
Scale AI 发布 SWE-Bench Pro 评测:AI 软件工程代理的新基准
Scale AI 于 2025 年 9 月 21 日发布了 SWE-Bench Pro,这是一个针对 AI 代理在软件工程任务上的评估基准。该基准包含 1,865 个问题,来源于 41 个活跃维护的代码仓库,聚焦企业级复杂任务。现有模型在该基准上的表现显示出显著差距,顶级模型的通过率低于 25%,而最近的榜单更新显示部分模型已超过 40%。这一发布旨在推动 AI 在长时程软件开发中的应用研究。
A curated list of original AI and LLM articles related to "大模型编程能力", updated regularly.
Scale AI 于 2025 年 9 月 21 日发布了 SWE-Bench Pro,这是一个针对 AI 代理在软件工程任务上的评估基准。该基准包含 1,865 个问题,来源于 41 个活跃维护的代码仓库,聚焦企业级复杂任务。现有模型在该基准上的表现显示出显著差距,顶级模型的通过率低于 25%,而最近的榜单更新显示部分模型已超过 40%。这一发布旨在推动 AI 在长时程软件开发中的应用研究。

Aider 是一个在终端里进行结对编程的开源工具。为评估不同大模型在“按照指令对代码进行实际可落地的编辑”上的能力,Aider 提出并维护了公开基准与排行榜,用于比较模型在无人工干预下完成代码修改任务的可靠性与成功率。该评测已被多家模型提供方在技术说明中引用,用作代码编辑与指令遵循能力的对照指标。
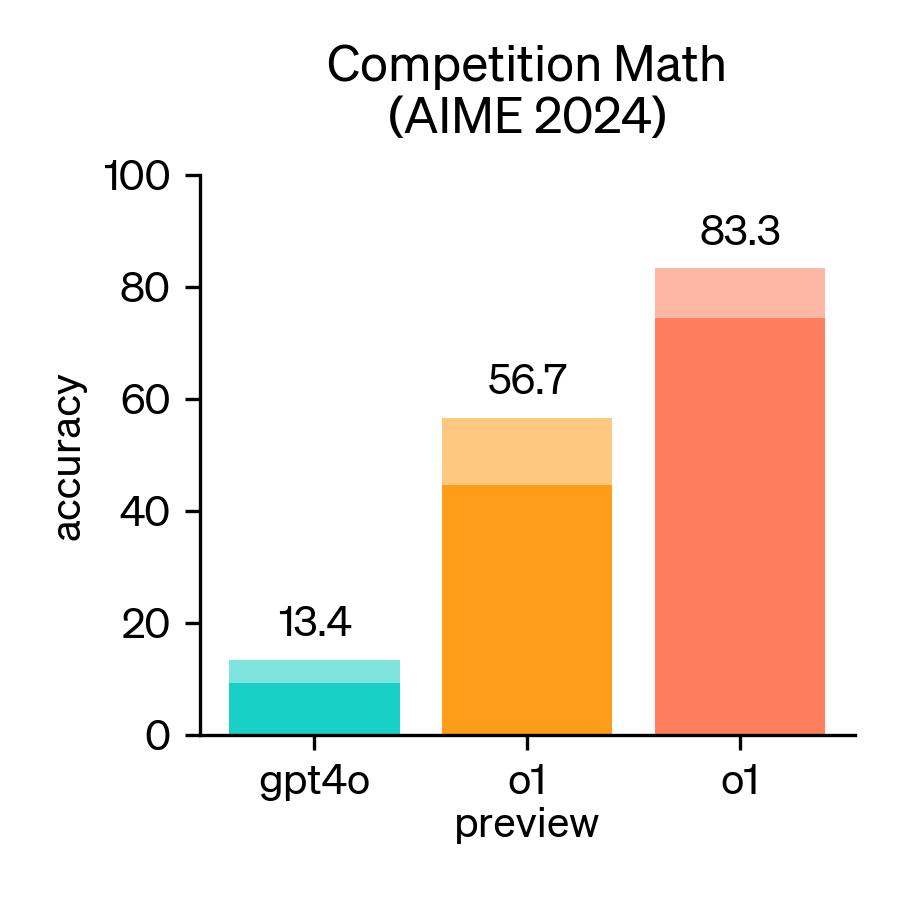
2024年,美国数学邀请赛(AIME)成为评估大型语言模型(LLM)数学推理能力的重要基准。AIME是一项备受尊崇的考试,包含15道题,考试时间为3小时,旨在考察美国顶尖高中生在各类数学领域的复杂问题解决能力。
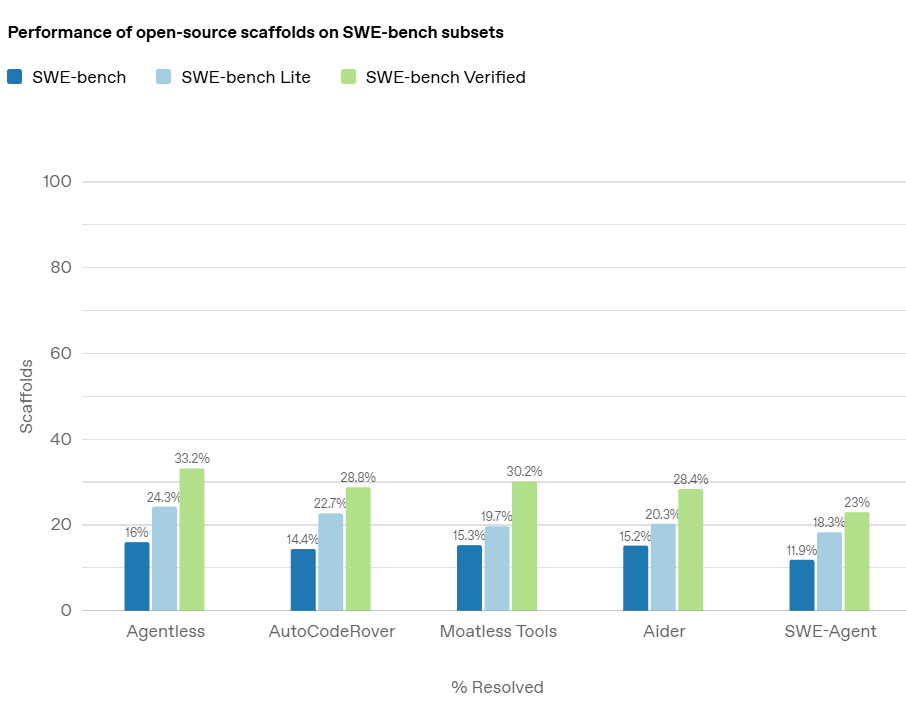
在人工智能领域,随着大型语言模型(LLMs)在各类任务中的表现不断提升,评估这些模型的实际能力变得尤为重要。尤其是在软件工程领域,AI 模型是否能够准确地解决真实的编程问题,是衡量其真正应用潜力的关键。而在这方面,OpenAI 推出的 *SWE-bench Verified* 基准测试,旨在提供一个更加可靠和精确的评估工具,帮助开发者和研究者全面了解 AI 模型在处理软件工程任务时的能力。
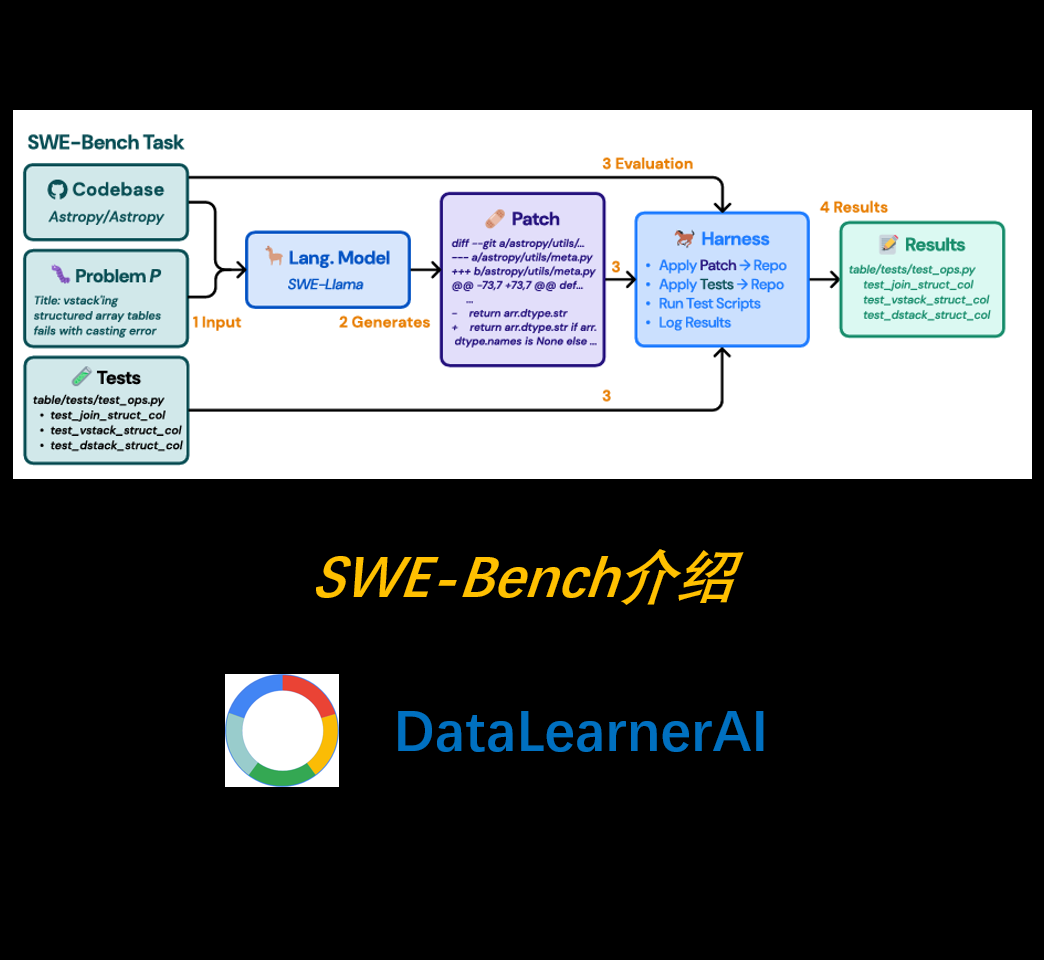
随着大语言模型(LLM)的快速发展,它们在自然语言处理(NLP)、代码生成等领域的表现已达到前所未有的高度。然而,现有的代码评测基准(如 HumanEval)通常侧重于**自包含的、较短的代码生成任务**,而未能充分模拟真实世界的软件开发环境。为弥补这一空白,研究者提出了一种全新的评测基准——**SWE-Bench**,旨在测试 LLM 在**真实软件工程问题**中的能力。
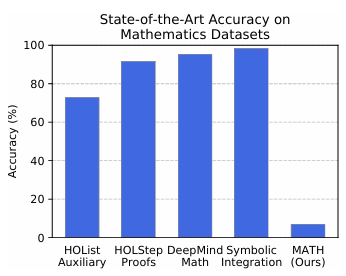
在评估大型语言模型(LLM)的数学推理能力时,MATH和MATH-500是两个备受关注的基准测试。尽管它们都旨在衡量模型的数学解题能力,但在发布者、发布目的、评测目标和对比结果等方面存在显著差异。