
在 API 和 ChatGPT 之间迷路?GPT-5.1、GPT-5.1-Chat、GPT-5.1 Instant 的真正区别解释(DataLearnerAI)
2025/11/15 15:20:47347
Explore the latest AI and LLM news and technical articles, covering original content and practical cases in machine learning, deep learning, and natural language processing.

11 月 13 日,SimilarWeb 发布了最新的 GenAI 访问流量分布。从数据走势可以明显看到,大模型行业正在经历从“ChatGPT 绝对统治”向“多极竞争”的结构性转变。 一年前,ChatGPT 占据了超过 86% 的流量份额,整个行业几乎处于单中心状态。然而在过去的 12 个月里,大模型的多样化发展、不同厂商的产品升级、企业用户需求变化,都推动了新一轮的流量重分配。

2025 年 11 月 13 日,OpenAI 团队在 Reddit 上进行了一场针对 GPT-5.1、模型自定义能力、开发者 API、未来路线图 的公开 AMA(Ask Me Anything)。这次交流并不是简单的功能答疑,而是罕见地从内部视角解释了他们如何思考安全策略、模型行为塑形、推理模式优化、人格定制逻辑、多模态进展以及实际工程实现细节。

OpenAI 于 2025 年 11 月正式发布 GPT-5 系列的阶段性更新版本 —— GPT-5.1。这一更新并非针对模型架构的全面重做,而是围绕“对话体验、一致性、任务适配性”进行的系统化优化。在 GPT-5 推出后,业界对其不稳定回复、语气波动、任务深度控制不足等表现提出了不少批评,因此本次更新可视为 OpenAI 对这些问题的集中调整。
IMO-Bench 是 Google DeepMind 开发的一套基准测试套件,针对国际数学奥林匹克(IMO)水平的数学问题设计,用于评估大型语言模型在数学推理方面的能力。该基准包括三个子基准:AnswerBench、ProofBench 和 GradingBench,涵盖从短答案验证到完整证明生成和评分的全过程。发布于 2025 年 11 月,该基准通过专家审核的问题集,帮助模型实现 IMO 金牌级别的性能,并提供自动评分机制以支持大规模评估。

LiveBench是一个针对大型语言模型(LLM)的基准测试框架。该框架通过每月更新基于近期来源的问题集来评估模型性能。问题集涵盖数学、编码、推理、语言理解、指令遵循和数据分析等类别。LiveBench采用自动评分机制,确保评估基于客观事实而非主观判断。基准测试的总问题数量约为1000个,每月替换约1/6的问题,以维持测试的有效性。
BrowseComp是一个用于评估AI代理网页浏览能力的基准测试。它包含1266个问题,这些问题要求代理在互联网上导航以查找难以发现的信息。该基准关注代理在处理多跳事实和纠缠信息时的持久性和创造性。OpenAI于2025年4月10日发布此基准,并将其开源在GitHub仓库中。
就在今日,Moonshot AI 正式推出 Kimi K2 Thinking,这款开源思考代理模型以其革命性的工具集成和长程推理能力,瞬间点燃了开发者社区的热情。Kimi K2能自主执行200-300次连续工具调用,跨越数百步推理,解决PhD级数学难题或实时网络谜题。本次发布的Kimi K2不仅仅是模型升级,更是AI Agent能力的扩展。

让AI Agent通过编写代码来调用工具,而不是直接工具调用。这种方法利用了MCP(Model Context Protocol,模型上下文协议)标准,能显著降低token消耗,同时保持系统的可扩展性。下面,我结合原文的逻辑,分享我的理解和改写版本,目的是记录这个洞察,并为后续实验提供参考。Anthropic作为领先的AI研究机构,于2024年11月推出了MCP,这是一个开放标准,旨在简化AI Agent与外部工具和数据的连接,避免传统自定义集成的碎片化问题。
MiniMax M2发布2周后已经成为OpenRouter上模型tokens使用最多的模型之一。已经成为另一个DeepSeek现象的大模型了。然而,实际使用中,很多人反馈说模型效果并不好。而此时,官方也下场了,说当前大家使用MiniMax M2效果不好的一个很重要的原因是没有正确使用Interleaved Thinking。正确使用Interleaved thinking模式,可以让MiniMax M2模型的效果最多可以提升35%!本文我们主要简单聊聊这个Interleaved thinking。
IFBench 是一个针对大语言模型(LLM)指令跟随能力的评测基准。该基准聚焦于模型对新颖、复杂约束的泛化表现,通过 58 个可验证的单轮任务进行评估。发布于 2025 年 7 月,该基准旨在揭示模型在未见指令下的精确执行水平。目前,主流模型在该基准上的得分普遍低于 50%,显示出指令跟随的潜在局限。

MiniMax正式开源MiniMax M2模型,该模型定位是“Mini 模型,Max 编码与代理工作流”。最大的特点是2300亿总参数量,但是每次推理仅激活100亿,类似于10B模型。这款模型非常火爆,原因在于这么小的激活参数数量,推理速度很快,但是其评测结果非常优秀。

在AI时代,Hugging Face Hub已成为开源大语言模型(LLM)和预训练模型的宝库。从Qwen到DeepSeek系列,这些模型往往体积庞大(几GB甚至上百GB),下载过程容易受网络波动影响,导致中断、重试或失败。作为一名AI从业者,你可能不止一次遇到过“下载到99%就崩”的尴尬。本文将从客观角度,基于实际使用经验,介绍四种常见下载Hugging Face大模型的方法:从基础的Git克隆,到CLI工具、Transformers库,再到国内镜像加速。每种方法都有其适用场景和优缺点,我们将逐一剖析,帮

就在今日,阿里巴巴Qwen团队重磅推出Qwen3-VL-2B和Qwen3-VL-32B两款视觉语言模型,这些dense架构的创新之作,将多模态AI的强大能力压缩进更紧凑的框架中,显著降低了部署门槛。 作为Qwen3系列的最新扩展,它们在保持顶级性能的同时,支持从边缘设备到云端的无缝应用——想象一下,一款手机App就能实时分析2小时视频,或从模糊手写笔记中提取精确信息。这不仅仅是参数缩减,更是AI普惠化的关键一步,帮助开发者以更低的成本实现视觉智能的突破。

Scale AI 于 2025 年 9 月 21 日发布了 SWE-Bench Pro,这是一个针对 AI 代理在软件工程任务上的评估基准。该基准包含 1,865 个问题,来源于 41 个活跃维护的代码仓库,聚焦企业级复杂任务。现有模型在该基准上的表现显示出显著差距,顶级模型的通过率低于 25%,而最近的榜单更新显示部分模型已超过 40%。这一发布旨在推动 AI 在长时程软件开发中的应用研究。

DeepSeek AI团队重磅推出DeepSeek-OCR,该模型不仅在文档提取上达到了行业领先水平,更通过创新的视觉压缩技术,将长上下文处理效率提升了 10 倍以上。根据测算,在A100-40G的一个GPU上,它每天可以将20万页的文档图像数据转为Markdown文本!

Anthropic正式发布最新一代入门级模型Claude Haiku 4.5。相较上一代小模型,Haiku 4.5 在编码、推理与“计算机使用/子代理编排”等关键生产力场景上实现逼近甚至局部追平 Sonnet 4,但价格更低、速度更快,定位于“面向规模化落地的高性价比主力”。
DocVQA是一个针对文档图像的视觉问答基准数据集。该数据集包含50,000个问题,这些问题基于12,767张文档图像构建而成。数据集旨在评估模型在提取和理解文档内容方面的能力,特别是当问题涉及布局、表格和文本时。基准通过提供标注的问答对,支持模型在真实文档场景下的测试。
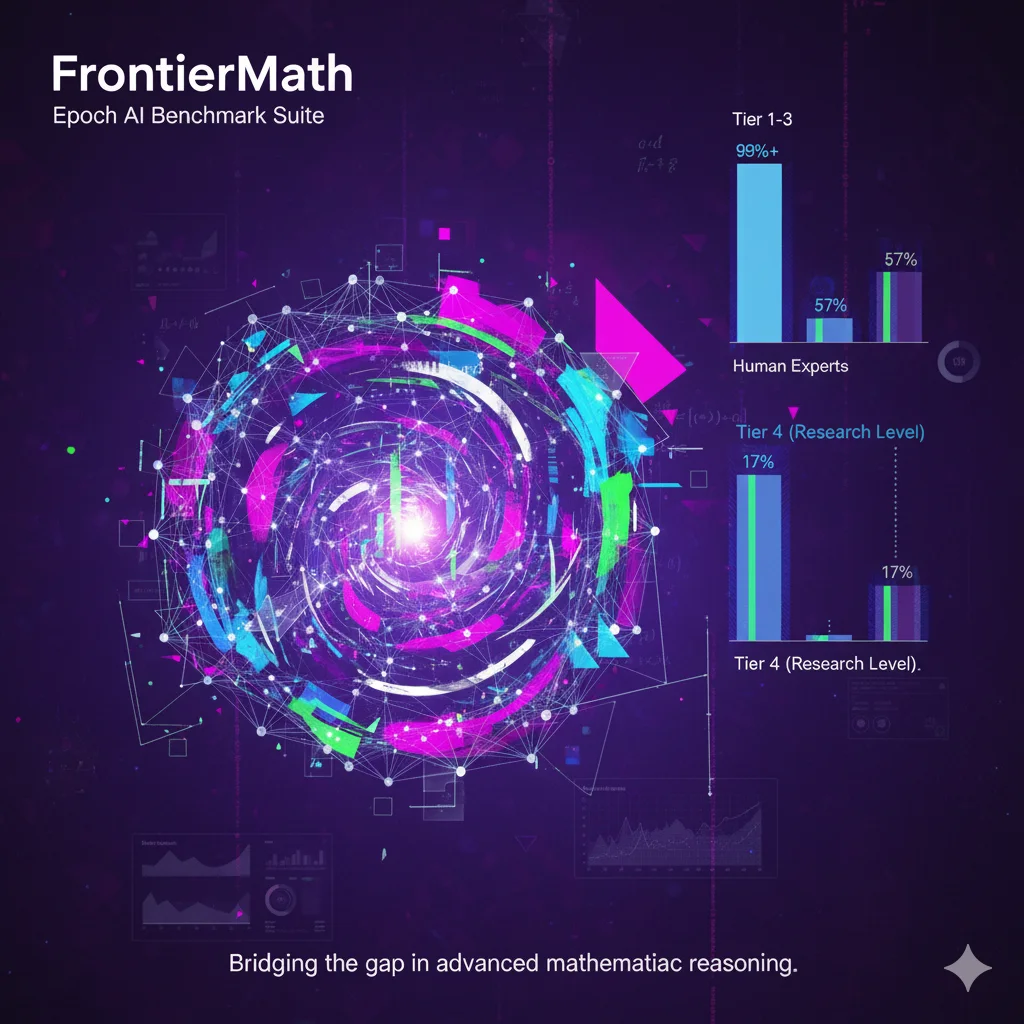
FrontierMath是一个由Epoch AI开发的基准测试套件,包含数百个原创的数学问题。这些问题由专家数学家设计和审核,覆盖现代数学的主要分支,如数论、实分析、代数几何和范畴论。每个问题通常需要相关领域研究人员投入数小时至数天的努力来解决。基准采用未发表的问题和自动化验证机制,以减少数据污染风险并确保评估可靠性。当前最先进的AI模型在该基准上的解决率低于2%,这反映出AI在处理专家级数学推理时的局限性。该基准旨在为AI系统向研究级数学能力进步提供量化指标。

Anthropic 正式推出全新功能 Claude Skills,旨在让通用 AI 代理(Agent)具备专业领域能力。该功能允许用户通过创建包含 SKILL.md 文件的技能文件夹,为 Claude 注入可执行脚本、模板与资源,实现 Excel 处理、PPT 生成等特定任务的自动化操作。与传统提示词不同,Skills 采用结构化加载与本地沙箱执行机制,兼顾安全性与效率。

就在今日,Google 正式推出 Veo 3.1 和 Veo 3.1 Fast,这两款升级版视频生成模型以付费预览形式登陆 Gemini API。Veo 3.1的核心亮点是:更丰富的原生音频(从自然对话到同步音效)、更强的电影风格理解与叙事控制、以及显著增强的图生视频(Image-to-Video)质量与一致性。

就在刚才,阿里云Qwen团队推出了两个多模态理解大模型Qwen3-VL-4B和Qwen3-VL-8B,本次发布的模型是较小参数规模的模型,可以用于消费级硬件(手机/PC)等,且都是稠密架构。

为了解决大模型的Agent操作依赖交互和人工处理这个问题,普林斯顿大学与 Sierra Research 的研究团队在 2025 年 6 月提出了 τ²-Bench(Tau-Squared Benchmark),并发布了论文《τ²-Bench: Evaluating Conversational Agents in a Dual-Control Environment》。 它是对早期 τ-Bench 的扩展版本,旨在建立一种标准化方法,评估智能体在与用户共同作用于环境时的表现。

就在昨天,2025年10月7日,Google DeepMind 正式发布其最新模型——Gemini 2.5 Computer Use。该模型基于 Gemini 2.5 Pro 的视觉理解与推理能力,新增了“界面交互(UI 控制)”能力,能够在浏览器或移动端界面上像人类那样点击、输入、滚动、选择控件等操作。