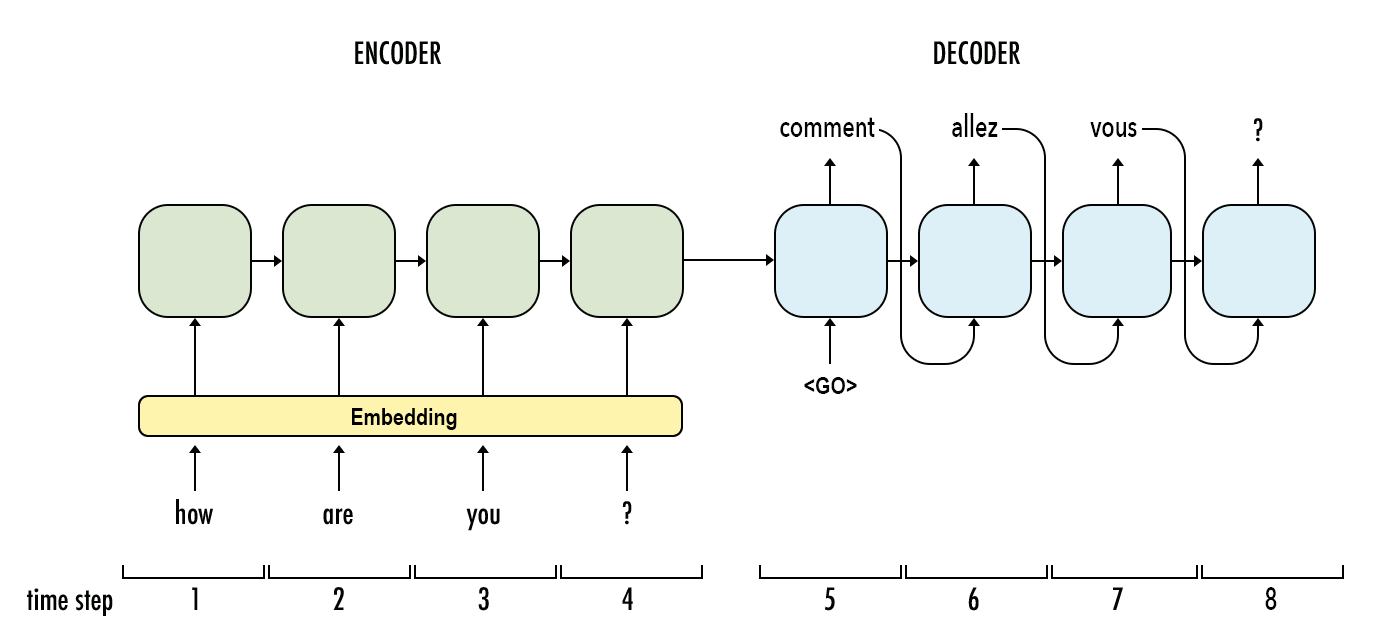
大语言模型的技术总结系列一:RNN与Transformer架构的区别以及为什么Transformer更好
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
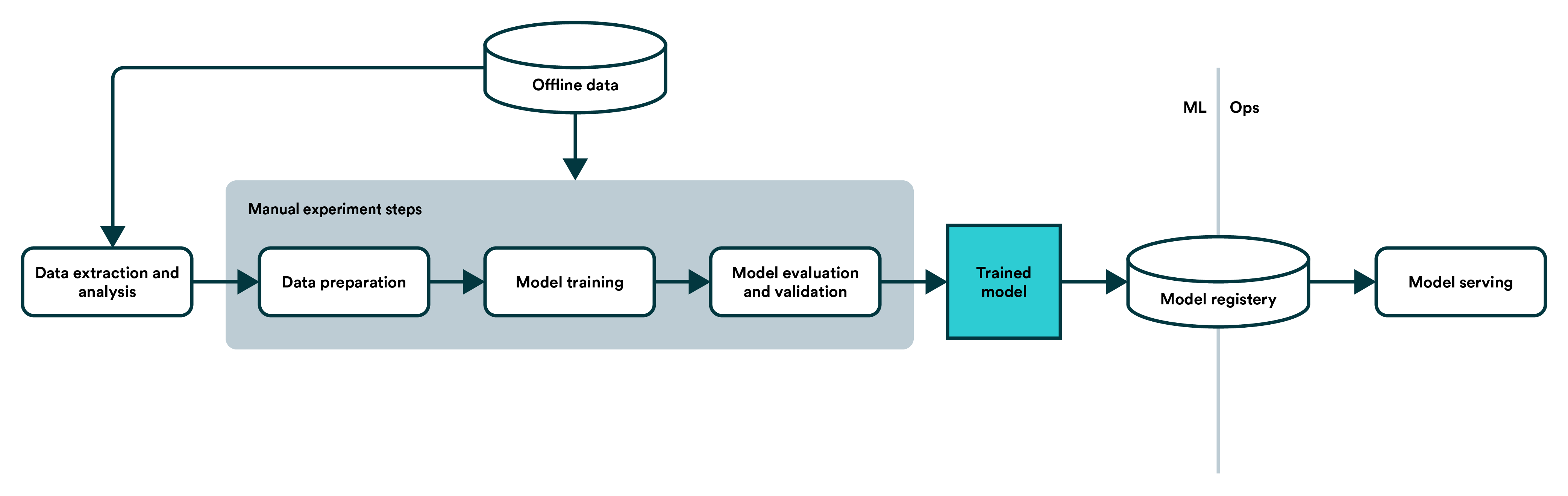
AI系统中(机器学习算法)导致偏差的原因总结
基于算法的业务或者说AI的应用在这几年发展的很快。但是,在实际应用的场景中,我们经常会遇到一些非常奇怪的偏差现象。例如,Facebook将黑人标记为灵长类动物、城市图像识别系统将公交车上的董明珠形象广告识别为闯红灯的人等。算法系统出现偏差的原因有很多。本篇博客将总结在数据获取相关方面可能导致模型出现偏差的原因。
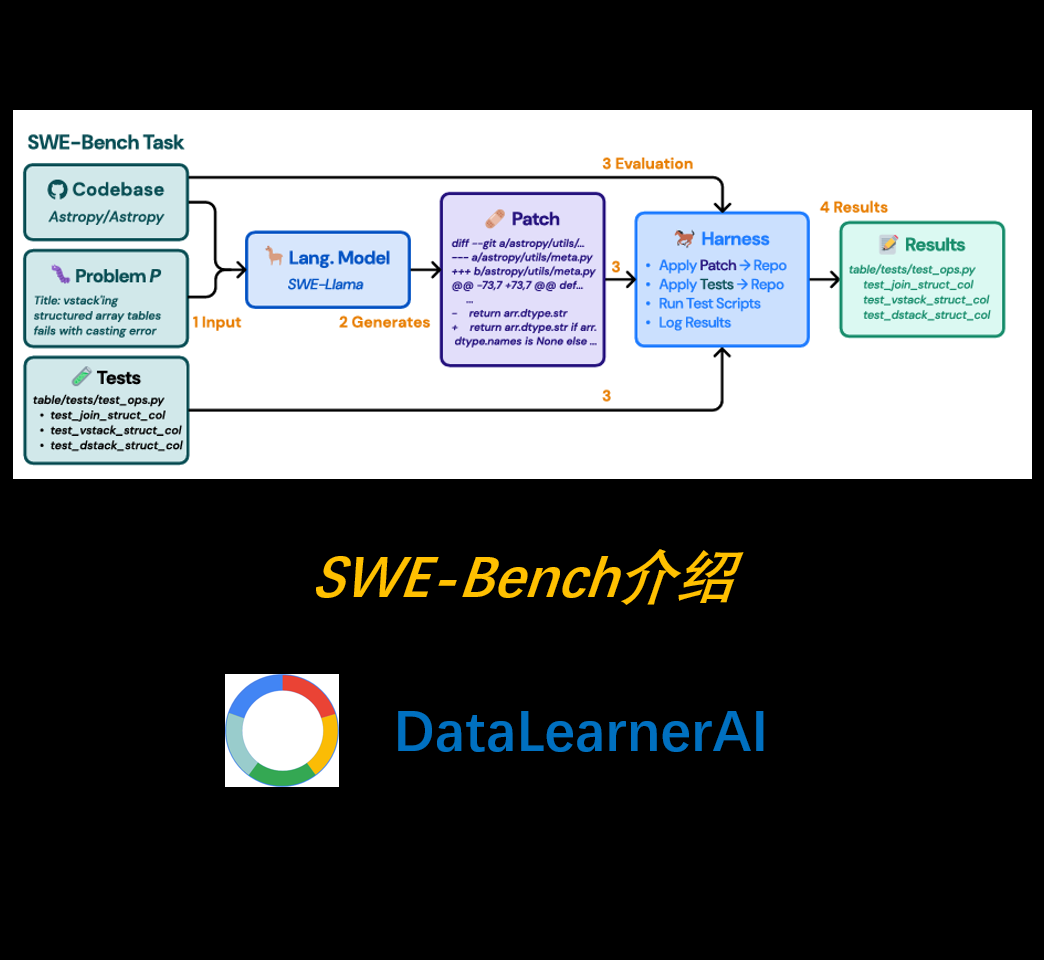
SWE-bench大模型评测基准介绍:测试大模型在真实软件工程任务中的能力
随着大语言模型(LLM)的快速发展,它们在自然语言处理(NLP)、代码生成等领域的表现已达到前所未有的高度。然而,现有的代码评测基准(如 HumanEval)通常侧重于**自包含的、较短的代码生成任务**,而未能充分模拟真实世界的软件开发环境。为弥补这一空白,研究者提出了一种全新的评测基准——**SWE-Bench**,旨在测试 LLM 在**真实软件工程问题**中的能力。


全球最大(最挣钱)的十大开源企业
自从Hadoop生态发展以来,基于开源软件提供服务的盈利公司也越来越多。大家这才发现,开源不仅不会削弱企业竞争力,还可以带来生态,增强企业的竞争力。本文总结全球最挣钱的十大开源公司供大家参考。